und Wörterbuch
des Klassischen Maya


Ein digitaler Zeichenkatalog der Mayaschrift
Working Paper 5
1. August 2025
DOI: http://dx.doi.org/10.20376/IDIOM-23665556.25.WP005.de
Christian Prager, Elisabeth Wagner, Guido Krempel, Tobias Mercer, und Nikolai Grube
(Rheinische Friedrich-Wilhelms-Universität, Bonn)
Lebende Datenbasis
Die diesem Dokument zugrunde liegende Datenbank ist Teil einer kontinuierlich weiterentwickelten Forschungsinfrastruktur. Sie spiegelt den aktuellen Stand eines aktiven Analyseprozesses wider und wird täglich durch neue Einträge ergänzt sowie bestehende Daten im Lichte fortlaufender Forschung überprüft und angepasst. Das Korpus wird somit laufend erweitert und präzisiert. Die hier präsentierten Inhalte stellen vorläufige, zugleich jedoch methodisch kontrollierte Momentaufnahmen des jeweiligen Kenntnisstands dar. In den kommenden Monaten wird die Datenbank zudem um erweiterte Funktionalitäten – insbesondere differenzierte Filter-, Such- und Abfragemöglichkeiten – ergänzt, um eine vertiefte analytische Auseinandersetzung sowie eine gesteigerte wissenschaftliche Nutzbarkeit und Zugänglichkeit zu gewährleisten.
Einleitung
Die systematische Klassifikation und Katalogisierung der Maya-Hieroglyphen gehört zu den anspruchsvollsten Aufgaben der Epigraphik. Die große Zeichenvielfalt, ihre zahlreichen Varianten und die nur teilweise entschlüsselte Bedeutung erschweren eine konsistente Analyse und Dokumentation. Frühere Ansätze, insbesondere der Zeichenkatalog von J. Eric S. Thompson (1962), bilden zwar eine wichtige Grundlage, zeigen jedoch methodische Schwächen und Inkonsistenzen. Das Projekt "Textdatenbank und Wörterbuch des Klassischen Maya" nutzt aktuelle Entwicklungen in den Digital Humanities und kombiniert sie mit korpuslinguistischen Methoden. Ziel ist eine präzisere und dynamisch erweiterbare Katalogisierung der Maya-Schrift. Hierbei wird auf Thompsons System aufgebaut, dieses jedoch umfassend überarbeitet: Fehlklassifikationen werden korrigiert, das Zeicheninventar erweitert und um neue Funde ergänzt. Der Beitrag stellt nicht nur das neue Online-Portal zur Maya-Schrift vor, sondern beleuchtet die zentralen Herausforderungen der Klassifikation, etwa die Vielfalt der Varianten, methodische Inkonsistenzen und technologische Begrenzungen früherer Systeme. Gleichzeitig zeigt er auf, wie moderne digitale Ansätze diese Probleme überwinden und einen nachhaltigen Beitrag zur Weiterentwicklung der Maya-Epigraphik leisten.
Seit 2014 widmet sich das Projekt "Textdatenbank und Wörterbuch des Klassischen Maya" (TWKM) der digitalen Erschließung sämtlicher bekannter Maya-Inschriften (Prager et al. 2024). Im Zentrum steht die Verbindung korpuslinguistischer mit Methoden der digitalen Geisteswissenschaften, um die klassische Maya-Schriftsprache in ihrer Originalform systematisch zu analysieren und zu dokumentieren. Das Projekt, angesiedelt an der Nordrhein-Westfälischen Akademie der Wissenschaften und der Künste in Bonn unter Leitung von Nikolai Grube, zielt darauf, ein umfassendes Wörterbuch der klassischen Maya-Sprache zu erstellen. Diese Schriftsprache, überliefert in Hieroglyphen, ist bis heute nur teilweise entziffert und zeichnet sich durch eine außergewöhnlich komplexe Struktur aus. Sie gehört zu den herausforderndsten Schriftsystemen weltweit. Ein wesentliches Ziel ist es, den Wortschatz der Sprache in seiner authentischen Schreibung digital zu erfassen und wissenschaftlich zu analysieren. Tausende von Lemmata werden dabei kontextuell dokumentiert und annotiert, um tiefere sprachliche Strukturen sichtbar zu machen. Die digitale Verarbeitung erfolgt unter anderem in der virtuellen Forschungsumgebung TextGrid, wo die Hieroglyphentexte im standardisierten XML-TEI-Format annotiert und strukturiert werden. Der Zeichenkatalog des Projekts basiert auf dem numerischen System von Thompson, wurde jedoch grundlegend überarbeitet, bereinigt und um hunderte neue Einträge erweitert. Fehlklassifizierte oder doppelt aufgeführte Zeichen wurden entfernt. Die Texte werden zudem mit dem eigens für das Projekt konzipierte Tool ALMAH (Annotator for the Linguistic Analysis of Maya Hieroglyphs) linguistisch analysiert, transliteriert und transkribiert, um sie für morphologische Untersuchungen aufzubereiten. Die daraus resultierenden Transkriptionen bilden die Grundlage für das digitale und das gedruckte Wörterbuch. Durch die Kombination moderner Technologien mit linguistischer Expertise entsteht so eine neue Grundlage für die Erforschung der Maya-Schrift. Die Ergebnisse sollen langfristig im Open Access zur Verfügung stehen und sowohl der Fachwelt als auch einer breiteren Öffentlichkeit zugänglich gemacht werden.
Ein digitaler Zeichenkatalog der Maya-Schrift
Theoretische Grundlagen
Für die Erstellung eines digitalen Textkorpus und eines Wörterbuchs für eine durch ein nur teilweise entziffertes Schriftsystem überlieferte Sprache ist ein Zeichenkatalog – ein systematisches Inventar sämtlicher Schriftzeichen und ihrer graphischen Realisierungen – unverzichtbar. Er bildet die Grundlage, um die komplexe Beziehung zwischen visuellen Markierungen (Graphe) und sprachlichen Einheiten (Zeichen), wie Laute oder Morpheme, zu dokumentieren und fundiert zu analysieren. Im Rahmen des Projekts wurde hierfür in der Forschungsumgebung IDIOM, eingebettet in TextGrid, ein digitaler Zeichenkatalog entwickelt (Prager et al. 2024). Diese hochdifferenzierte Plattform, die speziell auf die systematische Erfassung und Analyse der komplexen Hieroglyphenschrift der Maya zugeschnitten ist, ermöglicht eine präzise und umfassende Untersuchung der Vielfalt und Struktur dieses Schriftsystems. Das Projektportal unter https://classicmayan.org macht diese innovative Ressource nun einer breiteren Forschungsgemeinschaft zugänglich.
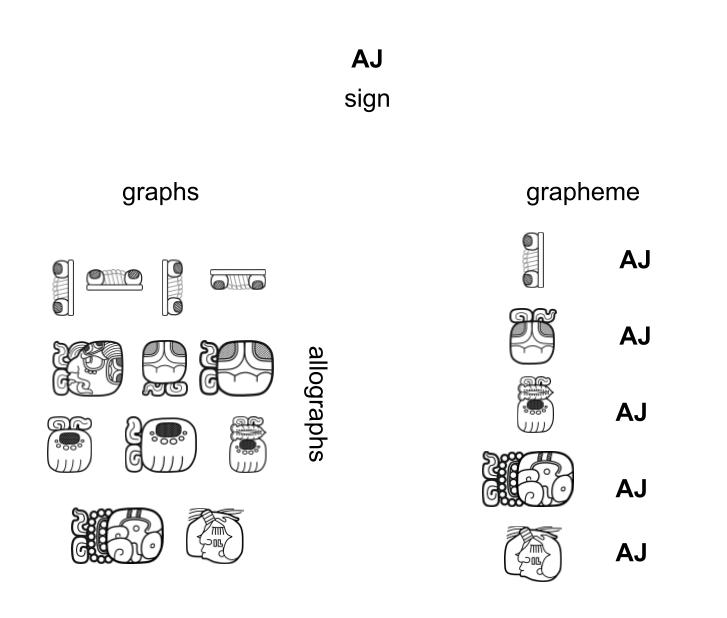 |
| Abbildung 1. Beziehung zwischen Zeichen (semantisch), Graph / Allograph (visuell) und Graphem (visuell und semantisch). Graphische Umsetzung: Christian Prager, 2025. |
Ein zentraler methodischer Ansatz liegt in der klaren Unterscheidung zwischen Zeichen und Graph (Abbildung 1): Während Zeichen abstrakte, semantische Einheiten repräsentieren, die die sprachliche oder konzeptuelle Ebene eines Schriftsystems verkörpern, sind Graphe die konkreten visuellen Realisierungen dieser Zeichen (Diehr et al. 2018). Ein Graphem entsteht somit aus der Verbindung einer sprachlich-funktionalen Ebene mit einer graphischen Ebene, die sämtliche visuellen Darstellungsformen umfasst, welche die sprachliche Bedeutung manifestieren. Unterschiedliche Graphe, die dieselbe sprachliche Funktion erfüllen, stehen in allographischer Beziehung zueinander und bilden gemeinsam die Varianten eines Graphems – der zugrunde liegenden abstrakten Einheit des Schriftzeichens. Diese methodische Trennung ermöglicht es, sowohl die graphische Vielfalt als auch die semantische Funktion eines Schriftsystems unabhängig voneinander zu erfassen und zu analysieren – im Sinne einer strukturalistischen Zeichenauffassung (de Saussure 1931) sowie einer semiotischen Differenzierung zwischen Zeichenform und Zeichenbedeutung (Peirce 1931:2.228-2.231). So können selbst solche Graphe in den Katalog integriert werden, deren sprachliche Bedeutung und allographische Beziehung zu anderen Graphen noch unerschlossen ist. Dies trägt nicht nur zu einem umfassenden Verständnis der Schrift als kulturelles und linguistisches System bei, sondern schafft auch eine systematische Übersicht aller graphischen Realisierungen – unabhängig von ihrem sprachlichen Bezug.
Digitale Grundlagen
Der digitale Katalog basiert auf einem flexiblen, modularen Konzept, das die Trennung zwischen Graphen und Zeichen berücksichtigt. Informationstechnologische Grundlage ist eine ontologiebasierte Modellierung, die auf Standards wie dem CIDOC Conceptual Reference Model (CRM) fußt (Diehr et al. 2018) (Abbildungen 2-3). Diese Modellierung stellt sicher, dass die semantischen Beziehungen zwischen den Elementen des Katalogs festgehalten und in einem flexiblen System dargestellt werden, wodurch die Interoperabilität mit anderen Forschungsdatenbanken gewährleistet wird. Mithilfe von Metadatenschemata werden diese semantischen Relationen klar strukturiert, was nicht nur eine dynamische Erweiterbarkeit, sondern auch eine detaillierte Wissensrepräsentation ermöglicht. Von besonderer Bedeutung ist die automatisierte, qualitative Bewertung der verschiedenen Entzifferungshypothesen (Diehr et al. 2019). Der Katalog verwendet hierfür ein mehrstufiges Bewertungssystem, das Lesungsvorschläge systematisch anhand formaler Kriterien beurteilt, die auf der Grundlage der Forschungsliteratur definiert wurden (cf. Houston 2001:9; Zender 2017). Auf diese Weise können Hypothesen nicht nur klar dokumentiert, sondern auch hinsichtlich ihrer Plausibilität bewertet werden, wobei Stufe 1 für eine besonders hohe Sicherheit der Hypothese steht und Stufe 8 Lesungen als unzureichend belegt und somit als spekulativ klassifiziert. Dieses Verfahren gewährleistet ein hohes Maß an Transparenz und wissenschaftlicher Präzision bei der Bearbeitung der noch nicht vollständig entschlüsselten Schrift. Der Katalog integriert zudem die Ergebnisse aus elf bestehenden Katalogen zur Klassifikation der Maya-Hieroglyphen in Form einer Konkordanz, darunter die bis heute maßgeblichen Arbeiten von Thompson (1962) und Günter Zimmermann (1956). Diese Vorgehensweise erlaubt es, die Forschungsgeschichte der Zeichenklassifikation nachzuvollziehen und Fehlklassifikationen sowie Mehrfachinventarisierungen von Allographen zu korrigieren. Ein weiteres Merkmal des Katalogs ist die präzise Systematisierung von Graphvarianten, ein Bereich, der bisher wenig untersucht und in den bisherigen Katalogen kaum berücksichtigt wurde. Der Katalog basiert dabei auf Prager und Gronemeyer (Prager und Gronemeyer 2018) und identifiziert entsprechend insgesamt 45 verschiedene Variationsmöglichkeiten. Dies erlaubt eine konsistente Erfassung der visuellen Vielfalt der Schriftzeichen und fördert das Verständnis für die ästhetischen und funktionalen Unterschiede innerhalb des Schriftsystems.
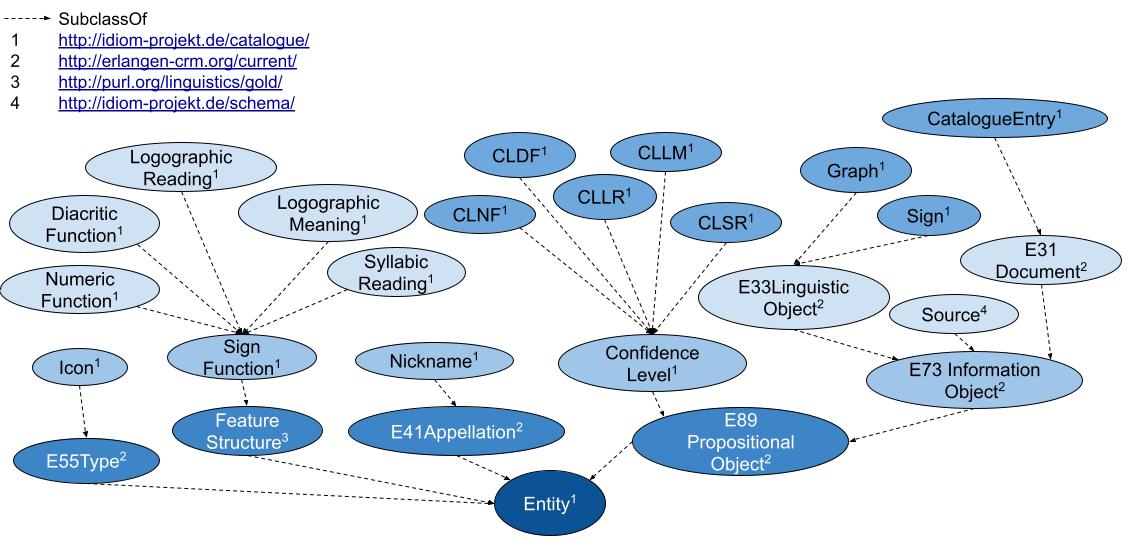 |
 |
| Abbildung 2. Klassenhierarchie des digitalen Zeichenkatalogs (Entwurf und Ausführung: Franziska Diehr, zitiert aus Diehr et al. 2018:39) | Abbildung 3. Domänenmodell des digitalen Zeichenkatalogs (Entwurf und Ausführung: Franziska Diehr, zitiert aus Diehr et al. 2018:40) |
Ein weiterer Vorteil des digital angelegten Zeichenkatalogs ist seine dynamische Erweiterbarkeit. Im Gegensatz zu statischen gedruckten Katalogen ist der digitale Katalog flexibel und kann jederzeit durch Aufnahme neuer Funde oder Entzifferungen aktualisiert werden. Fehlerhafte Klassifikationen lassen sich korrigieren, und neue Verbindungen zwischen Graphen und Zeichen können jederzeit hinzugefügt werden. Jede Entität im Katalog wird durch persistente Identifikatoren eindeutig referenzierbar gemacht, was die Nachvollziehbarkeit und wissenschaftliche Konsistenz sicherstellt. Ein besonderes Merkmal dieses digitalen Ansatzes ist die Verknüpfung des Zeichenkatalogs mit dem Textkorpus des Projekts und den linguistischen Analysetools. Jedes Graph in den digitalisierten Texten wird durch eine auf dem Katalog Thompsons (1962) basierende Katalognummer identifiziert und mit einer entsprechenden URI verknüpft, was eine dynamische Verarbeitung der Texte erlaubt. Dadurch können parallele Analysen durchgeführt werden, die auf unterschiedlichen Lesungshypothesen basieren und somit eine flexible Anpassung an verschiedene Entzifferungsansätze ermöglichen. Der digitale Zeichenkatalog des TWKM-Projekts ist damit nicht nur ein Werkzeug zur Erforschung der Maya-Hieroglyphenschrift, sondern dient auch als Blaupause für die epigraphische Arbeit in den Digital Humanities. Durch seine Open-Access-Struktur wird er sowohl der wissenschaftlichen Gemeinschaft als auch der Öffentlichkeit zugänglich gemacht, was ihn zu einem zentralen Instrument in der modernen Hieroglyphenforschung macht.
Epigraphische Grundlagen
Als erste systematische und umfassende Sammlung von Hieroglyphen schuf Thompson eine unverzichtbare Grundlage für die epigraphische Praxis. Sein Katalog dient bis heute als zentrales Referenzinstrument, da es sowohl Glyphen aus den Codices als auch aus den Monumentalinschriften umfasst und diese in einem strukturierten Inventar ordnet. Keramische Inschriften wurden aufgrund der damaligen Annahme, sie seien primär dekorativer Natur, nur marginal berücksichtigt. Trotz dieses Defizits steht Thompsons Werk in der Maya-Epigraphik in einer Reihe mit anderen wegweisenden Katalogen der jeweiligen antiken Schriftsysteme, etwa Alan Gardiners Verzeichnis der mittelägyptischen Hieroglyphen (1957), Rykle Borgers Liste assyrisch-babylonischer Keilschriftzeichen (2010) oder Xǔ Shèn's (1981) altchinesisches Zeichenlexikon Shuowen Jiezi. Thompsons System basiert auf einem ersten Katalogisierungsversuch der Schriftzeichen in den Handschriften von William Gates (1931), aber in der Hauptsache auf Günter Zimmermanns (1956) Zeichenkatalog der Hieroglyphen der damals bekannten drei Mayahandschriften; und es nutzt wie letzterer ein numerisches Kodierungsschema, das mit der Katalognummer 1 beginnt und 862 Grapheme im Bereich von 1 bis 1347 einordnet. Paläographische Varianten wurden von Thompson durch fortlaufende Kleinbuchstaben gekennzeichnet (z. B. 1030a, 1030b usw.), ohne dass Thompson die Funktion der Varianten reflektiert hätte. Obwohl der Katalog durch den Wissensstand der späten 1950er Jahre geprägt war und neue Inschriftenfunde seit der Publikation im Jahr 1962 letztlich zu seiner Unvollständigkeit führten, ermöglicht seine methodische Struktur bis heute die Identifikation von rund 70 % der Graphe in einem Text. Für nicht katalogisierte bzw. neu entdeckte Glyphen schlug Thompson vorausschauend vor, bislang ungenutzte Katalognummern innerhalb seines bestehenden Schemas zu verwenden. Spätere Revisionen, insbesondere die von Nikolai Grube (1990) sowie von William Ringle und Thomas C. Smith-Stark (1996), verbesserten die Systematik erheblich. Mehrfachnennungen in Thompsons Katalog wurden in diesen Werken weitgehend identifiziert und aufgehoben sowie unter verschiedenen Nummern aufgelistete Allographe unter einer einzigen Nummer zusammengefasst. Das Projekt Textdatenbank und Wörterbuch des Klassischen Maya griff diese Ansätze und Revisionen auf und entschied sich, Thompsons in der epigraphischen Forschung etabliertes Nummernsystem zu bewahren („einzufrieren“), um dessen historische Integrität zu sichern. Neue Glyphen wurden daher grundsätzlich ab der Katalognummer 1500 ergänzt. Diese methodische Entscheidung kombiniert den Erhalt des ursprünglichen Systems mit einer flexiblen Erweiterung, die den Anforderungen moderner Forschung gerecht wird. Die Grundlage der aktuellen Revision bilden dabei Thompsons „Gray Cards“, originale Dokumentationskarten aus dem Nachlass von Thomas Barthel, die in Tübingen aufbewahrt sind.[1] Diese wurden quellenkritisch analysiert und umfassend überarbeitet. Der gesamte Zeichenkatalog wurde erneut und nach heutigen Erkenntnissen zur Schrift nach Mehrfachnennungen, Fehlklassifikationen und Unstimmigkeiten durchsucht und reorganisiert. Während dieses Prozesses fertigte Christian Prager standardisierte und präzisierte Zeichnungen aller Glyphen und Varianten an.
In einer strukturierten Gegenüberstellung der wichtigsten Glyphenkataloge, die bis 1963 veröffentlicht wurden, einschließlich der Revisionen durch Grube (1990) sowie Ringle & Smith-Stark (1996) wurden Zahlzeichen, Affix- und Hauptzeichengruppen mit Untergliederung in formal-semantische Kategorien sowie die Anzahl der dokumentierten Zeichen erfasst. Tabelle 1 verdeutlicht die Unterschiede in Systematik und Umfang der jeweiligen Klassifikationen. Die Revision durch das TWKM-Projekt ergab, dass 482 der ursprünglich von Thompson katalogisierten 862 Graphe weiterhin verwendbar sind – eine Reduktion um fast 50 %, bedingt durch die Korrektur von Fehlklassifikationen und Mehrfacheinträgen.
| Katalog | Zahlzeichen | Affixe | Hauptzeichen |
Anzahl Elemente | ||||
| Minor Elements (G) | Menschliche Köpfe (G, Z, T), Körperteile (G, Z), gesichtsartige (G, Z) | Tiere, Tierköpfe Körperteile (G, Z) | Konventionell-ornamental, gegenständlich (G, Z), abstrakt (NG) | Farben, Kosmologie, kalendarisch-astronomisch ('G) | Zweifelhaft (T) | |||
| Gates 1931 | 57-59 [0-19][2] [0-10][3] |
600-620, 631-650, 657, 661-674, 676-690, 700-701, 704-708, 710-721, 723-728, 741-754, 756-757 |
71-83, 87-93, 95-96, 98, 101, 103-115, 119, 120-123, 125-127, 141-145, 147-148 |
201-217, 221-223, 225-228, 230-232, 241-251, 261-271, 275-277, 279-280, 291-293 |
301-307, 310-314, 317-349, 351-359, 361-412, 421-422 426-438 |
1-25, 26-44, 45-56, 66-70, 446, 451-455, 458, 466-497 |
476 | |
| Zimmermann 1956 | I-XIII | 1-91 | 100-169 | 700-763 | 1300-1377 | 316 | ||
| Evreinov et al. 1961 | [I-XIX][4] | 3-4, 6, 10, 12-15, 17, 21-27, 30-36 40-41, 43-45, 47, 50-51, 53-57, 60-67, 70-77, 100-105, 107, 110-117, 120 |
233-236, 240 242-247, 250-255, 261-267, 270 272-276, 300-307, 310-317. 523, 525-526, 530-532, 537 |
320-323, 325-327, 331-337, 340-347, 350-354, 357, 450-452, 454-457, 460-467, 470-473, 475-477, 544-546, 550, 552, 554-557, 560-561, 563-565 |
121-125, 127, 130-137, 140, 142-147, 150-151, 153-156, 170-177, 200, 202-204, 206-207, 210, 212-216, 220-227, 230, 360-363, 365-367, 370-371, 373, 375, 377, 400-401, 403-407, 410-411, 413-417, 420-427, 430, 432-437, 440-447, 500-506, 510-517, 520, 522, 536, 537, 541, 543, 570, 573-575 |
326 | ||
| Thompson 1962 | [I-XIX][5] | 1-370 | 666-673, 710-714 (hands), 700-705 (body), 1000-1087 | 734-766, 788-804, 828-829, 832, 839, 844, 845, 849 | 501–665, 674-699, 706-709, 715-733, 767-787, 805-827, 830-831, 833-838, 840-843, 846-848, 850-856 | 1300-1347 | 862 | |
| Knorozov 1963 | [I-XIX] | 1-110, 415-446 |
202-272, 314-317, 341-343, 472-516, 524-525, 534-535 |
273-297, 318-322, 344, 376-414, 517-519, 536-540 |
111-201, 298-313, 323-340, 345-375, 447-471, 520-523, 526-533 |
560 | ||
| Grube 1990 | 1, 3-4, 8, 10, 12-13, 15-17, 19-21, 23-26, 28, 30, 32, 42, 44-45, 47, 50-52, 55-57, 59-61, 63, 66-70, 73-75, 78-82, 84, 86-89, 93-95, 97-98, 100, 102-112, 114-124, 128-130, 132, 134-137, 139, 142-145, 147, 149-157, 159, 161-163, 165, 168, 171-177, 181-187, 190, 192-199, 201-204, 206-218, 221-227, 231, 233-242, 244-245, 248-251, 253, 256, 262-274, 278, 281-288, 290-292, 294-297, 299, 301, 304-306, 309-310, 314, 316, 318-319, 321, 325-327, 329, 335-338, 340-341, 348, 351, 358, 361, 363-364, 367-368, 370 1304-1305, 1320, 1330, 1335-1336, 1339, 1341 |
667-670, 672, 700, 702, 704-705, 710-711, 713-714; P1-132 |
734, 736-737, 740-742, 744-749, 751-753, 755-761, 763-766, 789-790, 792-804, 829, 832, 839, 844-845 |
501-504, 506-507, 509-514, 516, 518-530, 533, 535-545, 547-555, 559-567, 569-572, 574, 576-577, 579-580, 582-585, 587-590, 594-597, 600, 604-606, 610-611, 613, 622-623, 625-631, 633, 639-641, 643-644, 646-649, 651-653, 656-657, 659-660, 662, 674-676, 678, 680-682, 685-687, 692, 694, 696-697, 699, 708-709, 717, 721, 723-727, 729-733, 768, 770, 776-777, 784-785, 805-806, 808-810, 812, 816-817, 819, 822, 824, 833-837, 842-843, 847, 855-856, A1-A49 |
1304-1305, 1320, 1330, 1335-1336, 1339, 1341 | 658 | ||
| Ringle & Smith-Stark 1996 | 1-2, 4-5, 7-8, 10, 12-13, 15-17, 19-21, 23-25, 28, 31-32, 34, 36, 42, 44-45, 50-52, 54-61, 64, 66-70, 74, 76, 78-79, 82-84, 86-89, 93-96, 98-100, 102-103, 105-110, 112-117, 119-125, 127-130, 132, 134-137, 141-156, 158-160, 162, 164-170, 172-176, 178-179, 181-182, 184-188, 190, 193-194, 197-201, 203-204, 206-208, 210, 212, 214, 216-223, 225-228, 230-234, 236-241, 243, 245, 249, 251, 253, 255-256, 263, 265-269, 271-274, 276, 278, 281-284, 287-288, 291, 294-299, 301, 303-304, 306-309, 312-316, 318-319, 321-323, 325-331, 333-343, 348, 351, 355-356, 358, 361-364, 366-370, 401-427 |
667-673, 700-705, 710-714, 1000, 1003-1019, 1021-1023, 1026-1057, 1059-1068, 1070-1071,1073-1078, 1080-1087, 1092, 1101-1161 |
734, 736-752, 754-766, 788-799, 801-804, 828-829, 832, 839, 844-845, 849 |
501-530, 533, 536-546, 548-556, 559-570, 572-574, 576-588, 590, 592-598, 600, 604-611, 613-616, 618-619, 622-623, 625-637, 639-642, 644-654, 656-660, 662-664, 674-676, 678-681, 683-690, 692-697, 699, 706-709, 715-718, 720-722, 724-733, 767-771, 774, 776-777, 779-780, 782-784, 787, 805-806, 808-813, 816-819, 823-824, 826-827, 830-831, 833-838, 840-843, 847, 850-851, 853-856, 901-957 |
781 | |||
| Digital Catalog of Maya Hieroglyphs (2025) | 1, 4-5, 11-12, 15-17, 19-21, 23-25, 28-29, 31-32, 42, 44-45, 53, 55, 57-61, 64, 66-69, 73-74, 77-79, 82, 84, 86-89, 93, 95, 97-99, 102-104, 106, 108-110, 112, 114-117, 120-124, 126, 128, 130, 135-137, 139, 145, 149-153, 155, 157-159, 164, 168, 170, 172-178, 181-188, 190, 192-195, 197-200, 203-204, 206-208, 210-212, 214, 216, 218, 220-227, 229, 231, 233-234, 236-241, 243, 249-251, 257, 265-269, 271-274, 278, 281-282, 284-285, 287, 290-291, 294-297, 299, 301, 304-305, 307, 309, 316, 325-327, 329, 335-337, 339-340, 346, 348, 351, 355, 358, 361, 364, 367, 369-370 |
667-673, 700-705, 710-714, 1000, 1003-1009, 1011, 1013-1014, 1022, 1024-1028, |
734, 737-742, 744, 746-752, 754-761, 763-766, 789, 791, 793-799, 801-804, 828-829, 832, 839, 844 |
501-514, 516, 519-521, 523-530, 533, 535-545, 547-552, 554, 559-561, 563-566, 568-570, 572-574, 576-580, 582-586, 588, 590, 592, 594-598, 600, 604, 606-607, 609-611, 613-614, 617, 622-628, 630, 632, 643-648, 650, 653, 656-657, 659, 662, 665, 674-675, 678-681, 684-686, 692, 696-697, 699, 708-709, 716-718, 721-725, 727-733, 767-768, 770, 779-780, 785, 805-810, 812, 819, 824, 827, 830-831, 834-835, 837, 840, 843, 855-856 |
1304, 1320, 1341 | 482 (von 1048) | ||
| Tabelle 1. Strukturierte Gegenüberstellung zentraler Glyphenkataloge, die bis 1963 veröffentlicht wurden, einschließlich der Revisionen durch Grube (1990), Ringle & Smith-Stark (1996) und durch das Projekt Textdatenbank und Wörterbuch des Klassischen Maya. | ||||||||
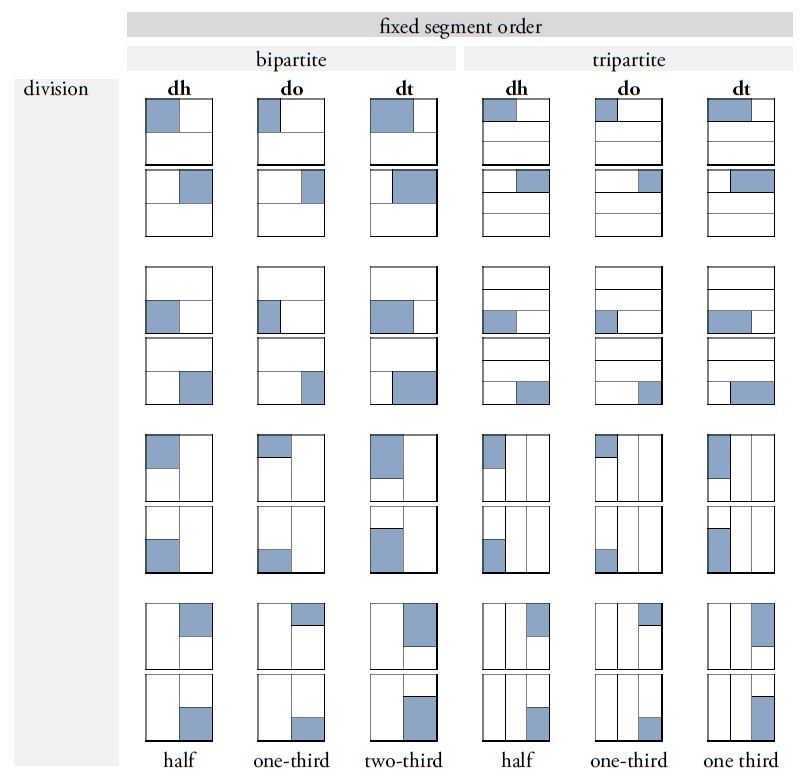
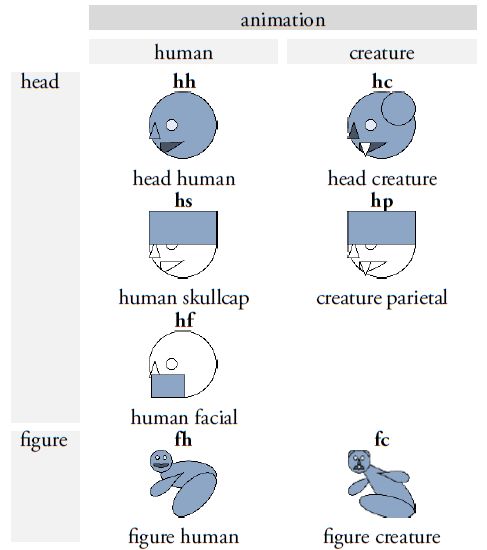
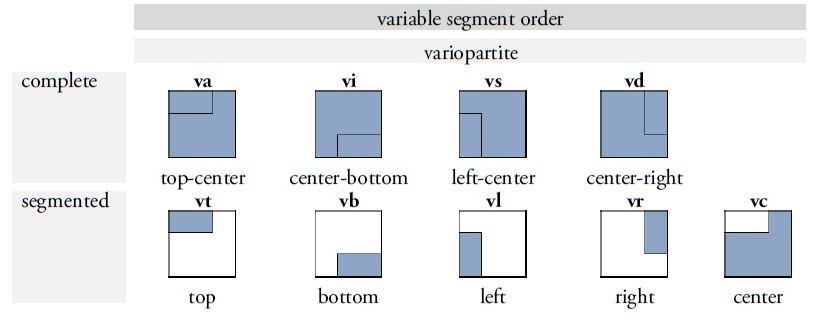
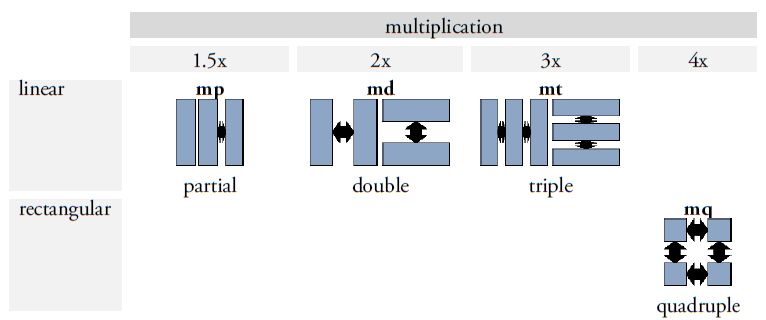
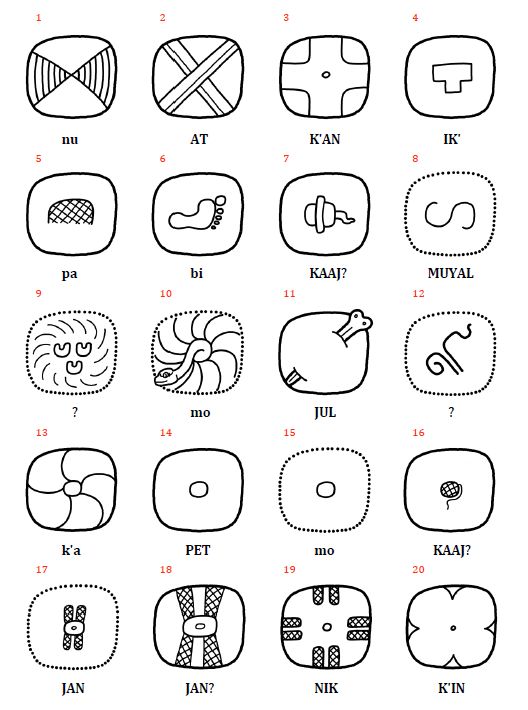
Ein wichtiger Fortschritt in der Überarbeitung von Thompsons Werk besteht in der Einführung eines erweiterten Klassifikationssystems, das die Differenzierung und Benennung von Graphvarianten erheblich erleichtert. Thompsons ursprünglicher Ansatz, Varianten durch willkürliche Buchstaben zu kennzeichnen, wurde auf der Basis von Prager und Gronemeyer (2018) durch ein zweistelliges Buchstabencodesystem ersetzt, das eine präzisere Unterscheidung der Varianten ermöglicht (Abbildung 4). Das neue System beruht auf der Beobachtung, dass zahlreiche Maya-Zeichen entweder durch horizontale oder vertikale Segmentierung in zwei oder mehr graphische Einheiten zerlegt werden können oder in Darstellungen vorkommen, die Tiere, Menschen oder Gottheiten in Kopf- oder Vollform zeigen. Diese Transformationen und Segmentierungen ermöglichen nicht nur eine klare visuelle Differenzierung der Varianten, sondern auch eine systematische Anordnung basierend auf dem zugrunde liegenden Prinzip der Variation. Die Position und Form der Segmente werden durch standardisierte Codes wie „bt“ oder „bv“ spezifiziert. Der Buchstabe „b“ steht für zweigliedrige (bipartite) Zeichen, während „v“ (vertical) darauf hinweist, dass die Segmentierung entlang der vertikalen Achse erfolgt. Der Code „bt“ bezeichnet beispielsweise eine Graphvariante, bei der nur das Segment oberhalb dieser Achse dargestellt wird, wobei „t“ für top steht. Ein weiterer Aspekt unserer Revision von Thompsons Werk ist die Berücksichtigung der sogenannten pars-pro-toto-Schreibung, bei der ein Teil eines Zeichens stellvertretend für das gesamte Graphem verwendet wird. Solche Varianten werden mit dem Code „ex“ gekennzeichnet. Dieser paläographische Modus ermöglicht eine platzsparende Anordnung innerhalb der Hieroglyphenblöcke und fördert zugleich die ästhetische Vielfalt der Schrift, ohne die sprachliche Bedeutung der Glyphen zu beeinträchtigen. Dieses neu eingeführte System zur Klassifikation graphischer Varianten berücksichtigt auch graphische Transformationen wie die Vervielfachung von Elementen (markiert durch "m" oder multiple) und die „Belebung“ von Graphen, bei der Graphe in anthropomorpher oder zoomorpher Variation dargestellt und damit "belebt" werden. Wird ein üblicherweise geometrisch-abstraktes Graph in der Form eines Kopfes repräsentiert, wird dies in unserem Klassifikationssystem mit „h“ (head) kodiert. Handelt es sich dabei um einen menschlichen oder tierischen Kopf, erfolgt die Kennzeichnung mit einem weiteren Buchstaben: „hh“ (head human) für menschliche Köpfe und „hc“ (head creature) für tierische oder Mischwesen-Köpfe. Vollfiguren werden hingegen mit „f“ (full) markiert, wobei „fh“ (full human) für menschliche Vollfiguren und „fc“ (full creature) für tierische oder hybride Darstellungen stehen.
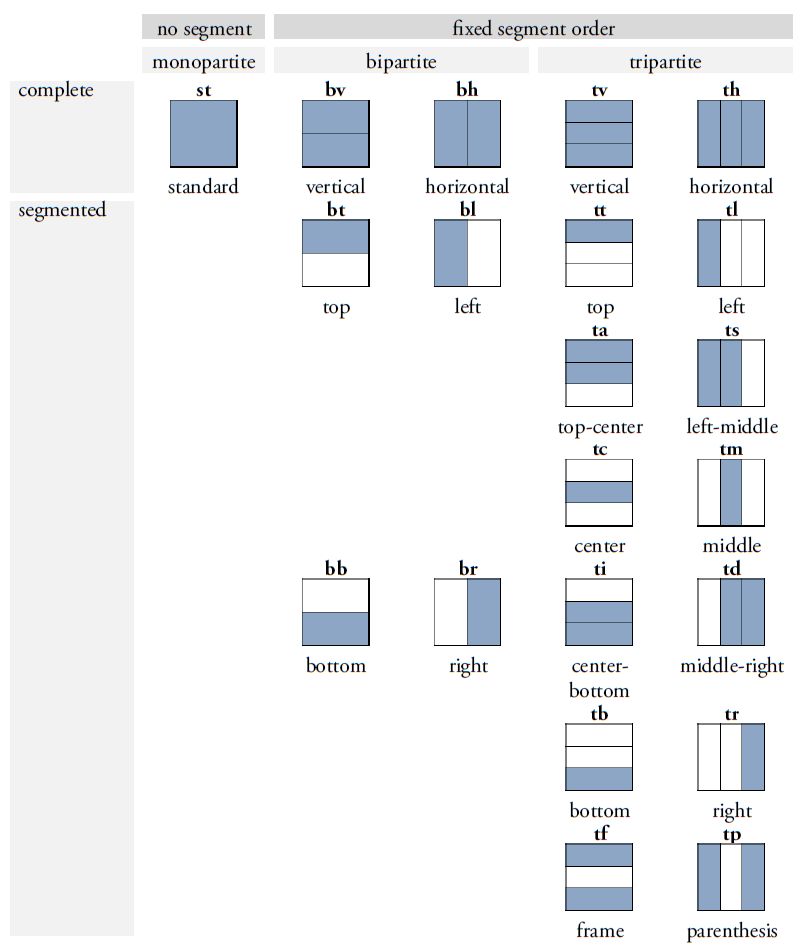 |
 |
|
|
 |
|
Abbildung 4. Systematischer Überblick über die häufigsten Segmentierungs- und Transformationstypen in der Maya-Schrift. Die binären Buchstabencodes beziehen sich auf bestimmte Variationsmuster und werden an die jeweilige Zeichennummer angehängt, um eine genaue Identifizierung einzelner Graphvarianten anhand ihres strukturellen Segmentierungs- und Transformationsschemas zu ermöglichen. Konzept: Christian Prager und Sven Gronemeyer; Originalillustrationen adaptiert aus Prager und Gronemeyer (2018, Abb. 11, 12, 14, 17 und 20). Illustrationen: Sven Gronemeyer. |
|
Der graphischen Vielfalt und oftmals spielerischen Gestaltung der Zeichen liegen Vorstellungen von der Belebtheit sprachlicher Aussagen und ihren schriftlichen Materialisierungen zugrunde, aber auch das Bemühen von Schreibern um eine möglichst kunstvolle Kalligraphie, ohne die Lesbarkeit der Schriftsprache zu beeinträchtigen. Thompsons numerales System bietet hier eine hervorragende Grundlage für diese Erweiterung seines Systems durch Variantenkodierung – eine Idee, die Thompson bereits bei der Erstellung seines Katalogs vor Augen hatte (1962:5). Er konzipierte seinen Katalog als dynamisches Werkzeug, das kontinuierlich erweitert und verbessert werden sollte. Die aktuelle Revision mit der Neuklassifikation von Zeichen setzt seine Vorstellung um, indem sie das bewährte Nummernsystem beibehält, bestehende Unstimmigkeiten beseitigt und innovative Klassifikationsmethoden einführt. Durch die systematische Integration paläographischer Varianten dokumentiert der überarbeitete Katalog nicht nur die ästhetische Vielfalt der Glyphen, sondern erfasst auch deren funktionale Unterschiede innerhalb des Schriftsystems. Diese Fortschritte schließen die Lücken des ursprünglichen Katalogs und eröffnen neue Perspektiven für die Analyse der visuellen und funktionalen Vielfalt der Maya-Schrift. Thompsons überarbeiteter Katalog verbindet historische Grundlagen mit den Anforderungen moderner Forschung und stellt ein neues, digitales Werkzeug für die Dokumentation und Analyse der klassischen Maya-Schrift dar.
Klassifizierung und Ordnungsprinzipien
Dank seiner systematischen und ästhetisch durchdachten Struktur bleibt Thompsons Katalog bis heute eine vielzitierte Referenz für die wissenschaftliche Auseinandersetzung mit der Maya-Schrift. Sein auf die Monumente angewandtes Ordnungssystem basiert auf den Arbeiten von William Gates (1931) und Günter Zimmermann (1956), deren Kataloge die Hieroglyphen der drei damals bekannten Maya-Handschriften berücksichtigten. Ergänzend trugen Hermann Beyers Analysen der Schriftzeichen in ihrem Verwendungskontext wesentlich dazu bei, die in den drei genannten Katalogen eingeführte – heute kritisch betrachtete – Unterscheidung zwischen sogenannten Hauptzeichen und Affixen zu präzisieren (Beyer 1930; 1934a; 1934b; 1936).
Thompson ordnete die Zeichen primär nach visuellen und ikonographischen Kriterien und verfeinerte die Kategorien von Gates, Zimmermann und Beyer. Besonders hervorzuheben ist seine Differenzierung zwischen Affixen, Hauptzeichen und Portraithieroglyphen, die er durch spezifische Nummernbereiche systematisierte. Die Affixe, die von Hermann Beyer als „Minimalzeichen“ eingeführt und von Zimmermann präzisiert als schmale Zeichen mit einem Seitenverhältnis von 1:2 oder 1:3 beschrieben wurden, treten typischerweise in Kombination mit größeren Hauptzeichen innerhalb eines Hieroglyphenblocks auf. In Thompsons Katalog sind sie unter den Nummern 1 bis 370 erfasst, wobei ihre Allographe detailliert illustriert sind, um ihre Positionierung und paläographische Funktion im Hieroglyphensystem zu veranschaulichen. Thompsons Unterscheidung von Affixen und Hauptzeichen liegt das zur damaligen Zeit dominierende Verständnis von Schrift zugrunde, das die Maya-Schrift als ausschließlich logographisches System deutet. In diesem kommt den Hauptzeichen die Funktion von Wortwurzeln zu, während Affixe als präfigierte und suffigierte Morpheme oder auch als Adjektive interpretiert werden.
Thompson plante gezielt Raum für zukünftige Ergänzungen ein: Die Affixe enden im Katalog bei Nummer 370, mit Platz für Erweiterungen bis zur Nummer 500 (Thompson 1962:5). Ab dort beginnt die Nummerierung der Hauptzeichen, die den Bereich 501 bis 856 umfasst. Diese Hauptzeichen zeichnen sich durch ein quadratisch-rechteckiges Seitenverhältnis aus und vereinen eine ikonographische Vielfalt, die Darstellungen menschlicher, tierischer und hybrider Körperformen, kulturelle Artefakte sowie Umweltmotive und symbolische Elemente aus Glaubens- und Vorstellungswelten umfasst. Die Kombination dieser Elemente innerhalb einzelner Glyphen erschwert jedoch oft eine eindeutige Zuordnung zu einer bestimmten Kategorie. Darüber hinaus existieren zahlreiche ikonographisch schwer identifizierbare Graphe, deren Klassifikation bis heute wissenschaftliche Herausforderungen aufwirft.
Die Herausforderung, die Maya-Schrift ausschließlich auf ikonographischer Grundlage zu kategorisieren, erweist sich als ein grundlegendes Hindernis für eine Systematisierung nach dem Vorbild der ägyptischen Hieroglyphen, wie sie in den Katalogprojekten von Rendón und Spescha (1965) sowie von Martha Macri, Mathew Looper, Gabrielle Vail und Yuriy Polyukhovich angestrebt wurde (Macri und Looper 2003; Macri und Vail 2009; Looper et al. 2022). In der jüngsten Version ihres Inventars (2022) werden die Grenzen eines rein ikonographischen Ansatzes besonders augenfällig: Macri, Looper und Vail revidierten ihre früheren Klassifikationen aus den Jahren 2003 und 2009 und führten neue, teils abweichende Zeichencodes ein. Dieser Ansatz verdeutlicht jedoch nicht nur die Unzulänglichkeiten dieser Methode, sondern lässt auch Zweifel an der Konsistenz und Nachhaltigkeit ihrer Systematisierung aufkommen. Die resultierende Notwendigkeit alternativer Klassifikationsmethoden wird damit implizit anerkannt.
Inkonsistenzen seines Systems wurden bereits von Thompson festgestellt, indem er die strikte Trennung zwischen Affixen und Hauptzeichen hinterfragte. Rund 60 Affixe übernehmen laut Thompson gelegentlich die Funktion eines Hauptzeichens, was in seinem Katalog durch das Kürzel „M.S.“ (für Main Sign) hinter der Nummer des jeweiligen Affixes gekennzeichnet wurde (Thompson 1962:14). Hauptzeichen, die als Affixe fungierten, wurden von Thompson mit der Abkürzung "af" deklariert (Thompson 1962:34). Für neu entdeckte Hauptzeichen ließ Thompson gezielt Lücken im Bereich 857 bis 999, während er die Portraithieroglyphen ab Nummer 1000 inventarisierte. Diese Kategorie umfasst Zeichen mit individuellen Merkmalen menschlicher oder hybrider mythologisch-göttlicher Figuren, wobei die Grenzen zwischen ersteren und den hybriden Wesen oft fließend sind. Zeichen mit unklarer Klassifikation wurden in den Bereich 1300 bis 1347 eingeordnet, den Thompson als „purgatory group“ bezeichnete. Diese Gruppe wurde später von Grube (1990) revidiert, wobei die meisten Zeichen neu klassifiziert oder entfernt wurden, mit Ausnahme der Nummern 1304 und 1327.
Die ikonographische Vielfalt sowie die oft ungeklärte Bedeutung zahlreicher Glyphen und ihrer Varianten machen eine systematische Klassifikation der Maya-Schrift weiterhin zu einer äußerst anspruchsvollen Aufgabe. Im Vergleich zu Schriftsystemen wie den ägyptischen Hieroglyphen, die durch Alan Gardiner eine kohärente Systematisierung erfuhren, stellt die Systematisierung der Maya-Hieroglyphen eine weitaus komplexere Herausforderung dar. Thompsons Katalog, der aus pragmatischen Erfordernissen der Dokumentation und Forschung entstand, reflektiert diese Komplexität. Gegen Ende seiner Arbeit entfernte sich Thompson aber zunehmend von einer strikt ikonographischen Gruppierung und integrierte neu entdeckte Zeichen chronologisch in eine fortlaufende Nummerierung, unabhängig von ihren morphologischen Merkmalen. Dieses dynamische Vorgehen unterstreicht die Flexibilität seines Systems und verdeutlicht die Notwendigkeit anpassungsfähiger Ansätze bei der Analyse der Maya-Schrift. Trotz seiner Einschränkungen bleibt Thompsons Katalog dennoch ein unverzichtbares Werkzeug der Maya-Epigraphik. Seine systematische und umfassende Herangehensweise sowie die Funktion dieses Katalogs als Standardwerk verleihen ihm eine zentrale Bedeutung in der Mayaforschung. Dies zeigt sich auch in seiner weitaus häufigeren Rezeption im Vergleich zu früheren und selbst nachfolgenden Katalogen, die in ihrer Reichweite und Methodik oftmals eingeschränkt blieben.
Die Struktur unseres digitalen Katalogs bildet eine Brücke zwischen den frühen Pionierarbeiten und den modernen, digital gestützten Forschungsmethoden. Die Erfahrungen der letzten Jahrzehnte haben gezeigt, dass eine numerische Kodierung der Schriftzeichen unabhängig von ihrer ikonographischen Beschreibung erfolgen sollte – ein Ansatz, der insbesondere im digitalen Raum realisierbar ist. Im Rahmen dieses Projekts wurde daher ein dynamisch-adaptiver Zeichenkatalog entwickelt, der es ermöglicht, die Zeichen flexibel nach sprachlichen und ikonographischen Merkmalen zu sortieren, zu filtern und individuell zu modifizieren (Abbildung 5). Dabei dient die numerische Kodierung lediglich der eindeutigen Referenzierung von Zeichen und Graphen, ohne deren ikonographische Eigenschaften zu beeinflussen – oder umgekehrt (Diehr et al. 2018).
|
|
 b b |
 c c |
| Abbildung 5. Auswahl an Filtermöglichkeiten im digitalen Zeichenkatalog: a) zeigt eine (alpha)numerische Sortierung der Graphen mit den Katalognummern 501 bis 510; b) ordnet dieselben Graphen nach ihrer Häufigkeit im gesamten Textkorpus; c) zeigt die 28 am häufigsten vorkommenden Graphen im Textkorpus von Pusilha. Zeichnungen: Christian Prager | ||
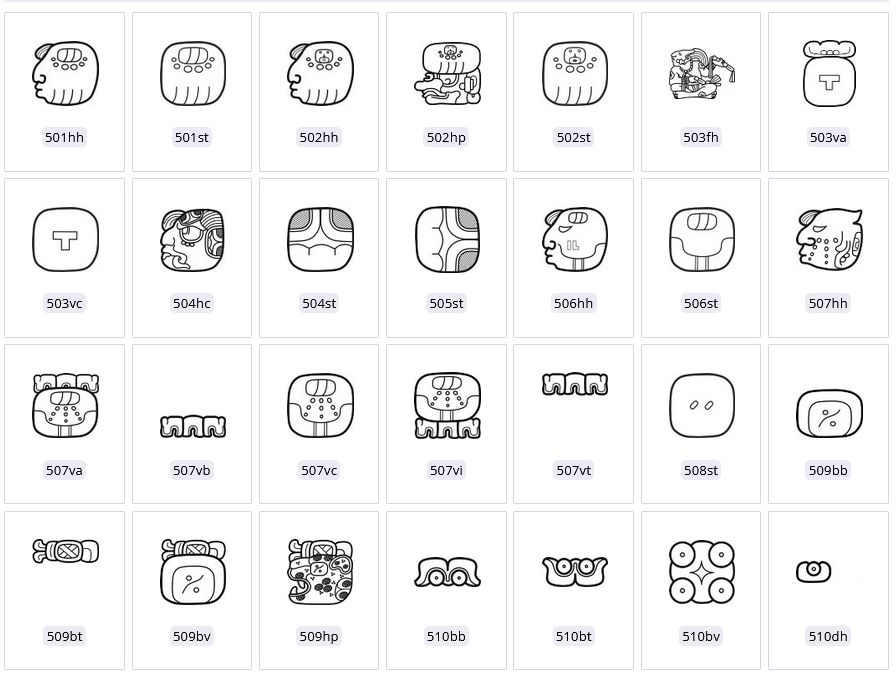 a
aZeichen, die in Thompsons Katalog nicht erfasst wurden, sind unabhängig von ihrer Morphologie fortlaufend ab der Katalognummer 1500 in das Inventar der Maya-Schriftzeichen aufgenommen worden. Mit Hilfe kontrollierter Vokabulare zur Beschreibung des Graphikons der jeweiligen Zeichen in der virtuellen Forschungsumgebung TextGrid können diese neuen Zeichen präzise und systematisch dokumentiert werden. Die Vokabulare “graph composition” und “iconography” vereinen sowohl formale als auch den Bildinhalt des Graphikons betreffende Beschreibungskriterien, sodass die Schriftzeichen einerseits anhand äußerer Merkmale, wie "Schmal-" oder "Breitzeichen", und andererseits nach inhaltlichen Kategorien, beispielsweise Tiere, Menschen oder Artefakte, erfasst und analysiert werden können. Diese flexible und dynamische Methodik eröffnet den Nutzenden die Möglichkeit, Zeichen nicht nur effizient zu identifizieren und zu sortieren, sondern auch tiefgehende Analysen durchzuführen, die sowohl formale als auch semantische Dimensionen berücksichtigen. Durch diesen Ansatz wird ein wesentlicher Beitrag zur Systematisierung und Erforschung der Maya-Schrift im digitalen Zeitalter geleistet, ohne dabei die Verbindung zu früheren Katalogprojekten zu verlieren. Digitale Konkordanzen, die Abbildungen der Originalzeichnungen einbeziehen, erlauben es den Nutzenden der Datenbank, frühere Katalogisierungsprojekte unmittelbar mit dem vorliegenden digitalen Zeichenkatalog zu vergleichen. Diese Funktion ermöglicht es, Zeichenklassifikationen und methodische Ansätze der vergangenen 100 Jahre in den Kontext aktueller Erkenntnisse und Klassifikationen zu stellen. Auf diese Weise wird eine kontinuierliche wissenschaftliche Reflexion und Weiterentwicklung der Maya-Epigraphik gefördert, unsere wissenschaftliche Arbeit dabei transparent gemacht und die Brücke zwischen traditioneller und moderner Forschung nachhaltig gestärkt.
Schriftikonographie und Formenkunde
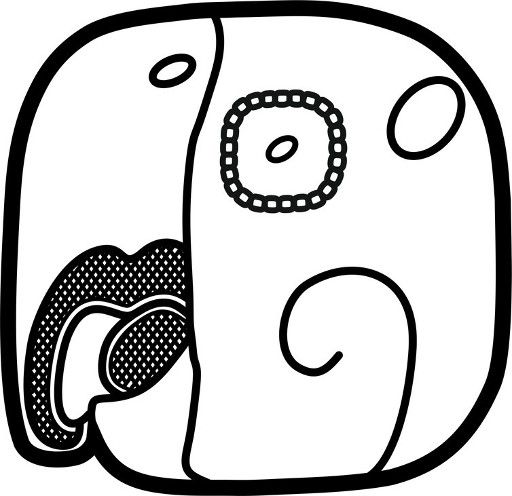
Hieroglyphische Schriftsysteme zeichnen sich durch eine graphische Vielfalt aus, die eng mit kulturellen Motiven und Symbolen verwoben ist und die Grundlage für sprachliche Kommunikation bildet (vgl. Stone und Zender 2011). Ein Zeichen in solchen Systemen ist nicht bloß ein graphisches Element, sondern eine semiotische Einheit, die Bedeutung transportiert. Jedes Zeichen verbindet in Anlehnung an Peirce und Saussure eine materielle Form (den Signifikant (signifiant), also das Graph) mit einem konzeptuellen Inhalt (dem Signifikat (signifié), also der sprachlichen Bedeutung) (Abbildung 1). Die Bedeutung eines Zeichens ergibt sich damit häufig aus der sprachlichen Repräsentation des dargestellten Gegenstands. Der ikonische Charakter – die visuelle Ähnlichkeit zwischen dem Zeichen und seinem Referenten – spielt dabei eine zentrale Rolle, ist jedoch nicht immer eindeutig (Abbildung 6). Viele Zeichen der Mayaschrift besitzen darüber hinaus symbolische oder abstrakte Bedeutungen, die durch kulturelle und historische Entwicklungen geprägt sind. Insbesondere in der Maya-Schrift bleiben die ikonischen Ursprünge zahlreicher Zeichen ungeklärt, was die Interpretation und damit auch die ontologische Kategorisierung weiter erschwert. Dennoch fungieren die Zeichen als Träger sprachlicher, kultureller und ästhetischer Informationen, die sich durch die Analyse von Form, Funktion, Bedeutung und Anwendung herausarbeiten lassen.
 |
 |
 |
 |
 |
 |
| Ikon: Papagei(kopf) | Ikon: Hirsch(kopf) | Ikon: Hand mit Fisch | Ikon: Leguan(kopf) | Ikon: Pyramide | Ikon: ? |
| MO' "Papagei" | CHIJ "Hirsch" → chi (Silbe) | TZAK "greifen; beschwören" | SIH "schenken" |
? |
? |
| Ikonische Bild-Laut-Beziehung |
Semantische Bild-Laut-Beziehung | Offene Bild-Laut-Beziehung[6] |
Ungeklärte Bild-Laut-Beziehung[7] |
Unbestimmte Bild-Laut-Beziehung[8] | |
| Abbildung 6. Typologie der Bild-Laut-Beziehungen in der Mayaschrift (Konzept und Umsetzung: Christian Prager, 2025). | |||||
Die ikonologische Analyse, die sich auf die graphisch-formalen und bildlichen Eigenschaften der Zeichen konzentriert, stellt ein unverzichtbares Werkzeug der epigraphischen Forschung dar. Sie ermöglicht die Identifikation und Kategorisierung von Zeichen und liefert gleichzeitig wertvolle Einblicke in deren kulturelle und semantische Kontexte. Dies ist besonders bedeutsam bei Schriftsystemen wie der Maya- und der ägyptischen Hieroglyphenschrift, in denen Schrift und bildliche Darstellung eng miteinander verflochten sind. Für die Maya-Schrift ist die Untersuchung des ikonischen Ursprungs eines Zeichens eine grundlegende, aber noch in den Anfängen stehende Aufgabe, siehe etwa Andrea Stones und Marc Zenders ikonographische Analyse von 100 Schriftzeichen (Stone und Zender 2011). Sie bildet die Basis, um sowohl die Funktion als auch die Bedeutung der Zeichen im linguistischen und kulturellen Kontext zu entschlüsseln. Die semiotische Analyse ergänzt diese ikonologische Perspektive, indem sie die komplexen Beziehungen zwischen Form, Funktion, Bedeutung und Anwendung systematisch untersucht. Diese Differenzierung ist essentiell, um die Struktur und Dynamik hieroglyphischer Schriftsysteme vollständig zu verstehen.
Formenkundlich-semantische Ansätze der Klassifikation
Ein erster systematischer Versuch, die Elemente der Maya-Schrift zu erfassen, wurde 1931 von William Gates unternommen (Abbildung 7). Sein Katalog, der auf den Hieroglyphen der Maya-Handschriften beruhte, fußte auf einem unveröffentlichten Zeicheninventar von Charles C. Willoughby, das zu Beginn des 20. Jahrhunderts erstellt worden war und heute im Peabody Museum aufbewahrt wird. Gates setzte den Schwerpunkt seiner Systematik auf die ikonographische Bestimmung der Schriftzeichen, um diese anhand ihrer visuellen Merkmale zu ordnen (Tabelle 1). Dabei unterteilte er die Glyphen der Maya-Handschriften in zwölf ikonographisch-semantische Kategorien, darunter Tageszeichen, Monatszeichen, Kalenderzeichen, Himmelsrichtungen, Numerale, Porträts und Tiere. Ziel war es, die ikonische Vielfalt der Schriftzeichen zu systematisieren und eine geordnete Übersicht der Schriftelemente zu schaffen. Trotz seines ambitionierten Ansatzes offenbarte Gates’ Methodik deutliche Schwächen: so verband er in seiner Klassifikation ikonographische und semantische Merkmale mit pragmatischen Anwendungskriterien, ohne eine klare methodische Trennung zwischen diesen Dimensionen zu vollziehen. Diese Vermischung erschwerte eine präzise semiotische und linguistische Analyse der Schriftzeichen erheblich, da weder ihre funktionalen noch ihre semantischen Aspekte systematisch untersucht wurden. Hinzu kam eine komplizierte und teils inkonsistente Numerierung der Elemente, die die Nachvollziehbarkeit seiner Systematik zusätzlich erschwerte und Kritik einfuhr. Aus heutiger Perspektive ist eine methodisch stringente Trennung zwischen Form, Funktion, Bedeutung und Anwendung unverzichtbar, um die komplexen Wechselwirkungen zwischen den graphischen, linguistischen und kulturellen Dimensionen der Maya-Schrift adäquat zu verstehen. Während Gates’ Werk für die frühe Klassifikation der Maya-Schrift ohne Frage einen wichtigen Beitrag leistete, beschränkt sich seine Bedeutung heute weitgehend auf den forschungsgeschichtlichen Kontext. Dennoch beeinflusste sein ikonologischer Ansatz die Maya-Forschung nachhaltig: Die Praxis, Zeichen gemäß ihrer ikonischen Merkmale zu kategorisieren, wurde in nachfolgenden Katalogen aufgegriffen und weiterentwickelt (Rendón und Spescha 1965; Macri und Looper 2003; Macri und Vail 2009; Looper et al. 2022). Im Rahmen unseres aktuellen Katalogisierungsprojekts konnten wir die methodischen Schwächen dieses Ansatzes identifizieren und entscheidend verbessern, indem die ikonologische Interpretation der Graphe von der Katalogisierung selbst getrennt wurde. Durch die differenzierte und systematische Trennung der Dimensionen, Form, Funktion und Bedeutung sowie die Integration moderner semiotischer und linguistischer Methoden haben wir heute ein tiefergehendes Verständnis der komplexen Struktur der Maya-Schrift.
 |
 |
|
Abbildung 7. Seite 11 aus Gates' Originalstudie zu seinem 1931 erschienen Katalog der Mayaschrift (William Gates notes on glyphs, approximately 1898-1940, MSS 279 Series 3 Sub-Series 2, Box: 13, Folder: 5. William Gates papers, MSS 279. L. Tom Perry Special Collections. https://archives.lib.byu.edu/repositories/14/archival_objects/53513. Accessed July 28, 2025). |
Abbildung 8. Originale Karteikarte mit Zimmermanns Studie zur Paläographie und zum Vorkommen der Silbe wa (T130) in der Dresdner Mayahandschrift, angefertigt als Vorbereitung auf seine Publikation von 1956. (Zitiert aus: Günter Zimmermann, Schreiber der Dresdner Mayahandschrift, Manuskript im Nachlass, Abteilung für Altamerikanistik, Universität Bonn.) |
Günter Zimmermann (Abbildung 8) verfolgte in seinem 1956 veröffentlichten Werk über die Hieroglyphen der Maya-Handschriften einen primär formenkundlichen Ansatz. Er definiert dabei den Begriff der „Formenkunde“ in seinem Werk als eine systematische Analyse und Klassifikation der hieroglyphischen Zeichen der Maya-Handschriften (1956:10). Die „formenkundliche Systematik“ beruht dabei auf der genauen Erfassung und Beschreibung der äußeren Gestalt und Struktur der Hieroglyphen, ohne eine vorweggenommene Deutung ihres Inhalts. Dies schließt die Unterteilung der Hieroglyphen in Hauptzeichen und Affixe ein, die nach ihrer Größe, ihrer Position und ihrem funktionalen Bezug zueinander kategorisiert werden. Affixe werden dabei weiter in Präfixe, Superfixe, Postfixe und Suffixe unterteilt, abhängig von ihrer Anordnung in Bezug auf das Hauptzeichen. Der methodische Ansatz der Formenkunde basiert auf der Notwendigkeit, den umfangreichen Formenschatz der Hieroglyphen neutral und möglichst objektiv zu erfassen. Dies erfolgt durch eine numerische Kodierung und eine strukturierte Notation, um jede Hieroglyphe unabhängig von ihrer Bedeutung systematisch zu analysieren und zu kategorisieren. Die „formenkundliche Systematik“ ist somit ein Werkzeug zur Erfassung der visuellen und strukturellen Merkmale der Hieroglyphen, das sich auf die Variabilität der Formen konzentriert, wie sie in verschiedenen Texten und Inschriften auftreten. Diese Systematik vermeidet dabei spekulative Deutungen und fokussiert sich auf die dokumentierte Vielfalt und die räumliche Anordnung der Zeichen. Gemäß diesem Ansatz unterschied Zimmermann, wie bereits zuvor Gates (1931), zwei morphologisch differenzierte Hauptgruppen: breite Hauptzeichen und schmale Kleinzeichen (Affixe), wobei Letztere entlang der vier Seiten eines Hauptzeichens angeordnet sind. Zugleich betonte Zimmermann die fließenden Übergänge zwischen diesen Kategorien und stellte infrage, ob eine derartige Zweiteilung mit den konzeptuellen Vorstellungen der klassischen Maya übereinstimmte (1956:12). Seine Unterteilung der Hauptzeichen in menschliche, tierische und konventionell-ornamentale Formen beruhte auf äußerlichen Ähnlichkeiten, wie beispielsweise Darstellungen von Köpfen und Körperteilabben von Menschen und Tieren. Allographe wurden mit Kleinbuchstaben gekennzeichnet, ein System, das später auch von Thompson übernommen wurde. Diese Klassifikation verbindet Formenkunde mit Bildinterpretation, indem sie semantische und inhaltliche Domänen gleichermaßen berücksichtigt. Zimmermann wies jedoch darauf hin, dass die Zuordnung innerhalb dieser Kategorien häufig schematisch nach rein formalen Kriterien erfolgte, was in einigen Fällen dazu führte, dass semantisch verwandte Zeichen voneinander getrennt wurden. Obwohl diese formenkundlich-semantische Einteilung die systematische Ordnung und das Auffinden spezifischer Zeichen erleichterte, spiegelte sie nicht zwangsläufig deren tatsächliche Herkunft, Bedeutung oder Funktion wider. Diese Einschränkung war jedoch vor dem Hintergrund des damaligen Forschungsstandes nachvollziehbar. Die methodologischen Grenzen des Ansatzes werden insbesondere bei Zeichen deutlich, die zwar formal als abstrakt-ornamental klassifiziert wurden, inhaltlich jedoch Tierformen oder anderen Kategorien zugeordnet werden könnten. Dies gilt etwa für ornamental-abstrakte Zeichen mit gesichtsartigen oder texturalen Merkmalen, die ebenso gut in Kopf- oder Tierzeichen-Kategorien zu finden sind und dort eingeordnet werden könnten. Solche Beobachtungen verdeutlichen die Problematik einer rein formalen Herangehensweise an die Klassifikation von Schriftzeichen. Hinzu kommt, dass ikonographische Elemente nicht eindeutig identifizierbar sind und so der ikonische Inhalt vieler Zeichen weiterhin unklar bleibt, was unterschiedliche Interpretationen und Kategorisierungen begünstigt. Trotz dieser Herausforderungen erleichterte Zimmermanns pragmatische Einteilung in drei formale Kategorien die Übersicht und den praktischen Umgang mit der Vielzahl an Zeichen erheblich, offenbarte jedoch zugleich den dringenden Bedarf nach einer präziseren Differenzierung anhand semantischer, funktionaler und formaler Kriterien. Nur eine solche umfassende Differenzierung ermöglicht es, die komplexen Beziehungen innerhalb des Schriftsystems der Maya adäquat zu erfassen. Zimmermanns Idee einer systematischen und umfassenden Dokumentation der Zeichen – um dies vorwegzunehmen – lässt sich erst jetzt mithilfe digitaler Methoden realisieren. Dynamisch generierbare Zeichentabellen, die sowohl semantische als auch formale Kriterien berücksichtigen, bieten die Möglichkeit einer effizienteren und flexibleren Organisation der Zeichen und ihrer Varianten. Zudem können spezialisierte Zeichenkataloge entwickelt werden, die sich gezielt auf bislang unentzifferte Glyphen konzentrieren und damit einen entscheidenden Beitrag zur weiteren Entschlüsselung der Maya-Hieroglyphen leisten.
|
a |
b |
| Abbildung 9. Faksimiles von Thompsons originalen Karteikarten aus dem Nachlass Thomas Barthels (Universität Tübingen), die als Grundlage für seinen 1962 erschienenen Zeichenkatalog der Mayaschrift dienten. Die Karten enthalten neben einer Zeichnung oder einem Foto der entsprechenden Fundstelle einen Vorkommensnachweis sowie, sofern vorhanden, Datumsangaben – letztere wurden jedoch nicht mit abgedruckt. a) Karte Nr. 9 mit einem Vorkommensnachweis des Zeichens T501. In Thompsons Katalog wird auf die jeweilige Kartennummer verwiesen, sodass ein Abgleich mit den originalen Notizen möglich ist; b) Karte Nr. 435, auf die im Katalog auf Seite 61 Bezug genommen wird. Sie behandelt das Zeichen T236 YAXUN und belegt aus heutiger Sicht, dass Thompsons Klassifikation in diesem Fall nicht korrekt war. Erst die kritische Auswertung seiner Originalkarten ermöglichte eine vollständige Revision seines Standardwerks im Rahmen des vorliegenden Projekts (Bildrechte vorbehalten). | |


Zimmermanns Katalog und seine Methodologie bildeten letztlich die Grundlage für Thompsons Katalog (1962), der ein Inventar von insgesamt 862 Elementen umfasst (Abbildung 9). Diese setzen sich zusammen aus 370 Affixen, 356 Hauptzeichen – darunter Darstellungen von Menschen, Tieren und deren Körperteilen –, 88 Portraithieroglyphen sowie 48 Zeichen mit zweifelhafter Klassifizierung. Eine detaillierte Analyse des Katalogs offenbart, dass Thompson in der Reihenfolge der Zeichen zunächst den Strukturen von Zimmermanns und Gates’ Katalogen folgte. Bei den Hauptzeichen ab Nummer 501 wendet er eine systematische Sortierung an, wobei kalendarischen Hieroglyphen Priorität eingeräumt wird. Nach diesen werden die Zeichen nach formalen Merkmalen wie geschlossenen Umrandungen, Linienelementen, gekreuzten Bändern, Flecken, Punkten oder Schraffierungen geordnet – Merkmale, die Thompson Zimmermanns Kategorie der ornamental-abstrakten Zeichen entnahm. Besondere Aufmerksamkeit galt quadratisch-rechteckigen Graphen mit klar definierter Außenkontur. Innerhalb dieser Systematik sind menschliche Körperteile wie Hände und Beine im Bereich der Nummern 666 bis 714 aufgeführt, während Tiere und ihre Bestandteile die Nummern 731 bis 766 einnehmen. Ab Nummer 788 treten jedoch weitere Tiere auf, was die inkonsistente Strukturierung der Kategorien verdeutlicht. Die Graphe zwischen Nummer 788 und 856 sind inhaltlich wie formal äußerst heterogen und reflektieren die nachträgliche Einfügung neuer Zeichen anstelle einer kohärenten Systematik. Diese methodischen Grenzen, die sich besonders in den späteren Teilen des Katalogs manifestieren, zeigen die Limitationen einer primär formenkundlichen und semantischen Herangehensweise, die Thompson zu Grunde legte. Wesentliche Überarbeitungen und Ergänzungen von Thompsons Inventar wurden in späteren Studien, insbesondere von Nikolai Grube (1990) sowie William Ringle und Thomas Smith-Stark (1996), vorgenommen. Grube führte methodische Korrekturen ein, um die strukturellen Schwächen von Thompsons Ansatz zu beheben. Eine grundlegende Maßnahme bestand in der präzisen Definition von Zeichen als kleinste diskrete Einheiten, die unabhängig voneinander existieren und sich nicht überlappen. Komplexe Zeichen, die aus mehreren Elementen bestehen, wurden als eigenständige Einheiten behandelt, sofern die Kombination dieser Elemente neue Eigenschaften erzeugte. Dieser Ansatz ist methodisch fundiert, doch in Fällen seltener Kombinationen bleibt die Abgrenzung von Eigenständigkeit problematisch. Ein weiteres relevantes Kriterium war die Orientierung asymmetrischer Zeichen, deren Bedeutungsänderung durch Rotation empirisch belegt ist. Dennoch sind nicht alle Kontexte solcher Modifikationen eindeutig, was die Differenzierung erschweren kann. Die traditionelle Unterscheidung zwischen Hauptzeichen und Affixen wurde von Grube ebenfalls aufgehoben, da sich diese als ästhetisch bedingtes, aber funktional nicht konsistentes Konzept erwies. Durch diese Änderung konnten zahlreiche Doppeleinträge in Thompson eliminiert werden, was die Übersichtlichkeit und Nutzung des Katalogs erheblich verbesserte. Grube führte außerdem eine separate Kategorie für Portraithieroglyphen ein, die eine systematische Gruppierung und neue Nummerierung erhielt, die mit Hilfe eines vorangestellten "P" markiert wurde. Sein Inventar der Portraithieroglyphen umfasst 132 Einträge und erweitert damit Thompsons Katalog um über 50 Zeichen. Viele Zeichen in Thompsons Katalog wurden von Grube als Varianten anderer Zeichen erkannt und unter einem einzigen Katalogeintrag zusammengeführt, während andere aufgrund unzureichender Dokumentation aus dem Katalog entfernt wurden. Rund 50 neue, seit Thompsons Publikation entdeckte abstrakte Zeichen wurden ebenfalls ergänzt und mit einem vorangestellten „A“ versehen, um sie von den ursprünglichen Einträgen in Thompson zu unterscheiden.
Diese Ergänzungen stellten einen wesentlichen Fortschritt dar, warfen jedoch die Frage auf, wie diese in Zukunft kohärent in den bestehenden Katalog integriert werden könnten. Die Modifikation des Nummerierungssystems zielte darauf ab, die vorgenommenen Änderungen zu reflektieren, ohne die Kontinuität mit Thompsons Originalsystem zu gefährden. Die Herausforderung war es, den Katalog als dynamisches und methodisch solides Werkzeug weiterzuentwickeln, das gleichzeitig Übersichtlichkeit und Anschlussfähigkeit an frühere Forschungen bewahrt.
Im Rahmen des vorliegenden Projekts wurden diese Prämissen aufgenommen und in den digitalen Zeichenkatalog integriert. Der von Ringle und Smith-Stark (1990) angewendete digitale Ansatz ergänzte Grubes Revisionen und ermöglichte es erstmals, diese systematisch in einen modernen, computergestützten Kontext zu integrieren und über CD-ROMs einem breiten Publikum zur Verfügung zu stellen. Zu diesem Zweck überarbeiteten sie ebenfalls Thompsons Katalog grundlegend, indem sie ebenso die starre Unterscheidung zwischen Hauptzeichen und Affixen aufhoben und stattdessen eine flexible Klassifikation auf Basis graphischer und funktionaler Merkmale einführten. Zeichen werden primär nach formalen Kriterien definiert, wobei auch Modifikationen wie Größenanpassungen berücksichtigt werden. Portraitglyphen und Kopfvarianten erhielten eine neue Nummerierung und spezielle Markierungen wie „H“ für Kopfvarianten. Das Nummerierungssystem wurde ebenfalls wie schon bei Grube - ohne auf dieses Werk Bezug zu nehmen - erweitert, um neue Zeichen zu integrieren, und Thompsons „purgatory group“ wurde ebenfalls klassifiziert. Die von Ringle und Smith-Stark rund sechs Jahre nach Grube (1990) später vorgelegte Revision von Thompson ergänzte Grubes zuvor durchgeführte Revisionen, während sie gleichzeitig die Anschlussfähigkeit an Thompsons System bewahrte (Abbildung 10). Im Rahmen des digitalen Zeichenkatalogs haben wir in Anlehnung an Grube und Ringle und Smith-Stark Thompson ebenfalls erneut revidiert. Um die Konsistenz zu wahren, wurde im Gegensatz zu Ringle und Smith-Stark darauf verzichtet, von Thompson nicht benutzte Nummern mit neu identifizierten Graphen zu besetzen und diese stattdessen in einen neuen Nummernbereich ab der Zahl 1500 eingegliedert.
 |
| Abbildung 10. Visualisierung der Revisionen von Grube sowie Ringle & Smith-Stark am Katalog von Thompson (1962). Rot markiert sind Glyphen aus Thompsons Katalog, deren Klassifikation oder Nomenklatur von Grube bzw. Ringle & Smith-Stark abgelehnt wurden; grün hervorgehoben sind Zeichen, die von allen Autoren unverändert aus Thompsons Originalkatalog übernommen wurden. Konzept und graphische Gestaltung: Christian Prager (2025). |
In den Jahren 1961 und 1963, unmittelbar vor und nach der Veröffentlichung von J. Eric S. Thompsons Zeichenkatalog, erschienen zwei Kataloge zu den Hieroglyphen der Maya-Handschriften (Abbildung 11a-b). Der erste wurde unter der Leitung des Mathematikers Eduard Evreinov (Evreinov et al. 1961) erstellt, der zweite von Yuri Knorozov (1963), wobei Evreinov seinen Katalog auf Knorozov basierte. Beide Werke zeichnen sich durch eine vergleichbare Systematik der Schriftzeichen aus, was sie zu einer wichtigen Grundlage für eine gemeinsame Analyse macht. Besonders das frühere Werk markierte einen Wendepunkt, da es erstmals digitale Methoden in die Erforschung der Maya-Schrift einführte. Erstmals kamen elektronische Rechenmaschinen zum Einsatz, um die komplexe Struktur der Hieroglyphen systematisch zu untersuchen. Texte zweier Maya-Handschriften wurden numerisch kodiert, auf Lochkarten gespeichert und maschinell analysiert. Diese lexikometrischen Untersuchungen umfassten die Analyse von Häufigkeiten, Vorkommen und Kookkurrenzmustern von Zeichen, Zeichenkombinationen, Wörtern und Wortfolgen. Die Ergebnisse wurden anschließend mit sprachstatistischen Daten aus yukatekischen Texten und kolonialzeitlichen Wörterbüchern des 16. und 17. Jahrhunderts abgeglichen, um Hinweise auf mögliche Entzifferungen zu gewinnen. Trotz der methodischen Fortschritte scheiterte der Ansatz letztlich an fundamentalen Fehleinschätzungen. Die maschinellen Analysen konnten die strukturellen und sprachlichen Prinzipien der Maya-Schrift nicht hinreichend erfassen. Daher galt der Versuch bereits kurz nach der Veröffentlichung als gescheitert (Schlenther 1964).
Die beiden in dieser frühen Phase der Mayaschriftforschung entstandenen Kataloge basieren auf einem formenkundlichen Ansatz, wobei die Glyphen in Schmal- und Breitzeichen sowie in Affixe und Hauptzeichen unterteilt sind. Jedes Zeichen wird mit einer eindeutigen numerischen Kodierung versehen, die mit der Nummer 1 beginnt und eine präzise Referenzierung ermöglicht. Die Anordnung der Glyphen im Katalog folgt einem Prinzip der zunehmenden Komplexität, das durch die Anzahl und Gestaltung subgraphemischer und binnengraphischer Elemente definiert wird. Diese kleinsten graphischen Einheiten besitzen keine eigenständige Bedeutung, tragen jedoch wesentlich zum visuellen Erscheinungsbild der Schrift bei. Dieses Klassifikationsprinzip weist deutliche Parallelen zur Organisation der Keilschrift und der chinesischen Schrift auf: Die hierarchische Organisation der Keilschrift nutzt einfache Grundzeichen, die aus wenigen Keilen bestehen, als Bausteine für komplexere Zeichen (vgl. Borger 2010). In der chinesischen Schrift fungieren Radikale als Grundelemente, die graphische und semantische Informationen transportieren. Die systematische Ordnung der Zeichen orientiert sich somit an der Anzahl der Striche und der Position des Radikals (vgl. Xǔ Shèn 1981).
|
a |
b |
c |
| Abbildung 11. Vergleichende Übersicht formenkundlich geordneter Glyphen aus den Maya-Handschriften: a) Auszug aus Knorozovs Katalog mit Schmalzeichen und Affixen (Zeichen 1–110), systematisch nach Rotationsachsen und subgraphemischen Strukturen gruppiert; b) Weitere Graphe aus Knorozovs Systematik, darunter abstrakte und komplexere Zeichen (ab Zeichen 111), geordnet nach äußerer Form und visueller Komplexität (11a und 11b: Bildzitat aus Knorozov 1963:307, 309); c) Idealtypische Graphe aus Tokovinines Zeichenliste (2017), die charakteristische Strukturmerkmale in stilisierter, fontähnlicher Darstellung zeigen und damit eine Weiterentwicklung des Ansatzes von Knorozov darstellen (Bildzitat aus Tokovinine 2017:11). | ||
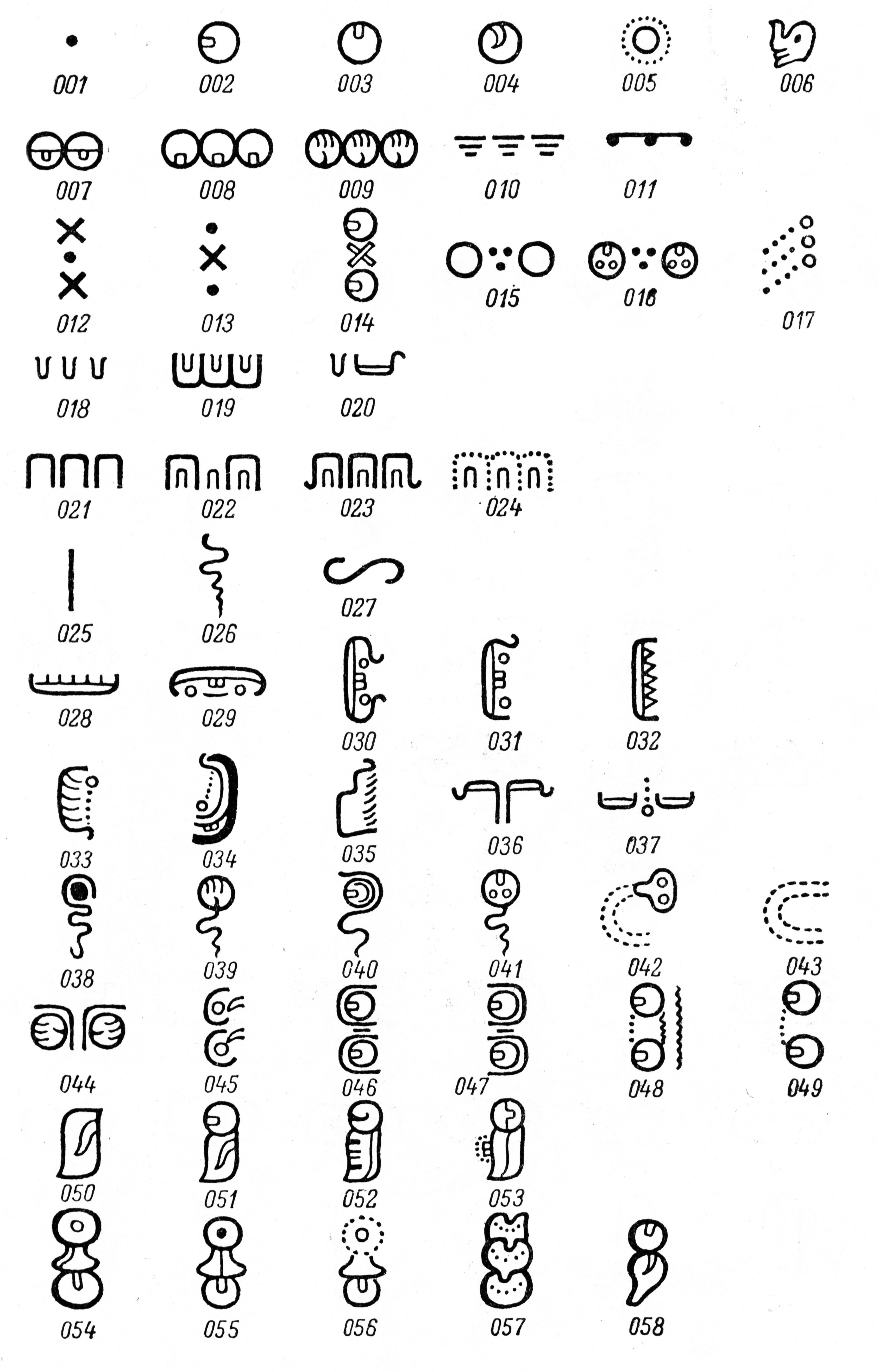

Im Gegensatz zu diesen beiden Schriftsystemen spielt die Semantik in den Katalogen von Knorozov und Evreinov eine untergeordnete Rolle. Stattdessen basiert die Klassifikation primär auf visuellen Ähnlichkeiten. Glyphen werden dabei in Subgruppen eingeteilt, deren Mitglieder durch gemeinsame äußere und innere Merkmale – sogenannte subgraphemische Strukturen – miteinander verbunden sind. Knorozov wendet in seinem Katalog eine systematische Ordnung an, die sowohl formenkundliche als auch funktionale Aspekte berücksichtigt. Schmalzeichen und Affixe (Zeichen 1–110) werden anhand ihrer Rotationsachse gruppiert, wobei zwischen vertikalen und horizontalen Varianten unterschieden wird. Breitzeichen beginnen ab Zeichen 111, zunächst geordnet nach ihrer äußeren Form, beispielsweise geschlossene Umrandungen oder ornamentale Elemente. Menschliche Gesichter werden ab Zeichen 202 katalogisiert, Hände ab Zeichen 258, und tierartige Köpfe ab Zeichen 273. Ab Zeichen 298 folgen Zeichen mit punktierten Umrandungen, während Zeichen mit offenen Umrandungen ab Nummer 310 gelistet werden. Zeichen, die sich keiner dieser Kategorien zuordnen lassen, sind ab Zeichen 318 katalogisiert und weiter in Gruppen unterteilt, die ähnliche Umrisse aufweisen. Knorozovs Katalog umfasst insgesamt 414 Zeichen aus den Maya-Handschriften und wird durch Graphe ergänzt, die ausschließlich in Monumentalinschriften vorkommen. Dadurch erweitert sich das Inventar auf 540 Graphe. Die gleiche Systematik, die für die Handschriften entwickelt wurde, findet auch in der Klassifikation der Monumentalinschriften Anwendung.
Diese formenkundlich-semantischen Familienähnlichkeiten dienen der strukturellen Organisation, unabhängig von der sprachlichen Bedeutung der Zeichen, die zum Zeitpunkt der Erstellung der Kataloge noch nicht vollständig entschlüsselt war. Dieser systematische, auf visueller Verwandtschaft basierende Ansatz wurde später von Alexandre Tokovinine (2017) in seiner Zeichenliste erneut aufgegriffen und weiterentwickelt (Abbildung 11c). Wie bereits Knorozov zuvor, illustrierte auch Tokovinine seinen Katalog mit Zeichnungen prototypischer Graphe, die diagnostische Merkmale der jeweiligen Schriftzeichen hervorheben. Diese idealisierten Darstellungen der Graphe besitzen eine fontähnliche Qualität, da sie wesentliche Elemente wie Form und Binnendetails betonen, die paläographisch nachweisbar sind und in das Design des Zeichens eingeflossen sind. Während die einzelnen Graphe in Thompsons Katalog auf einer beispielhaften Repräsentation von tausenden paläographischen Belegen basiert, entwickelten Knorozov und später Tokovinine idealisierte Graphe, die sämtliche charakteristischen Merkmale in stilisierter Form abbilden. Tokovinines Systematik der Graphe orientiert sich an der Nutzung der Zeichen und unterscheidet dabei präzise zwischen rotierbaren und nicht-rotierbaren Zeichen, zentralen und peripheren Varianten sowie einfachen und zusammengesetzten Glyphen. Dieser Ansatz greift auf methodische Grundlagen zurück, wie sie bereits von Beyer vor rund 100 Jahren eingeführt wurden, und erweitert diese durch eine stärkere Betonung visueller Ähnlichkeiten, struktureller Komplexität und der graphischen Position innerhalb eines Glyphenblocks. Durch diese Herangehensweise schafft Tokovinines Katalog eine auf Knorozov zurückgehende Grundlage für die systematische Analyse der Maya-Schrift und ermöglicht eine präzise Klassifikation und Kontextualisierung der Zeichen. Dieser methodische Ansatz, der sowohl visuelle als auch funktionale Aspekte der Schrift berücksichtigt, wurde im Rahmen unseres Projekts ebenfalls aufgegriffen und umgesetzt, um neue Perspektiven auf die Struktur und Nutzung der Maya-Schrift zu eröffnen. In diesem Zusammenhang wurden in Anlehnung an Knorozov und Tokovinine idealisierte, prototypische Graphe entwickelt, welche die Grundlage unseres digitalen Katalogs bilden, wobei diese in einer künftigen Verwendung auch als Fonts oder Zeichensatz für die Maya-Schrift verwendbar sein könnten.
Ikonographisch-formenkundliche Klassifizierungsansätze
Die systematische Klassifikation der Maya-Schriftzeichen anhand ihres ikonographischen Gehalts wurde erstmals 1965 von Juan José Rendón und Amalia Spescha im Kontext eines Digitalisierungsprojekts der Mayakodizes etabliert (Abbildung 12). Dieses neuartige Verfahren hob sich deutlich von den Ansätzen ihrer Vorgänger – darunter Gates, Zimmermann, Evreinov und Thompson – ab, indem es alphanumerische Klassifikationscodes einführte um die semantische Klasse eines Zeichens zu kodieren. Ein Buchstabe markierte dabei die Zugehörigkeit eines Zeichens zu einer zuvor definierten ikonographischen Gruppe, während eine fortlaufende Nummer die Position innerhalb dieser Gruppe bestimmte. Ziel dieser Kodierung war es, die Analyse der Glyphen sowohl präziser als auch flexibler zu gestalten. Die Zeichen wurden anhand visueller Ähnlichkeiten und Assoziationen in semantische Gruppen eingeteilt und nach ihrem ikonographischen Erscheinungsbild systematisch kategorisiert. Dabei erfolgte eine detaillierte Zuordnung zu spezifischen Kategorien, wie: (A) geschlossene und gefüllte Formen, (B) gruppierte, gekreuzte Formen und Hände, (C) Seile, Schleifen und Knoten, (D) Flügel und Gewebe, (E) Bögen und Federn, (F) Haken und Blumen, (G) kleine Tiere, (H und I) zoomorphe Köpfe, (J–L) abstrakte und anthropomorphe Köpfe, (M) Gesichter sowie (N) Zahlzeichen. Diese Kategorien berücksichtigten formenkundliche und semantische Kriterien gleichermaßen. Gleichzeitig verzichteten Rendón und Spescha als erste darauf, zwischen Hauptzeichen und Affixen zu differenzieren, da lediglich eine formenkundliche, aber keine klare funktionale Trennung dieser beiden Kategorien nachweisbar war.
|
a |
b |
| Abbildung 12. Klassifikation der Maya-Glyphen nach ikonographischen Gruppen im Katalog von Rendón und Spescha (1965). Die Zeichen sind nach visuellen und semantischen Ähnlichkeiten geordnet und erhalten alphanumerische Codes: a) Kategorie C (Seile, Schleifen, Knoten); b) Kategorie I (abstrakte und anthropomorphe Köpfe). Dieses Klassifikationssystem verzichtet bewusst auf die Unterscheidung zwischen Haupt- und Affixzeichen und basiert auf ikonographischen Gemeinsamkeiten, wobei jedem Zeichen eine feste alphanumerische Bezeichnung zugewiesen wird. Trotz der methodischen Neuerung führte die starke Betonung ikonographischer Analogien zu Herausforderungen in der eindeutigen Zuordnung einzelner Zeichen. Bildzitat aus Rendón und Spescha (1965:212, 224). | |
Obwohl dieser Ansatz eine intuitive Orientierung innerhalb des Katalogs ermöglichte, warf er methodologische Fragen auf. Insbesondere eine Klassifikation, die primär auf ikonographischen Analogien basiert, birgt das Risiko subjektiver Interpretationen. Für Zeichen, deren ikonographische Einordnung unklar oder nicht möglich war, blieb die Beschreibung ihrer äußeren Form oft das einzige Klassifikationskriterium. Zur digitalen Verarbeitung erhielten die Glyphen eine dreistellige alphanumerische Kodierung nach dem Format „Buchstabe-Zweistellige Zahl“. Dieses System, das in seiner Struktur an Gardiners Kategorisierung ägyptischer Hieroglyphen erinnert, wurde später auch von Martha Macri, Gabrielle Vail, Mathew Looper und Yuriy Polyukhovich in ihren Katalogisierungen der Maya-Schrift (2003, 2009, 2022) aufgegriffen. Doch auch diese Überarbeitungen litten unter denselben methodischen Herausforderungen wie das ursprüngliche Klassifizierungssystem von Rendón und Spescha. Insbesondere die Unsicherheiten bei der ikonologischen Zuordnung führten bei Macri zu uneinheitlichen Kodierungen ein und desselben Zeichens. Obgleich das System von Rendón und Spescha eine gewisse Flexibilität bot – etwa durch die Ergänzung neuer Glyphen und die Dokumentation fragmentarischer Zeichen mittels Platzhaltern – blieben zentrale Fragen zur hierarchischen Organisation und semantischen Differenzierung der Schriftzeichen weiterhin ungelöst. Der Versuch, Numerierung und ikonographische Merkmale miteinander zu verbinden, verstärkte die interpretativen Unsicherheiten, die die Ordnung des Schriftinventars nachhaltig prägten.
Der umfassendste Versuch, die Schriftzeichen der Maya systematisch auf Grundlage ihrer Ikonographie zu katalogisieren, geht auf Martha Macri zurück (Abbildung 13). Bereits vor mehr als drei Jahrzehnten begann sie mit der Entwicklung eines neuen Katalogs sowie eines digitalen Indexes, der sämtliche dokumentierten Graphe umfassen sollte und 2022 schließlich online veröffentlicht wurde. Zwischen 2003 und 2022 legte Macri gemeinsam mit Gabrielle Vail, Matthew Looper und Yuriy Polyukhovich drei Kataloge mit umfangreicher Forschungsbibliographie vor, die, ähnlich wie das Werk von Rendón und Spescha (1965), auf eine rein numerische Kodierung verzichteten. Stattdessen führten sie ein alphanumerisches System ein, das die Zeichen anhand ikonographischer Merkmale in sechs semantische und acht formenkundliche Kategorien unterteilte. Dieses System sollte nicht nur bestehende methodische und inhaltliche Defizite früherer Kataloge beheben, sondern auch eine stabile Grundlage für die weitere Erforschung der Maya-Schrift schaffen. Die Autoren bewerten Thompsons Katalog aus dem Jahr 1962 zwar als historisch bedeutsam, kritisieren jedoch dessen methodische Unzulänglichkeiten. Sie bemängeln insbesondere die Redundanz und Verwechslung, die aus der Zusammenfassung unterschiedlicher Grapheme unter einer einzigen Nummer resultieren, sowie das Fehlen einer kohärenten Systematik. Die numerische Klassifikation bei Thompson basierte oftmals auf willkürlichen Zuordnungen, die keine Beziehungen zwischen graphisch oder semantisch verwandten Zeichen erkennen ließen. Zudem war es Thompson, wie bei gedruckten Werken üblich, nicht möglich, spätere Fortschritte in der Maya-Epigraphik zu integrieren.
|
a |
b |
c |
| Abbildung 13. Vergleich ausgewählter Zeichen aus verschiedenen Versionen des New Catalog of Maya Hieroglyphs (2003, 2009, 2022) zur Klassifikation der Maya-Schriftzeichen. Das alphanumerische System orientiert sich an Gardiner (1957) und teilt die Zeichen in thematische Hauptkategorien wie Tiere (A), Vögel (B), Körperteile (H), Hände (M), Personen (P) oder übernatürliche Wesen (S). Innerhalb dieser Kategorien differenzieren weitere Buchstaben und Zahlen graphische Varianten. Die abgebildeten Tafeln aus der Ausgabe von 2003 (a), 2009 (b) und 2022 (c) zeigen exemplarisch die Herausforderungen bei der eindeutigen Identifikation und Zuordnung der stark variierenden Zeichenformen, was sich u.a. an unterschiedlichen Kodierungen und Reklassifizierungen einzelner Graphen im Katalog von 2022 zeigt. | ||



Ein zentrales Merkmal des Macri-Katalogs ist das alphanumerische Klassifikationssystem, das sich an Gardiners „Sign List“ aus der Ägyptologie orientiert (1957) und schon 1965 von Rendón & Spescha eingeführt wurde. Dieses Modell teilt die Schriftzeichen der Maya in 14 Hauptkategorien ein, die jeweils durch Buchstaben oder Ziffern gekennzeichnet sind. Zu diesen Kategorien gehören beispielsweise (A) Tiere, (B) Vögel, (H) menschliche Körperteile, (M) Hände, (P) Personen und (S) übernatürliche Wesen. Innerhalb dieser Hauptgruppen werden die Zeichen weiter durch eine zweite Ziffer spezifiziert, die etwa eine bestimmte Tierdarstellung oder Handform identifiziert. Ergänzt wird das System durch eine dritte Ziffer oder einen zusätzlichen Buchstaben, der graphische Varianten eines Zeichens dokumentiert und die Unterscheidung zwischen Allographen ermöglicht. Dieses System soll graphische und funktionale Analysen miteinander verbinden, indem es Varianten eines Zeichens nach ihrem phonemischen oder logographischen Wert gruppiert und gleichzeitig stilistische Unterschiede in zeitlichen oder regionalen Kontexten berücksichtigt. Zudem wird die Flexibilität des Systems betont, da neue Zeichen problemlos integriert werden können, ohne die interne Logik zu beeinträchtigen. Trotz dieser methodischen Ansätze bleibt der Macri-Katalog in der praktischen Umsetzung problematisch. Marc Zender (2006) bemängelt, dass die alphanumerische Systematik zwar als Fortschritt gegenüber früheren Ansätzen positioniert wird, jedoch erhebliche Inkohärenzen aufweist. Die heterogene Ikonographie vieler Zeichen führt dazu, dass sie eigentlich mehreren semantischen Gruppen zugeordnet werden müssten, die Auswahlkriterien werden nicht klar vermittelt. Ein Beispiel hierfür sind menschliche Gesichter, die etwa das Sonnen-Ikon integrieren und daher sowohl in die Kategorie „Personen“ als auch in die Kategorie „himmlische Objekte“ eingeordnet werden könnten. Dieses Problem wird durch die Verstreuung semantisch verwandter Zeichen, wie den „Papageienzeichen“, in den Katalogen von 2003 und 2009 weiter verschärft. Dies deutet darauf hin, dass semantische und inhaltliche Verbindungen innerhalb des Systems unzureichend berücksichtigt wurden.
Ein weiteres grundlegendes Problem ist die graphische Variabilität der Maya-Schrift, wodurch die eindeutige ikonographische Identifikation vieler Zeichen erschwert wird. Diese Herausforderung wird durch die unvollständige und bisweilen inkonsistente Einordnung in das Klassifikationssystem verstärkt. Die 2022 erschienene Revision des Katalogs versuchte, diese Defizite zu adressieren, führte jedoch zu zahlreichen Änderungen sowohl in der Kodierung als auch in der grundlegenden Systematik. Die daraus resultierenden Abweichungen zu den Katalogen von 2003 und 2009 erschweren die Vergleichbarkeit und praktische Anwendung erheblich. Insbesondere das Fehlen einer umfassenden Konkordanz zwischen den verschiedenen Versionen des Katalogs stellt ein gravierendes Hindernis dar. Diese Inkompatibilitäten sind insbesondere im Kontext eines digitalen Indexes, der auf klaren und konsistenten Standards basieren sollte, besonders problematisch. Zusammenfassend bleibt die von Zender formulierte Kritik weiterhin berechtigt. Der New Catalog of Maya Hieroglyphs scheitert trotz seiner erklärten Zielsetzung, eine systematische und verbesserte Grundlage für die Forschung zur Maya-Schrift zu schaffen, an zentralen methodischen und inhaltlichen Defiziten. Die inkonsistente Systematik, das Fehlen einer umfassenden Konkordanz, spekulative Interpretationen und methodische Schwächen beeinträchtigen seine Eignung als verlässliches wissenschaftliches Werkzeug. Letztendlich ist und bleibt Thompsons Katalog aus dem Jahr 1962 trotz der angesprochenen Defizite die wesentliche Grundlage der Maya-Schriftforschung und wird daher im vorliegenden Projekt in einer verbesserten und erweiterten Form angewendet.
Kapitelzusammenfassung
Die Katalogisierung der Maya-Schrift steht vor einer Reihe komplexer Herausforderungen, die sowohl methodologischer als auch technologischer Natur sind. Das Schriftsystem der Maya zeichnet sich durch eine bemerkenswerte Vielfalt an Zeichen und Varianten aus, deren Bedeutungen bis heute nur teilweise entschlüsselt sind. Diese semantische und graphische Variabilität erschwert eine systematische Analyse und erfordert ein hohes Maß an Präzision. Frühere Kataloge bilden zwar bis heute eine wichtige Grundlage, weisen jedoch methodische Schwächen auf. Insbesondere die Vermischung von ikonographischen und semantischen Kriterien führte zu willkürlichen Klassifikationen und erschwerte eine konsistente Systematik. Die traditionelle Trennung zwischen Hauptzeichen und Affixen hat sich als problematisch erwiesen, da viele Affixe ebenfalls Hauptzeichenfunktionen übernehmen können. Diese methodischen Unzulänglichkeiten begrenzen die analytische Aussagekraft und die praktische Anwendbarkeit der bisherigen Kataloge erheblich. Ein weiteres zentrales Problem besteht in der fehlenden Flexibilität gedruckter Kataloge. Sie sind nicht in der Lage, dynamisch auf neue Entdeckungen oder Entzifferungen zu reagieren. Fehlerhafte Klassifikationen, Mehrfachinventarisierungen und unvollständige Datensätze können nicht nachträglich korrigiert werden. Dies gilt insbesondere für die unzureichende Berücksichtigung graphischer Varianten, die in vielen frühen Ansätzen entweder gar nicht oder nur unzureichend dokumentiert wurden. Die visuelle Vielfalt und die ästhetischen wie funktionalen Unterschiede der Zeichen bleiben dadurch weitgehend unerschlossen. Hinzu kommen technologische Defizite früherer Ansätze. Die begrenzten technischen Möglichkeiten und das Fehlen standardisierter, maschinenlesbarer Formate führten dazu, dass die Integration moderner digitaler Methoden in die Forschung ausblieb. Dadurch blieb die Interoperabilität mit anderen Datenbanken und Forschungsprojekten eingeschränkt. Zudem beruhte die ikonographische Klassifikation häufig auf subjektiven visuellen Analogien, was nicht nur zu Ikonsistenzen, sondern auch zu interpretativen Unsicherheiten führte. Die Einordnung der Zeichen war oft ohne eine klare Trennung von semantischen und formalen Kriterien erfolgt, was die Nachvollziehbarkeit und Vergleichbarkeit weiter erschwerte. Ein wesentliches Hindernis für die wissenschaftliche Konsistenz bildet auch die fehlende Konkordanz zwischen den bisher existierenden Katalogen. Unterschiedliche Ansätze und Nummerierungssysteme, etwa von Thompson, Zimmermann oder Rendón und Spescha, sind nur schwer miteinander vergleichbar, was den Austausch und die Weiterentwicklung der Forschung behindert. Diese fragmentierte und inhomogene Grundlage hat es bisher erschwert, eine kohärente und umfassende Systematik für die Maya-Schrift zu etablieren.
Das Projekt "Textdatenbank und Wörterbuch des Klassischen Maya" (TWKM) begegnet den genannten Herausforderungen mit innovativen digitalen Methoden sowie einer klaren Trennung zwischen der graphischen und der semantischen Dimension der Schriftzeichen. Die dynamische Struktur des digitalen Zeichenkatalogs erlaubt es nicht nur, Fehlklassifikationen zu korrigieren und neue Funde zu integrieren, sondern auch graphische Varianten detailliert zu erfassen und in neun Kategorien systematisch zu gliedern. Dies ermöglicht eine präzise Analyse der ästhetischen und funktionalen Vielfalt der Maya-Schrift. Darüber hinaus schafft das Projekt eine umfassende Konkordanz zwischen bestehenden Katalogen, wahrt die historische Integrität von Thompsons ursprünglichem System und erweitert dieses gleichzeitig durch die Integration neuer Entdeckungen. Auf die Erstellung einer umfassenden Bibliographie zu den einzelnen Graphemen wurde bewusst verzichtet, da diese im New Catalog of Maya Hieroglyphs nachvollzogen werden kann. Stattdessen beschränkt sich TWKM auf die Nennung jener grundlegenden Literatur, in der erstmals eine bis heute von der Forschung anerkannte Entzifferung diskutiert und veröffentlicht wurde. Durch die Verknüpfung mit modernen linguistischen und digitalen Analysetools sowie die Bereitstellung der Ergebnisse im Open-Access-Format markiert das Projekt einen bedeutenden Fortschritt in der Erforschung des komplexen Maya-Schrifttums und setzt neue Maßstäbe in der epigraphischen Praxis.
Aufbau, Funktionen und Nutzung des digitalen Zeichenkatalogs
Der vorliegende digitale Zeichenkatalog adressiert die oben genannten Herausforderungen und Defizite früherer Kataloge und stellt ein zentrales Instrument zur systematischen Erfassung, Analyse und Präsentation der Maya-Hieroglyphenschrift dar. Dabei integriert der Katalog die Ergebnisse früherer Arbeiten durch die systematische Nutzung von Konkordanzen, die eine Verknüpfung mit bisher veröffentlichten Katalogen ermöglichen. Diese Verknüpfung gewährleistet, dass bestehende Klassifikationen nicht verloren gehen, sondern in die neue Methodik eingebettet werden. Im Fokus unseres Katalogs steht dabei die semiotische Unterscheidung zwischen Graph – der konkreten visuellen Darstellung – und Zeichen – der abstrakten, semantischen (sprachlichen) Einheit. Diese differenzierte Herangehensweise, die im zugrunde liegenden Metadatenmodell der virtuellen Forschungsumgebung TextGrid verankert ist (vgl. Diehr et al. 2018), ermöglicht eine umfassende Dokumentation sowohl der graphischen Vielfalt als auch der funktionalen Bandbreite der Zeichen. Der digitale Katalog unseres Projekt bricht bewusst mit der traditionellen Kongruenz zwischen Graphikon und Zeichenkodierung, wie sie in den bisherigen Ansätzen vorherrscht. Insbesondere wird Abstand genommen von etablierten Modellen, bei denen der numerische oder alphanumerische Zeichencode zugleich das visuelle Erscheinungsbild und die ikonographische Klasse eines Graphs definiert. In klassischen Katalogen – etwa bei Macri, Vail, Looper und Polyukhovich (2003–2022) oder Zimmermann (1956) – wurden Graphe häufig auf der Grundlage ihrer ikonischen Vorbilder klassifiziert. So erfolgte bei Macri die Klassifikation beispielsweise anhand von Tierformen, wobei Graphe, die Tiere repräsentieren, dem Zeichencode „A“ zugeordnet wurden (insgesamt 369 Elemente). Zimmermann (1956) wählte hingegen eine numerische Systematik, bei der Tierformen ab der Nummer 700 zusammengefasst wurden (mit 63 Elementen). Diese starre, eindimensionale Kategorisierung der Schriftzeichen wird im neuen Katalog durch eine flexiblere und differenzierte Methodik ersetzt. Der neue digitale Katalog analysiert das Graphikon unabhängig von der semantischen Ebene des Zeichens und dessen numerischer Kodierung. Stattdessen erfolgt die formenkundliche und ikonographische Analyse direkt auf der Ebene des Graphs. Sämtliche ikonischen und formenkundlichen Merkmale eines Graphs werden mit Hilfe kontrollierter Vokabulare systematisch verschlagwortet (tagging). Diese Vorgehensweise erlaubt es auch Graphe zu beschreiben, deren ikonisches Vorbild unklar bleibt, wobei sie ausschließlich anhand formenkundlicher Merkmale wie z.B. subgraphemische Elemente klassifiziert werden, ohne sie einer festen semantischen Gruppe zuzuordnen. Letzteres kann dann später erfolgen, sobald die ikonischen Vorbilder entschlüsselt sind. Diese klassifikatorische Flexibilität ermöglicht die Identifikation und Analyse von Ähnlichkeitsclustern, die nicht strikt zwischen formalen und semantischen Kategorien trennen, sondern beide Dimensionen dynamisch miteinander verknüpfen. Das Konzept der Familienähnlichkeit, das auf Ludwig Wittgenstein (1953) zurückgeht, beschreibt die Idee, dass Elemente nicht durch eine einzelne essenzielle Eigenschaft, sondern durch eine Vielzahl überlappender Ähnlichkeiten miteinander verbunden sind – ähnlich wie Mitglieder einer Familie, die gemeinsame, aber nicht identische Merkmale teilen. Die flexible Etablierung solcher Verwandtschaftsbeziehungen zwischen Graphen eröffnet neue Möglichkeiten für die typologische und ikonographische Analyse. Ein zentraler Vorteil des digitalen Katalogs ist die Möglichkeit der parallelen Zuordnung von Graphen zu mehreren ikonographischen Gruppen oder formalen Kategorien. Ein Beispiel hierfür ist das bislang nicht entzifferte Zeichen mit der Nummer 1546 (Abbildung 14). Dieses zeigt in seiner graphischen Realisierung oder Standardform (1546st) den Kopf einer Fledermaus, der als Auge ein Symbol für die Sonne integriert und zusätzlich eine charakteristische Textur aufweist, die als „dunkel-glänzend“ beschrieben werden kann. Während herkömmliche Kataloge dieses Zeichen nur einer einzigen Kategorie zugeordnet hätten, erlaubt der neue digitale Katalog die gleichzeitige Verschlagwortung des Graphs in den Kategorien „Tier“, „Fledermaus“, „Auge“, „Himmelskörper“ und „dunkel-glänzend“. Diese flexible Methodik ermöglicht es, das heterogene Erscheinungsbild von Schriftzeichen und deren graphische Realisierungen adäquat zu erfassen. Gleichzeitig bleibt der Zeichencode selbst starr und unabhängig vom visuellen Erscheinungsbild seines Graphs. Der entscheidende Vorteil dieses dynamischen Ansatzes liegt in der Überwindung starrer Kategorisierungen zugunsten einer nuancierten Analyse. Übergänge zwischen ähnlichen Formen und Funktionen können präzise erfasst werden, was zu einem vertieften Verständnis der graphischen und semantischen Komplexität der Maya-Hieroglyphenschrift führt. Dieser Ansatz leistet nicht nur einen bedeutenden Beitrag zur Weiterentwicklung der formenkundlichen und ikonographischen Forschung, sondern eröffnet auch neue kulturwissenschaftliche Perspektiven auf die kommunikative und kulturelle Variabilität des Schriftsystems der Maya.
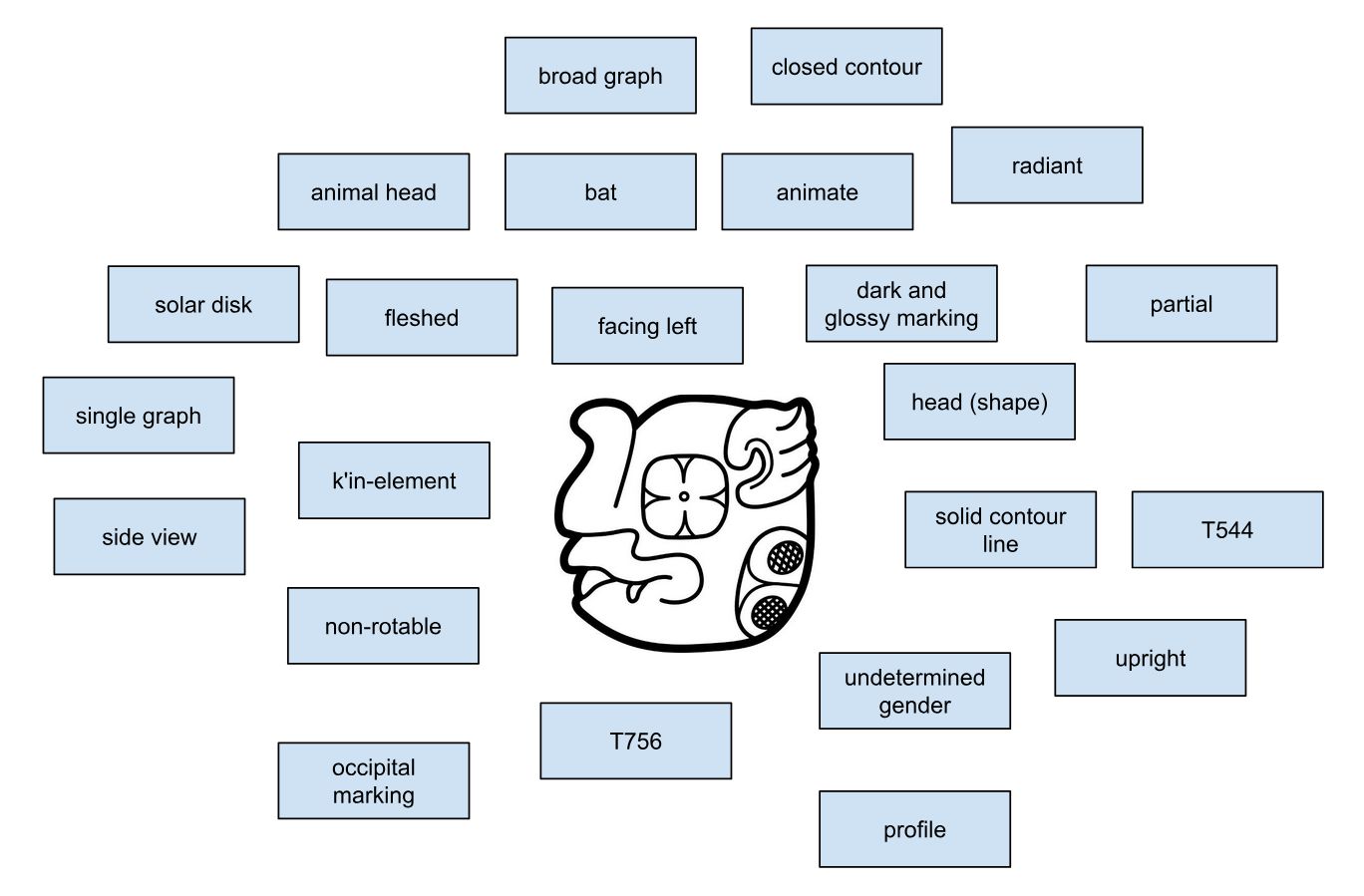 |
| Abbildung 14. Ein Cluster ausgewählter Parameter zur ikonographischen Beschreibungen des Graphems T1546 (Konzept: Elisabeth Wagner, graphische Umsetzung Christian Prager, 2014-) |
Zeichen und Graph im Portal
Das Portal A Digital Catalog of Maya Hieroglyphs stellt eine neue und leistungsfähige Plattform zur Verfügung, die eine gezielte Recherche, Filterung und den Export detaillierter Informationen zu den Zeichen und Graphen der Maya-Schrift in verschiedenen Formaten ermöglicht. Beim Aufruf der Plattform überclassicmayan.org wird standardmäßig das gesamte, aktuelle Graphinventar der Maya-Schrift angezeigt, das über die Navigation unter Graph List zugänglich ist (Abbildung 15). Darüber hinaus stehen die Ansichten Syllabic Grid und Catalog Concordance zur Verfügung, die im weiteren Verlauf erläutert werden. Die Graphe sind in der Standardansicht numerisch aufsteigend von 1 bis n sortiert; die Anzeige kann jedoch über die Sortierleiste im Hauptbereich auch in absteigender Reihenfolge (n bis 1) umgestellt werden. Neben dieser numerischen Ordnung bietet das Portal erweiterte Filter- und Sortiermöglichkeiten. Dazu zählen unter anderem eine alphabetische Sortierung nach sprachlichen Entzifferungswerten (Interpretations), eine Kategorisierung nach ikonographischen Merkmalen (Iconography), eine chronologische Sortierung nach Verwendungszeitpunkten (wahlweise in originaler Maya-Notation oder in westlicher Datierung unter Dating mit Maya oder Western als Auswahlmöglichkeiten) sowie eine Häufigkeitsanalyse der belegten Vorkommen (Occurence Count). Letztere ermöglicht eine Darstellung und Sortierung der Schriftzeichen nach ihrer Belegfrequenz. Diese Funktionen erlauben es, individuelle Graphinventare zu erstellen, die optimal auf spezifische Forschungsbedürfnisse abgestimmt sind. Die einzelnen Graphe werden dabei in einem Raster als Kacheln dargestellt. Jede Kachel enthält standardmäßig die idealisierte Illustration der attestierten Graphvarianten, deren eindeutige alphanumerische Kodierung sowie den lautsprachlichen Entzifferungswert (Interpretation), sofern dieser bekannt ist. Bei nicht entzifferten Zeichen bleibt das entsprechende Feld leer.
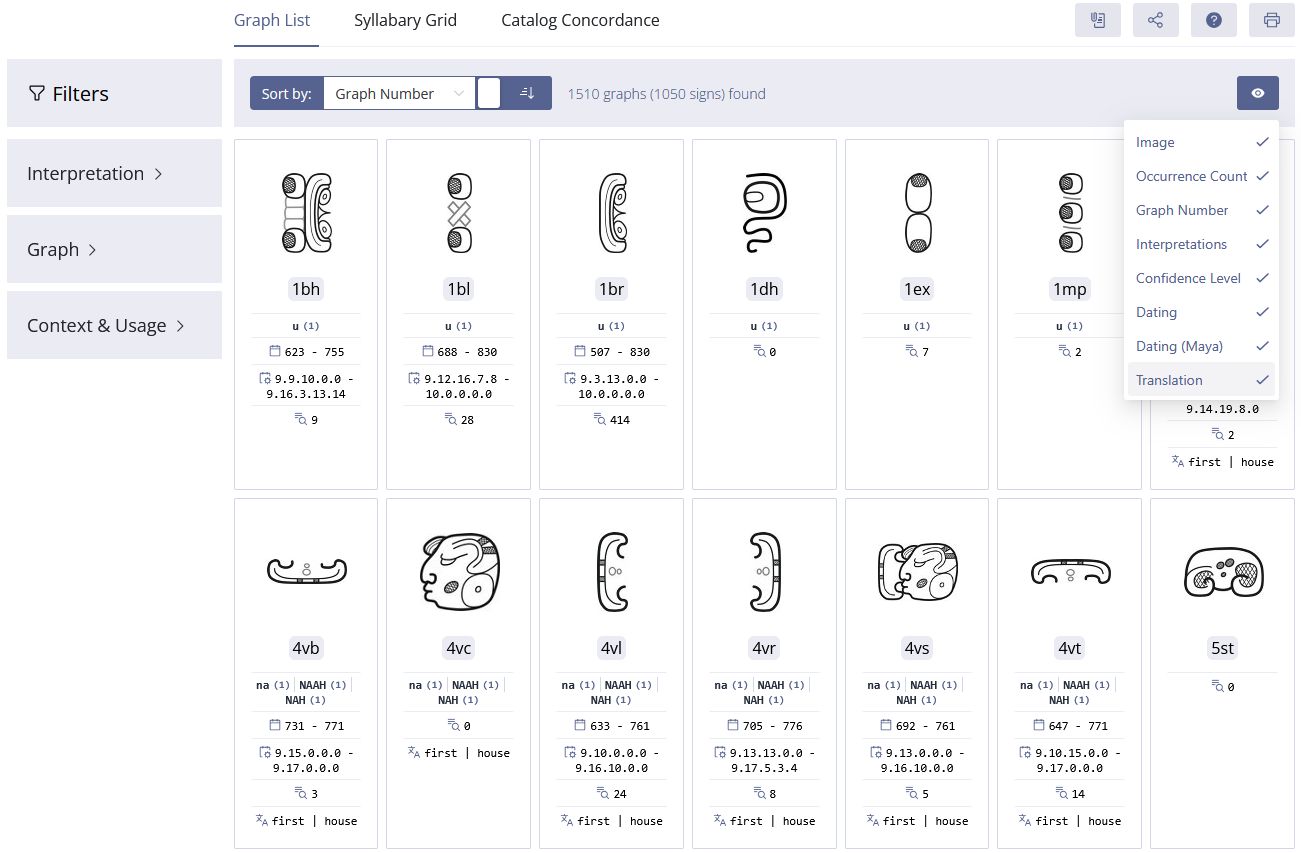 |
| Abbildung 15. Die Abbildung zeigt die Benutzeroberfläche des digitalen Zeichenkatalogs A Digital Catalog of Maya Hieroglyphs, aufgerufen über die Ansicht „Graph List“. Die dargestellte Standardansicht listet die bekannten Maya-Graphe in aufsteigender numerischer Reihenfolge. Jede Kachel enthält eine idealisierte Graphillustration, eine eindeutige alphanumerische Kodierung, lautsprachliche Entzifferungswerte (Interpretationen), Datierungen sowie Angaben zur Belegfrequenz. Über das Augensymbol (Toggle Menü) können zusätzliche Detailinformationen ein- und ausgeblendet werden. Die Plattform bietet vielfältige Filter- und Sortiermöglichkeiten, darunter nach ikonographischen, linguistischen und chronologischen Kriterien. (Graphische Umsetzung: Christian Prager, 2025). |
Das Portal differenziert zwischen Silbenzeichen, die, wie in der epigraphischen Praxis üblich, in fetter Schrift und Kleinbuchstaben dargestellt werden, Logogrammen, die in Großbuchstaben und Fettschrift erscheinen, Zahlzeichen sowie diakritischen Zeichen (Stuart 1988) (siehe Schreib- und Notationskonventionen). Entzifferungen mit höchster Plausibilität (1) werden dabei in Schwarz angezeigt, während unsichere Lesungen (mit einer Sicherheit ab Stufe 2 oder höher) in Rot markiert sind (in Klammern hinter den angezeigten Entzifferungen). Dadurch wird die Verlässlichkeit der Entzifferung auf einen Blick für die Nutzenden angezeigt. Zusätzliche Detailinformationen zu jedem Graph lassen sich über ein Toggle Panel ein- und ausblenden, das durch ein Augensymbol auf der rechten Seite der Sortierleiste aktiviert werden kann (Parameter definiert in Diehr et al. 2019). Diese Informationen umfassen unter anderem die Anzahl der belegten Vorkommen (Occurrence Count), die Lesungssicherheit auf einer Skala von 1 (höchste Sicherheit) bis 8 (geringste Plausibilität) sowie die zeitliche Verortung des Zeichens, die sowohl das früheste als auch das späteste belegte Vorkommen umfasst. Nutzende können hier zwischen der originalen Maya-Notation und der westlichen Datierung wählen. Bei Logogrammen besteht zudem die Möglichkeit, eine grundlegende englische Übersetzung einzublenden, um die semantische Bedeutung der Wurzel zu erfassen. Im Hintergrund gewährleistet eine leistungsfähige technologische Infrastruktur auf Basis der virtuellen Forschungsumgebung TextGrid die kontinuierliche Aktualisierung der Daten. Eine automatisierte Datenpipeline überträgt diese Informationen täglich an das Backend des Zeichenportals. Dadurch bleibt der Zeichenkatalog stets aktuell und bietet eine verlässliche Grundlage für wissenschaftliche Arbeiten, da Neuklassifikationen und neue Entzifferungen, Korrekturen und Löschungen unmittelbar integriert werden können, so dass die Prozesshaftigkeit und Dynamik der Maya-Schriftforschung tagtäglich abgebildet werden kann.
Graphvarianten im Hauptbereich
Die Buchstabenfolge, die den numerischen Zeichencodes in diesem Klassifikationssystem nachgestellt ist, verweist auf spezifische Varianten eines Graphs, die auf der Grundlage morphologischer Merkmale und Segmentierungsprinzipien systematisch kodiert sind und von Christian Prager und Sven Gronemeyer definiert wurden (Prager und Gronemeyer 2018) (Abbildung 16). Dabei werden die Zeichen in unserem System primär durch auf dem Thompson-Katalog aufbauenden numerische Codes erfasst, während ihre graphischen Repräsentationen durch zweigliedrige Buchstabenstrings spezifiziert werden, die an die Zahlenfolge angefügt sind (Abbildung 4 zeigt eine Übersicht der bislang kodierten Variationstypen). Diese Konvention ermöglicht es, unterschiedliche Allographe eines Graphems morphologisch zu identifizieren und konsistent anzuwenden. Die Buchstabensuffixe kodieren somit Merkmale und Variationen eines Graphems. Sie beschreiben beispielsweise, ob ein Zeichen nur vollständig dargestellt und nicht weiter segmentierbar ist („st“ für standard), oder ob es sich zum Beispiel um die obere („bt“ für top) oder untere Hälfte („bb“ für bottom) eines vertikal segmentierbaren zweiteiligen (b in „bt“ bzw. „bb“ für bipartite) Graphs handelt. Darüber hinaus erfassen wir mit diesem System auch komplexere Variationen, wie etwa die Vollfigurrepräsentation („fh“, full-figure human für anthropomorphe Vollfiguren) und Transformationen der Zeichen in belebte Objekte („hc“, head creature für die Kopfvariante eines sonst abstrakt-ornamentalen Graphems), wodurch die graphemischen Eigenschaften umfassend und systematisch dokumentiert werden können. Diese Notationen sind essentiell, um Allographe nicht nur maschinenlesbar zu machen, sondern auch deren Integration in digitale Zeichenkataloge zu erleichtern. Dadurch wird eine konsistente und transparente Analyse der Variantenvielfalt ermöglicht, sodass unterschiedliche Formen eines Graphs vergleichbar werden und ihre spezifischen Positionen innerhalb von Hieroglyphenblöcken nachvollziehbar bleiben. Die den numerischen Zeichen folgende Buchstabencodierung systematisiert Thompsons, Zimmermanns und spätere Versuche, Varianten eines Graphs im Katalog zu erfassen und stellt damit eine methodisch fundierte und standardisierte Herangehensweise dar, um Varianten sowie ihre morphologischen, graphischen und funktionalen Unterschiede im Kontext der Maya-Schrift systematisch zu erfassen und wissenschaftlich zu dokumentieren. Dieses System schafft eine Grundlage für die präzise Analyse und Weiterentwicklung digitaler Kataloge und fördert so das Verständnis der komplexen Struktur der Maya-Schrift.
 |
 |
| Abbildung 16. Die Abbildung veranschaulicht die systematische Klassifikation und Kodierung von Varianten einzelner Maya-Grapheme im digitalen Zeichenkatalog A Digital Catalog of Maya Hieroglyphs. Gezeigt wird die differenzierte Erfassung von Allographen durch alphanumerische Codes, bestehend aus einer numerischen Hauptkennung (z. B. 630 und 68) und einem nachgestellten Buchstabenpaar, das morphologische und graphische Varianten beschreibt. Diese Suffixe (z. B. „bh“, „bl“, „fh“) codieren spezifische formale Eigenschaften und ermöglichen eine standardisierte Dokumentation von Variationen wie Segmentierung, Position innerhalb eines Blockes oder stilistische Transformationen (z. B. anthropomorphe Köpfe oder Vollfiguren). Die Darstellung illustriert die Vielfalt der Variantenbildung innerhalb eines einzelnen Zeichentyps und unterstreicht die Relevanz dieser differenzierten Notation für die epigraphische Analyse und digitale Verarbeitung der Maya-Schrift. Im digitalen Katalog kann gezielt danach gesucht bzw. gefiltert werden. | |
Schreib- und Notationskonventionen
Die Transliteration klassischer Maya-Inschriften im digitalen Zeichenkatalog basiert auf einer phonetisch differenzierten Orthographie, welche die im Klassischen Maya relevanten Konsonanten- und Vokalphoneme systematisch abbildet: Das phonemische Inventar umfasst fünf Vokale (a, e, i, o, u), fünfzehn einfache Konsonanten (b, ch, h, j, k, l, m, n, p, s, t, tz, w, x, y) sowie fünf glottalisierte Konsonanten (ch’, k’, p’, t’, tz)’ (vgl. England und Elliott 1990). Ein glottalisierter stimmhafter Plosiv /b’/, wie er in Teilen der Literatur verwendet wird (vgl. Wichmann 2004), bleibt in dieser Notationspraxis unberücksichtigt, da ein bedeutungsunterscheidender Kontrast zwischen /b/ und /b’/ im klassischen Sprachgebrauch bislang nicht nachgewiesen ist (vgl. Martin und Grube 2008:12).
Typographisch folgt die Transkription etablierten epigraphischen Konventionen (Stuart 1988) (Abbildung 17), die drei funktionale Zeichentypen unterscheiden: Logogramme werden bei der Transliteration in Großbuchstaben dargestellt (HUL "ankommen"). die Transkription, also die sprachliche Interpretation, wird in Kursivschrift abgebildet (hul "ankommen"; Silbenzeichen erscheinen in Kleinbuchstaben la); Diakritika, wie etwa die Verdoppelung von Silbenzeichen (z.B. 2ka-wa für [ka]-ka-wa), werden hochgestellt notiert. Diese typographische Unterscheidung erleichtert die funktionale Einordnung der Zeichen und trägt zur Lesbarkeit philologischer Transkriptionen bei. Ergänzend wird im digitalen Katalog mit einer farbcodierten Markierung der Grad philologischer Sicherheit kenntlich gemacht: Während schwarz gesetzte Transkriptionen allgemein akzeptierte Entzifferungen mit höchster Entzifferungsplausibilität repräsentieren, signalisiert rote Schrift hypothetische oder umstrittene Deutungen. Auf diese Weise wird der epistemische Status einzelner Zeichen sichtbar gemacht und der prozesshafte Charakter epigraphischer Entzifferung reflektiert.
 |
 |
 |
| Logogramm | Phonogramm | Logogramm |
| HUL | la | ANTZ |
| hul | antz | |
| "ankommen" | "Mutter" | |
| Abbildung 17. Exemplarische Darstellung der typographischen Differenzierung verschiedener Zeichentypen in der Transkriptionspraxis klassischer Maya-Inschriften: Logogramme wie HUL („ankommen“) und ANTZ („Mutter“) erscheinen in Großbuchstaben, während ihre sprachliche Interpretation kursiv in Kleinbuchstaben (z. B. hul, antz) wiedergegeben wird – die unsichere Transliteration ANTZ wird in Rot markiert. Das Phonogramm la hingegen wird ausschließlich in Kleinbuchstaben dargestellt. Diese Konvention verdeutlicht die funktionale Unterscheidung von Zeichenformen im digitalen Katalog und wird ergänzt durch eine semantische Übersetzung in Anführungszeichen. Die Abbildung illustriert damit zentrale Prinzipien der epigraphischen Notation und macht die visuelle Kodierung von Graphemen, Transkription sowie Bedeutung nachvollziehbar. (Konzept und Umsetzung: Christian Prager, 2025). | ||
Die klassische Maya-Schrift selbst basiert auf einem logosyllabischen Schriftsystem, dessen Struktur auf Silbenzeichen beruht und das phonetisch relevante Merkmale teils direkt, teils indirekt abbildet. Orthographische Regularitäten wie Vokalharmonie und Disharmonie spielen dabei eine zentrale Rolle (Houston et al. 1998; Lacadena García-Gallo und Wichmann 2004). Vokalharmonische Schreibungen – etwa ch’o-ko für ch’ok „jung“ oder tzu-lu für tzul „Hund“ – verwenden gleiche Vokale in aufeinanderfolgenden Silbenzeichen und gelten als Indikatoren für einfache, kurze Vokale. Dagegen verweisen vokaldisharmonische Schreibungen wie u-si-ja für usiij „Geier“ auf phonetisch komplexe Silbenkerne, beispielsweise lange Vokale (VV), glottalisierte Vokale (Vʼ) oder Vokale mit eingeschobenem Konsonanten (Vh). Insbesondere der Einschub eines /h/ bleibt im Schriftbild der klassischen Inschriften unmarkiert. Das Vorhandensein von Vh-Silbenkernen führte zur Bildung von Konsonantenclustern, die im klassischen Maya offensichtlich nicht geschrieben werden konnten, so dass das /h/ als schwaches Phonem, das in der Schrift ohnehin unterrepräsentiert wurde, in Silbenschreibungen unberücksichtigt blieb. Ein häufig zitiertes Beispiel ist ba-la-ma, das formal als vokalharmonisch erscheint, aber phonetisch als bahlam „Jaguar“ rekonstruiert wird. In solchen Fällen suggeriert die graphische Harmonie eine Silbenstruktur, die das tatsächlich gesprochene, jedoch nicht geschriebene h im Silbenkern verschleiert. Die diachronen Reflexe dieses Lautsegments lassen sich in modernen Maya-Sprachen nachweisen,insbesondere im yukatekischen Maya, das unterschiedliche Vokalqualitäten bewahrt hat. Im Yukatekischen Maya hat sich an der Stelle des *VhC des Klassischen Maya ein Hochton erhalten. Auch die Sprachen Ch’ol, Choltí und Ch’orti’ haben Reflexe auf die Sequenz *VhC aus dem proto-Maya, in vielen Kontexten bewahrt.
In der epigraphischen Praxis hat sich daher die Konvention etabliert, ein solches in den Inschriften nicht markiertes, aber sprachhistorisch rekonstruierbares /h/ in der Transliteration sowie Transkription explizit zu kennzeichnen – etwa in Formen wie BAHLAM „Jaguar“, TIHL „Tapir“ oder K’IHNICH „Sonnengott“. Besonders deutlich wird die Relevanz dieser Rekonstruktion in der Unterscheidung der Lemmata ik' „Wind“ und ihk' „schwarz“, deren Grapheme T503 IK' "Wind" und T95 IK' "schwarz" in keiner bekannten Inschrift sich gegenseitig substituierbar verwendet werden (Abbildung 18). Dieser Befund verweist neben der Existenz eines semantischen auch auf einen phonemischen Unterschied, der durch kontextuelle Verteilung und sprachvergleichende Evidenz plausibel gemacht werden kann und nur in der syllabischen Realisierung nicht direkt realisiert ist.
 |
 |
| Logogramm | Logogramm |
| IK' | IK' |
| ik' | ihk' |
| "Wind" | "schwarz" |
| Abbildung 18. Graphischer Kontrast zwischen den homophonen Logogrammen T503 für IK' "Wind" und T95 IK' "schwarz" (Konzept und Umsetzung: Christian Prager, 2025). Eine semantische Unterscheidung kommt bei der Transkription zum Ausdruck. (Konzept und Umsetzung: Christian Prager, 2025). | |
Die Interpretation vokaldisharmonischer Schreibungen bleibt kontrovers. Houston, Stuart und Robertson (1998) argumentieren, dass solche Graphemfolgen typischerweise als orthographische Marker für phonetische Komplexität fungieren – etwa zur Anzeige von Langvokalität oder Glottalisierung – auch dann, wenn der disharmonische Vokal nicht gesprochen wurde, sondern lediglich ein visuelles Signal darstellt. Da die Diskussion über die Markierung langer und glottalisierter Vokale in der Schrift noch nicht abgeschlossen ist, folgt die in diesem Katalog angewandte Transkriptionspraxis einem bewusst konservativen Ansatz: Phonetisch komplexe Vokale werden konsequent durch Verdoppelung des Vokals (aa, ee, ii, oo, uu) wiedergegeben, während auf die Schreibung glottalisierter Vokale verzichtet wird, so lange die epigraphische Realisierung dieser Vokalqualitäten noch in der Diskussion ist. Glottalisierte Vokale gelten in dieser Praxis nur dann als gesichert, wenn sie in harmonischen Schreibungen eindeutig als Vokalverdoppelung erscheinen – etwa pa-a für paʼ „Spalt“ le-e für leʼ „Falle“, oder mo-o für mo' “Papagei”. Die Schreibung komplexer Vokale mit der Verdoppelung des Vokals entspricht der pragmatischen Schreibpraxis für das kolonialzeitliche yukatekische Maya.
Diese Konventionen spiegeln den methodischen Anspruch wider, einerseits die strukturellen Eigenschaften der Maya-Schrift ernst zu nehmen und andererseits keine lautlichen Annahmen zu treffen, die über das im Schriftbild Belegbare hinausgehen. Die Balance zwischen philologischer Präzision und schriftlinguistischer Zurückhaltung bildet die Grundlage einer reflektierten epigraphischen Notation für den digitalen Zeichenkatalog.
Filter- und Suchfunktionen in der Sidebar
Suche und Filter von Zeichen
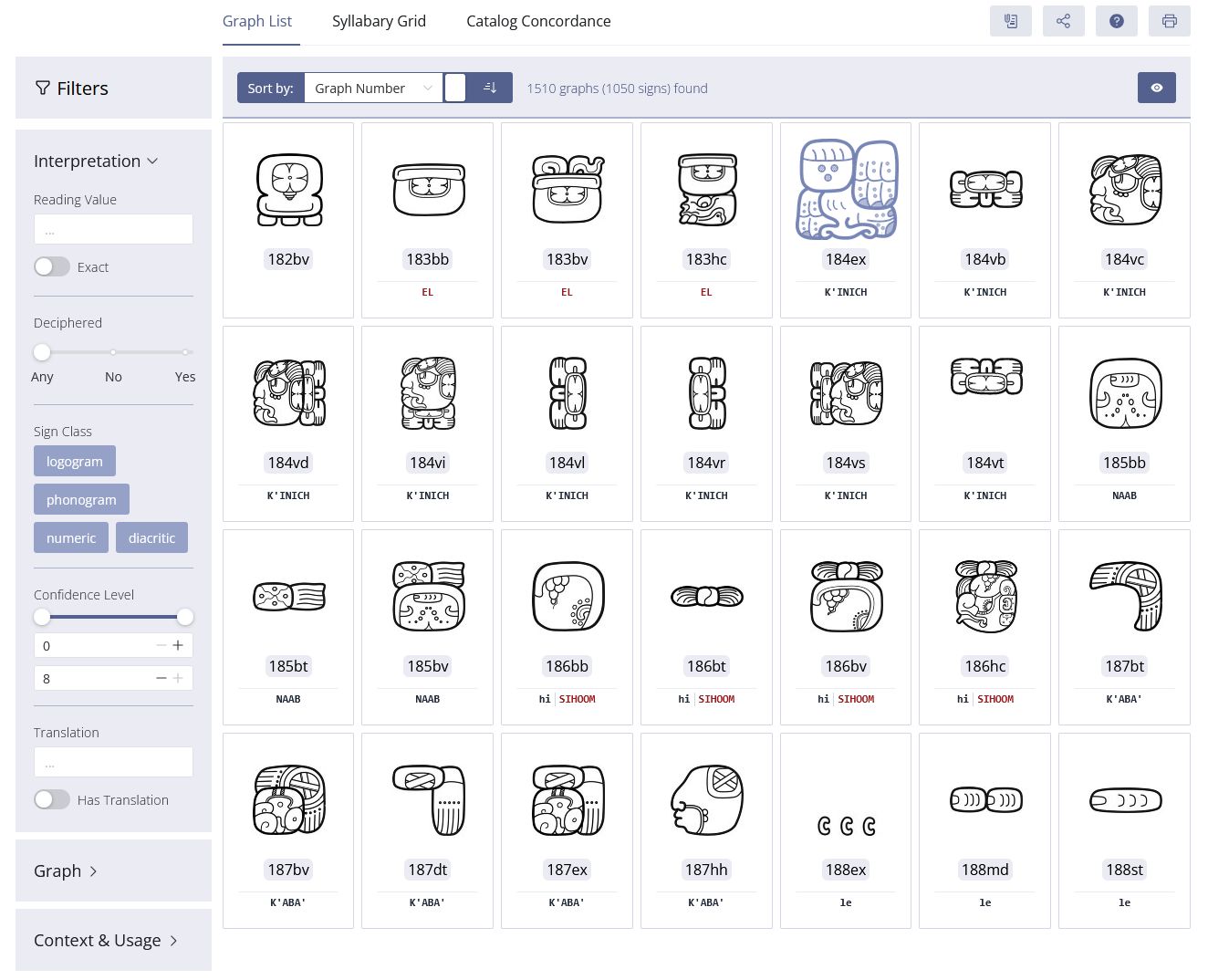 |
| Abbildung 19. Filter und Suchfunktionen für den Bereich Zeichen bzw. Interpretation. |
Die Sidebar bietet drei spezialisierte Filter- und Suchbereiche, die eine gezielte Sortierung, Durchsuchung und Visualisierung von Zeichen, Graphen und inhaltlichen Parametern der Maya-Schrift ermöglichen (Abbildung 19). Unter der Filterfunktion Interpretation erlaubt das Eingabefeld Reading Value die Suche nach Zeichen und Graphen anhand ihres exakten oder approximativen sprachlichen Lautwerts. Die entsprechenden Ergebnisse werden anschließend im Hauptbereich der Anwendung dargestellt. Ein weiterer Filter (Deciphered), stellt über einen Schieberegler drei Auswahlmöglichkeiten bereit: Any (alle Zeichen), Yes (nur entzifferte Zeichen) und No (noch unentzifferte Zeichen). Diese Funktion ermöglicht die Erstellung spezifischer Zeichen- und Graphlisten, die entweder bereits gesicherte sprachliche Lesungen oder noch unbestimmte Werte enthalten und somit einen unkomplizierten Überblick über den Forschungs- und Entzifferungsstand einzelner Zeichen geben. Ergänzend dazu ermöglicht der Filter Sign Class eine Kategorisierung der Zeichen und Graphe nach ihrer funktionalen Rolle, darunter Logogramme (Logogram), Phonogramme (Phonogram), Numerale (Numeral) und Diakritika (Diacritic). Die zugehörigen Filter erlauben eine gezielte Auswahl einzelner oder kombinierter Kategorien und bieten eine systematische Übersicht über bestimmte Zeichentypen oder die gesamte Struktur der Maya-Schrift. Die Plausibilität linguistischer Entzifferungshypothesen lässt sich im digitalen Zeichenkatalog der Maya-Schrift mithilfe eines Schiebereglers als Confidence Level anzeigen, der Bewertungen von 1 (höchste Plausibilität) bis 8 (niedrigste Plausibilität) umfasst. Grundlage dieser Abstufung ist eine Bewertung, die historische Quellen, linguistische Analysen und epigraphische Vergleiche methodisch kombiniert (Houston 2001:8; Zender 2017; Diehr et al. 2019). Ein zentraler Referenzpunkt ist dabei das kolonialzeitliche Manuskript von Diego de Landa (1566) aus dem Jahr 1566, das als heuristische Quelle und zeitgenössischer Augenzeugenbericht essenzielle Hinweise zur phonetischen Struktur der Maya-Schrift bietet. Landas Manuskript dokumentiert die Aussprache von über drei Dutzend Zeichen und hat sich dadurch als unverzichtbare Grundlage für die Entzifferung etabliert. Ein weiterer entscheidender Faktor zur Ermittlung der Plausibilität einer Lesung ist die Analyse logographischer und allographischer Substitutionen – das heißt, die systematische Ersetzung von Zeichen durch semantisch oder graphisch verwandte Varianten (siehe Diehr et al. 2019). Solche Substitutionsmuster erlauben zuverlässige Rückschlüsse auf mögliche Zeichenwerte und alternative Schreibweisen, insbesondere wenn sie konsistent und regelmäßig in verschiedenen epigraphischen Kontexten auftreten. Eng hiermit verbunden ist die Position eines Zeichens innerhalb eines Wortes, da phonotaktische Beschränkungen der Maya-Sprachen dazu beitragen, den Raum plausibler phonologischer Interpretationen zu begrenzen. Ergänzend fließen ikonische Übereinstimmungen und Objektbezüge sowie lexikalische Nachweise eines Zeichens in zentralen Maya-Tieflandsprachen in die Bewertung ein. Diese linguistische und ikonographische Verankerung stärkt die Glaubwürdigkeit vorgeschlagener Lesungen zusätzlich. Besonders wichtig ist dabei die kontextuelle Kohärenz einer Hypothese, die dann als plausibel bewertet wird, wenn sie nicht nur isoliert sinnvoll ist, sondern auch im syntaktischen und semantischen Zusammenhang des gesamten Textes schlüssige Bedeutungen liefert. Die Robustheit einer Hypothese steigt zudem signifikant, wenn sie in verschiedenen Textquellen mehrfach bestätigt werden kann. Methodisch folgt dieser Ansatz dem Prinzip der Bayes’schen Wahrscheinlichkeitsgewichtung konkurrierender Hypothesen, bei dem die Plausibilität einer Lesung nicht nur isoliert, sondern im syntaktisch-semantischen Kontext des Gesamttextes sowie in Abgleich mit weiteren Belegen aus verwandten Texten bewertet wird. Wie Colin Howson und Peter Urbach (2006) betonen, erlaubt dieses Verfahren eine systematische Revision der Wahrscheinlichkeiten von Hypothesen anhand neuer Evidenz und kontextueller Kohärenz. Dabei wird die ursprüngliche Wahrscheinlichkeit (die Prior-Wahrscheinlichkeit) einer Lesung systematisch anhand neuer Evidenz (Daten) aktualisiert. Die Bayes’sche Methode erlaubt es, Hypothesen miteinander zu vergleichen, indem sie berücksichtigt, wie gut eine Lesung mit beobachteten linguistischen, grammatischen und kulturellen Kontexten übereinstimmt. Die Plausibilität steigt somit, je höher die Übereinstimmung zwischen Hypothese und Evidenz ist, und verringert sich entsprechend, wenn widersprüchliche Daten auftreten. Durch diesen iterativen, systematischen Bewertungsprozess lassen sich alternative Interpretationen schrittweise eingrenzen und konkurrierende Hypothesen transparent vergleichen. Die in diesem Projekt resultierende Einstufung von sprachlichen Entzifferungen auf einer Skala von 1 bis 8 gewährleistet nicht nur intersubjektive Nachvollziehbarkeit, sondern ermöglicht auch eine fundierte und nachvollziehbare Hierarchisierung konkurrierender Entzifferungsvorschläge (Diehr et al. 2018; Diehr et al. 2019).
In der Filter- und Suchkategorie translation kann gezielt nach der englischen Übersetzung einzelner Logogramme gesucht oder eine vollständige Liste aller Logogramme mit verfügbaren Übersetzungen abgerufen werden. Um die Übersetzungen innerhalb der Benutzeroberfläche anzuzeigen, muss im Toggle-Menü (zugänglich über das Augensymbol) die Option Translation aktiviert werden. Die Übersetzungen erscheinen daraufhin unterhalb der graphischen Darstellung und reflektieren den aktuellen Forschungsstand zur semantischen Bedeutung des jeweiligen Logogramms. Für eine gezielte Filterung aller Logogramme mit vorhandener Übersetzung ist der Umschalter has translation zu aktivieren. Die gefilterte Ergebnisliste wird anschließend im Hauptbereich der Anwendung angezeigt. Darüber hinaus kann die aktuelle Suchanfrage mitsamt aller Filtereinstellungen über einen permanenten Suchlink (Permalink) gespeichert werden (Abbildung 20). Dabei wird der Zustand der Filter in der URL codiert, sodass er beim erneuten Aufruf des Links automatisch wiederhergestellt wird. Alternativ besteht die Möglichkeit, die gefilterte Ansicht als HTML-basierte PDF-Datei zu exportieren. WICHTIG: Um gespeicherte Ergebnisse beim nächsten Aufruf der Datenbank zu entfernen, muss der gespeicherte Suchlink (siehe Abbildung 20) gelöscht werden. Andernfalls kann es vorkommen, dass die Datenbankabfrage unvollständige oder unerwartete Ergebnisse liefert.
 |
| Abbildung 20. Die Benutzerbenachrichtigung beim Aufruf eines gespeicherten Permalinks im digitalen Zeichenkatalog. Die Meldung weist darauf hin, dass die URL zuvor definierte Filtereinstellungen und Ansichtsoptionen enthält und bietet die Möglichkeit, diese Konfiguration erneut zu laden. Wird diese Option nicht bewusst zurückgesetzt, kann es zu unvollständigen oder unerwarteten Ergebnissen in der Datenbankabfrage kommen. |
Suche und Filter von Graphen
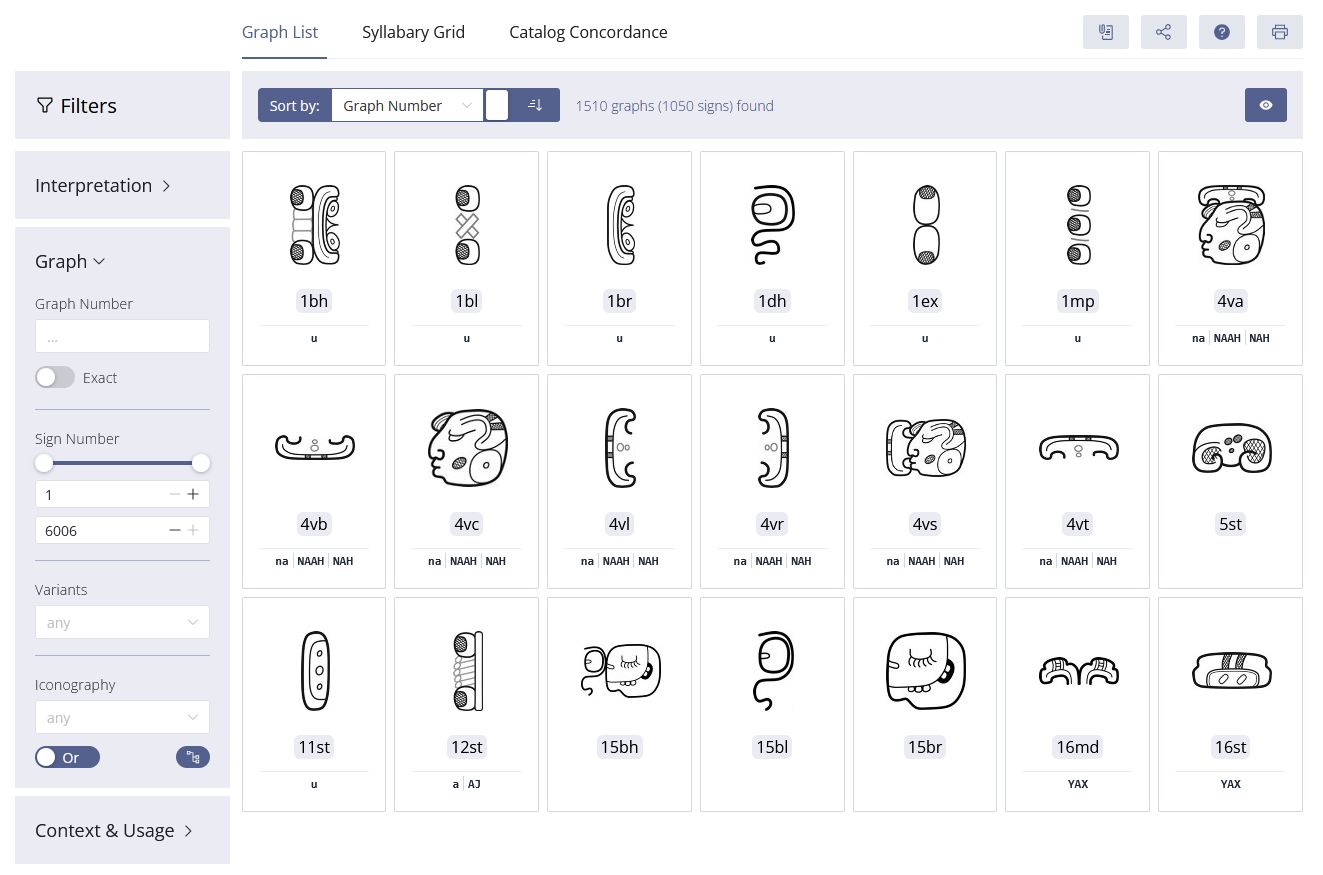 |
| Abbildung 21. Such- und Filterfunktionen für den Bereich Graph. |
Viele Graphe der Zeichen haben ihren Ursprung in gegenständlichen Darstellungen und bleiben in ihrer Form oft visuell erkennbar. Die ikonographische Analyse ist daher ein essenzielles Werkzeug zur Entzifferung und Interpretation der Schrift. Da zahlreiche Zeichen direkt auf Objekte, Lebewesen oder Handlungen referieren, ermöglicht die Untersuchung ihres ikonischen Ursprungs meist Rückschlüsse auf ihre ursprüngliche sprachliche Bedeutung (Abbildung 6). Darüber hinaus erlaubt die ikonographische Analyse die Nachverfolgung stilistischer Entwicklungen und Stilisierungen, die sich im Verlauf der Schriftgeschichte vollzogen haben. Über die bloße Identifikation von Zeichen hinaus ist sie auch deshalb von zentraler Bedeutung, weil sie das enge Wechselspiel zwischen Schrift und bildlichen Darstellungen der Maya-Kunst sichtbar macht. In bildlichen Maya-Darstellungen sind Hieroglyphen häufig als integrale Bestandteile von Figuren, Gewändern oder Objekten eingebettet, wodurch sie nicht nur als sprachliche, sondern auch als visuelle Zeichen fungieren. Dies verdeutlicht, dass die Maya-Schrift nicht allein der Kommunikation diente, sondern auch der Inszenierung von Macht, Mythologie und Identität. Die ikonologische Perspektive innerhalb unseres Zeichenportals trägt dazu bei, Maya-Texte nicht nur als linguistische Phänomene zu verstehen, sondern auch als Bestandteile eines umfassenden semiotischen Systems. Im Kontext unseres Zeichenkatalogs wurde ein System entwickelt, das es ermöglicht, die Graphe der Mayaschrift granular ikonographisch zu beschreiben – basierend auf den Erkenntnissen aus 150 Jahren Mayaforschung. Mithilfe kontrollierter Vokabulare lassen sich die Graphe mittels Tagging ikonographisch und formal erschließen. Dadurch können die durch Fachwissenschaftler manuell erstellten Annotationen genutzt werden, um formal ähnliche bzw. ikonographisch verwandte Graphe zu clustern (Abbildung 14). So entsteht ein Zeichen- und Graphkatalog, der nach allen verfügbaren Kriterien sortier- und filterbar ist.
Im Rahmen der Portalentwicklung haben wir diese Anforderungen berücksichtigt und unter der Kategorie Graph ein Set spezifischer Filter- und Abfragefunktionen implementiert, die im Folgenden kurz erläutert werden (Abbildung 21). Im Eingabefeld Graph Number können Nutzende gezielt nach einem Graph anhand seines numerischen Codes suchen. Die Suche kann entweder exakt oder trunkiert erfolgen. Darüber hinaus ist eine Bereichssuche integriert, die es ermöglicht, eine Spanne von Graphnummern festzulegen, etwa alle Graphe im Bereich 50 - 100. Im ersten Eingabefeld kann ein Ausgangswert definiert werden, während im zweiten Feld ein Endwert gesetzt wird, sodass alle Zeichen innerhalb dieses Bereichs angezeigt werden. Diese Funktion erleichtert die gezielte Navigation durch den Zeichenkatalog und unterstützt das Auffinden zusammenhängender oder verwandter Graphe. Ein zusätzlich eingebauter Schieberegler oberhalb der Eingabefelder erlaubt eine intuitive Anpassung des Wertebereichs. Durch Verschieben der Regler nach links oder rechts kann die Auswahl dynamisch verändert werden, ohne die numerischen Werte manuell eingeben zu müssen. Dies bietet eine benutzerfreundliche Möglichkeit, schnell und effizient nach bestimmten Graphen oder Graphbereichen zu suchen. Im Eingabefeld Variants mit vordefinierten zweistelligen alphabetischen Werten können Graphe, die einen gemeinsamen Segmentierungsmodus aufweisen, aus dem Katalog gefiltert und angezeigt werden. Dazu gehören beispielsweise Graphe, die horizontal oder vertikal segmentiert sind, pars-pro-toto-Varianten oder ikonographische Transformationen wie Anthropo- bzw. Zoomorphisierung oder Vollfiguren.
 |
| Abbildung 22. Ansicht des Expertenmodus zur ikonographischen Filterung im digitalen Zeichenkatalog. Die hierarchisch strukturierte Oberfläche erlaubt eine gezielte Suche nach formalen und motivischen Merkmalen der Graphe. Über aufklappbare Menüs lassen sich spezifische Subkategorien wie Tierdarstellungen, Körperteile oder anthropomorphe Transformationen auswählen, was eine differenzierte Analyse ikonographischer Varianten ermöglicht. |
Ein zentraler Bestandteil des digitalen Zeichenkatalogs ist die ikonographische Recherche, die über das Eingabefeld Iconography eine präzise und methodisch fundierte Abfrage ermöglicht. Dabei wird eine hierarchisch strukturierte Begriffsliste mit einer flexiblen Freitextsuche kombiniert, um innerhalb eines kontrollierten Vokabulars ikonographischer und formenkundlicher Merkmale zu navigieren. Während die direkte Eingabe eine alphabetisch geordnete Dropdown-Auswahl bietet, erlaubt der Expertenmodus eine semantisch präzisierte Abfrage, basierend auf Inhalt und Struktur der kontrollierten Vokabulare zur ikonographischen und formenkundlichen Annotation der Graphe (Abbildung 22). Mithilfe der logischen Operatoren „AND“ und „OR“ lassen sich Suchanfragen gezielt differenzieren: „AND“ identifiziert ausschließlich Graphe, die sämtliche gewählten Merkmale enthalten, während „OR“ eine erweiterte Exploration ermöglicht, indem es Graphe erfasst, die mindestens eines der gewählten Merkmale aufweisen. Diese taxonomisch-semiotische Strukturierung erlaubt die Generierung thematischer Graphlisten, die unabhängig von der sprachlichen Bedeutung der Zeichen funktionieren. Besonders bedeutsam ist diese Funktion für die systematische Analyse von Graphen, die sich nach ikonographischen oder formalen Kriterien – etwa Tiere, Artefakte oder Landschaftselemente – gruppieren lassen. Ebenso können semiotische Marker gezielt gefiltert werden, die Materialeigenschaften oder konzeptuelle Qualifikatoren kennzeichnen (vgl. Stone und Zender 2011). So dienten in der Maya-Schrift visuelle Signifikanten wie te’ zur Markierung von Holz, tuun für Stein oder baak für Knochen, wodurch nicht nur physische Materialitäten, sondern auch abstrakte Kategorisierungen visualisiert wurden. Diese ikonographischen Marker fungieren als visuelle Metadaten, die es ermöglichen, das Korpus bekannter Zeichen systematisch nach formalen, ikonographischen und inhaltlichen Parametern zu durchsuchen und anzuzeigen. Auf diese Weise wird die Systematik des Zeichenkatalogs von sprachlichen Lesungen entkoppelt und folgt keiner festen oder vordefinierten Sortierung nach Lautwerten oder Ikonographie. Stattdessen ermöglichen die Filter- und Suchfunktionen des Portals eine flexible und individuelle Anpassung der Sortierung und Abfrage an spezifische Forschungsfragen.
Suche und Filter von Graphen im Kontext
Zeichen mit ihren Graphen sind die kleinsten bedeutungsunterscheidenden Einheiten eines Schriftsystems und manifestieren sich auf materiellen Trägern, die nicht nur als Schriftträger fungieren, sondern in der Epigraphik als essentielle Elemente für die Interpretation des kulturellen und historischen Kontexts gelten. Materialien wie Stein, Keramik oder Rindenbast sowie Schreibtechnologien wie Malerei und Skulptierung beeinflussen nicht nur die Materialität der Schriftzeichen, sondern auch deren Bedeutung, Funktion und Wahrnehmung. Die archäologische Kontextualisierung und epigraphische Analyse dieser Schriftträger ermöglicht eine präzise zeitliche und räumliche Einordnung von Schrift – im Fall der Maya etwa durch taggenaue Kalenderangaben – und erlaubt Rückschlüsse auf Entstehungszeit, Nutzung und Verbreitung von Schrift. Zudem kann sie die Entwicklung der Graphe sowohl synchron als auch diachron nachzeichnen. Die Verknüpfung von Schriftträgern mit bestimmten Orten und Individuen vertieft das Verständnis historischer Zusammenhänge, indem sie Schrift nicht isoliert betrachtet, sondern in soziale, politische und kulturelle Kontexte einbettet. Eine systematische Dokumentation dieser Parameter beantwortet zentrale Fragen zur Materialität, Kalligraphie und Nutzung von Schriftzeichen, indem sie aufzeigt, auf welchen Trägern sie erscheinen, welche Materialien bevorzugt wurden, wer für ihre Produktion verantwortlich war und in welchen sozialen und geographischen Räumen sie verbreitet sind. Diese Informationen sind im Zeichenkatalog erfasst, filterbar und visualisierbar, sodass sich Muster in der Materialwahl, Schriftpraktiken bestimmter sozialer Gruppen und Verbindungen zwischen Schrifttraditionen nachzeichnen lassen.
|
|
| Abbildung 23. Ansicht der Filterkategorie Context & Usage im digitalen Zeichenkatalog zur gezielten Analyse von Verbreitung, Materialität und Kontext von Maya-Graphen. Die benutzerfreundliche Oberfläche erlaubt eine differenzierte Filterung nach Schriftträgermaterialien, Fundorten, Artefakten, Datierungen und sozialen Zuschreibungen – etwa durch die Auswahl spezifischer Orte, Inschriften, Epochen oder mit Personen assoziierter Schriftzeichen. Die Visualisierung unterstützt die Untersuchung historischer, kultureller und sozialer Dimensionen der Schriftnutzung im klassischen Maya-Raum. |
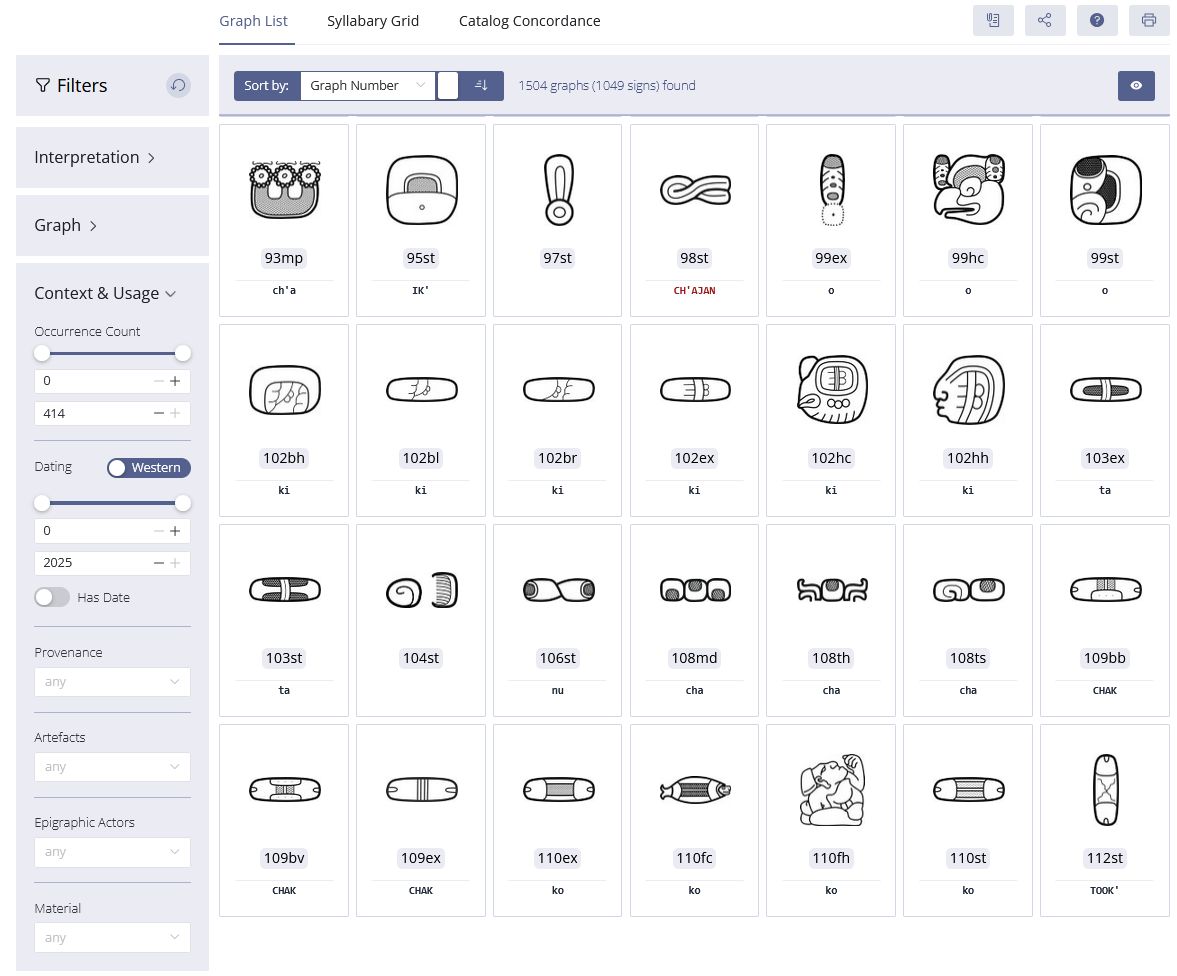
Der Zeichenkatalog bietet unter Context & Usage gezielte Analysemöglichkeiten zur Materialität und Verbreitung von Maya-Schriftzeichen (Abbildung 23). Die Funktion Occurrence Count ermöglicht die Filterung von Graphen basierend auf deren Häufigkeit in den TEI-Dokumenten des Projekts innerhalb der digitalen Forschungsumgebung TextGrid, die Inschriftendaten in maschinenlesbarer Form bereitstellt. Die Analysen liefern eine systematische Übersicht über die Verteilung der Graphen im Korpus und ermöglichen es, quantitative Muster sowie Korrelationen zwischen Schriftträgern, Epochen und Schrifttraditionen zu identifizieren. Die zeitliche Verbreitung von Graphen kann im Bereich Dating spezifiziert werden, basierend auf der Dokumentation der schrifttragenden Artefakte innerhalb von TextGrid. Nutzende können dabei entweder die originale Maya-Notation oder die westliche Datierung wählen. Der Zeitrahmen lässt sich manuell durch die Eingabe von Jahreszahlen oder über einen Schieberegler anpassen. Ist die Option Has Date aktiviert, werden ausschließlich Schriftträger mit absoluten Datierungen berücksichtigt. Erweiterte Filteroptionen ermöglichen eine gezielte Einschränkung der Auswahl der Graphe nach Artefakten, Orten, Personen und Materialien, um Schriftträger in spezifischen geographischen, sozialen oder materiellen Kontexten zu analysieren. Über den Filter Provenance können Nutzende individuelle Zeichen- und Graphlisten für ausgewählte Fundorte aus einem Dropdown-Menü abrufen oder für einzelne Inschriften über das Eingabefeld Artefact gezielt filtern. Dies erlaubt eine flexible Anpassung der Zeichenlisten an spezifische Fundorte oder Artefakte. Mithilfe des Zeitfilters kann zudem eine chronologische Eingrenzung erfolgen, während der Filter Persons eine soziale Dimension einblendet, indem er alle Zeichen anzeigt, die mit einer Persönlichkeit aus der herrschenden Elite in Verbindung stehen. Falls die Materialität der Schriftträger von Interesse ist, können Nutzende im Feld Material verschiedene Schriftträgermaterialien auswählen, woraufhin die Zeichenlisten im Hauptfeld automatisch entsprechend angepasst werden. Durch diese Dokumentation und Analyse der Schriftträger und ihrer Zeichen ermöglicht der digitale Zeichenkatalog nicht nur eine detaillierte Untersuchung der materiellen, sozialen und historischen Dimensionen der Maya-Schrift, sondern schafft auch eine fundierte Grundlage für weiterführende epigraphische und kulturhistorische Forschungen. Die Kombination aus digitalen Filtermöglichkeiten, präziser Datierung und kontextueller Verknüpfung eröffnet neue Perspektiven auf die Entwicklung von Schriftpraktiken und deren gesellschaftliche Verankerung und macht die komplexen Zusammenhänge zwischen Schrift, Schriftträger und Kontext systematisch erfassbar.
Stammblatt von Zeichen und Graphen
|
a |
b |
c |
| Abbildung 24. Beispiel eines digitalen Stammblatts im Zeichenkatalog für das Zeichen 77 mit Registern zu Interpretation (a), Graph-Varianten (b) und bibliographischer Dokumentation (c). Das Stammblatt vereint sprachwissenschaftliche, graphische und historische Informationen zu einem Zeichen und bietet detaillierte Angaben zu Lesung, Häufigkeit, Materialität sowie relevanter Literatur. Es dient als zentrales Analyseinstrument zur systematischen Erschließung der Maya-Schrift. | ||
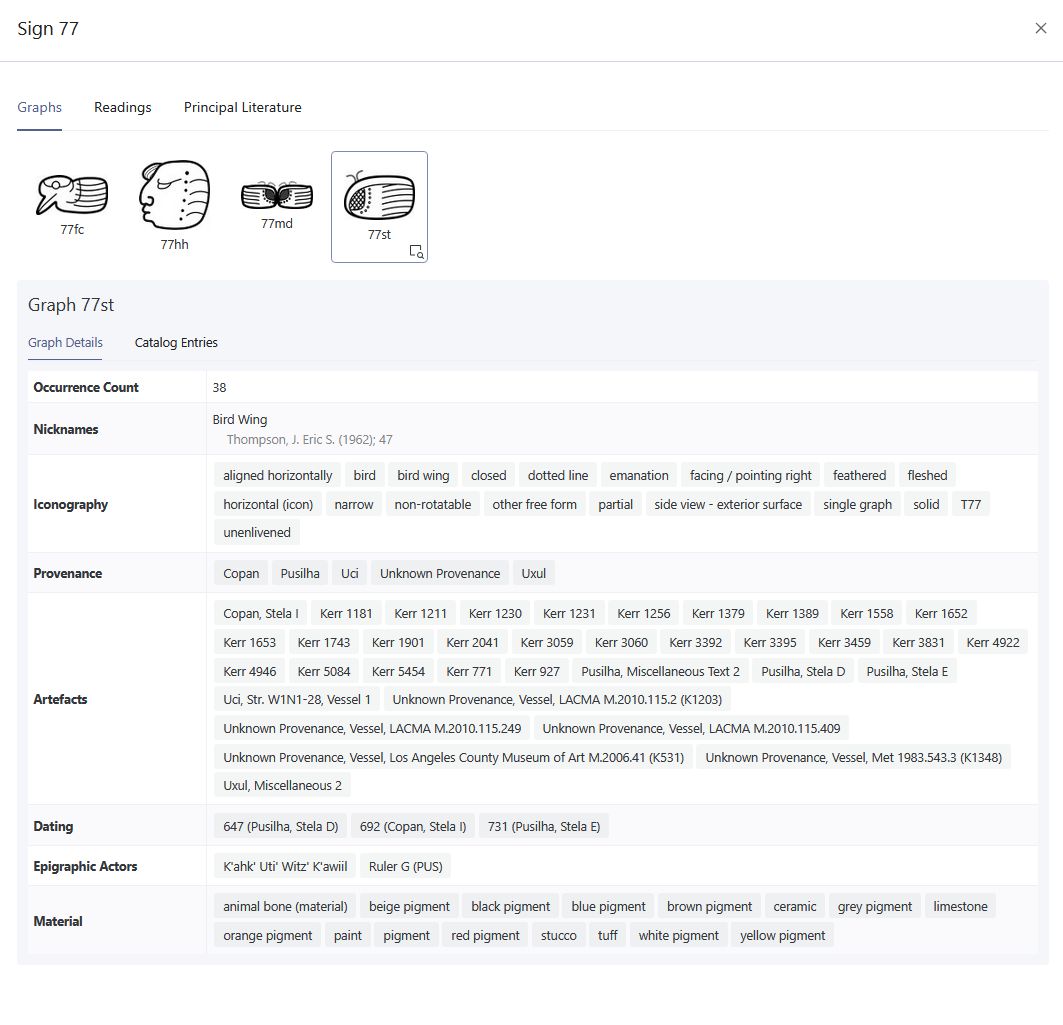
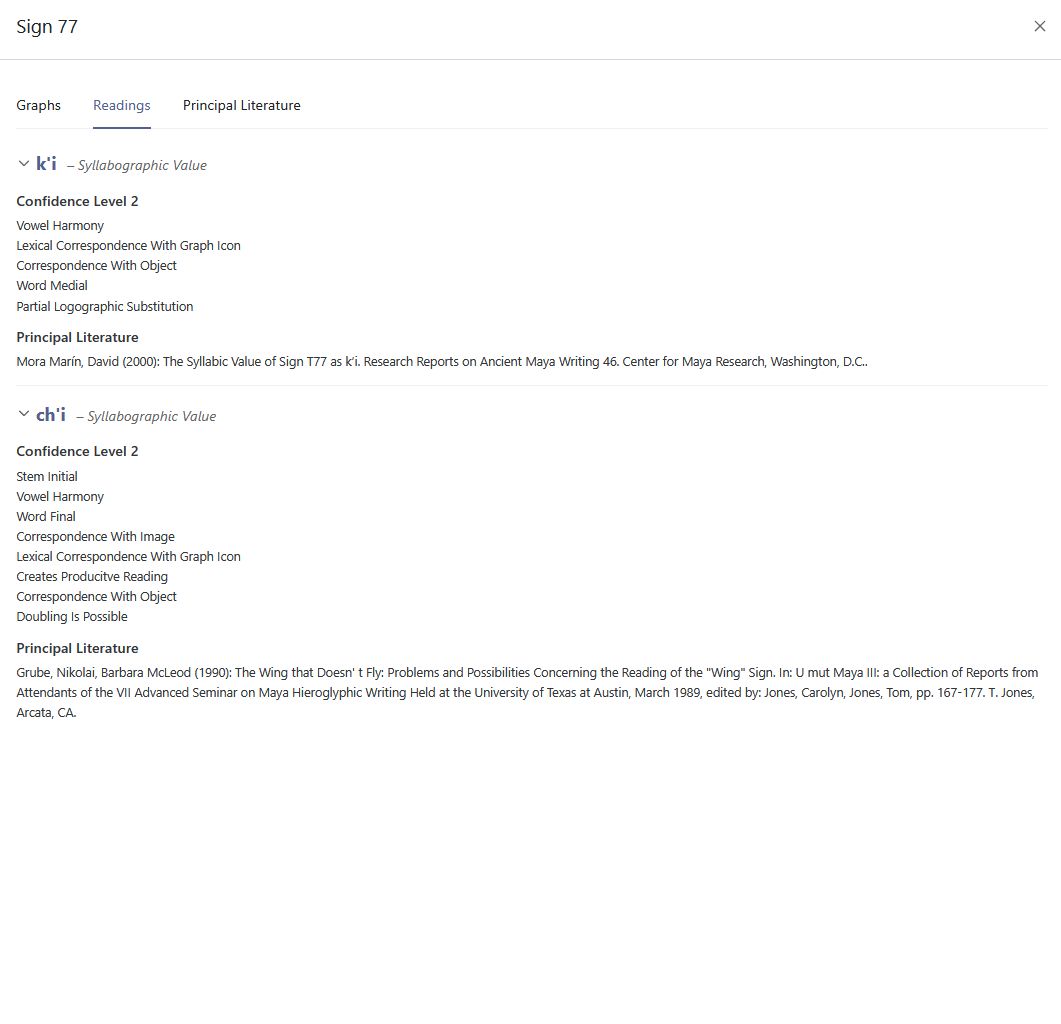
Das Stammblatt eines Schriftzeichens stellt das zentrale Instrument zur systematischen Erschließung der Maya-Schrift dar und bildet den Ausgangspunkt der Textdatenbank (Abbildung 24). Es vereint alle relevanten Informationen zu einem Zeichen sowie seinen graphischen Varianten und fungiert als Schnittstelle zwischen graphischer, epigraphischer und bibliographischer Analyse. Durch die Grid-Ansicht des Hauptbereichs ist es unmittelbar zugänglich und verbindet visuelle Repräsentationen mit sprachwissenschaftlichen Interpretationen, während es zugleich die historische Entwicklung der Forschung dokumentiert. Die entsprechenden Daten zu den Zeichen und Graphen werden in standardisierten Formaten wie RDF und TEI innerhalb der virtuellen Forschungsumgebung TextGrid erfasst und tagesaktuell über eine Schnittstelle importiert. Dies gewährleistet eine nachhaltige, interoperable und zitierfähige Grundlage für wissenschaftliche Untersuchungen. Die Struktur des Stammblatts folgt einer klaren hierarchischen Gliederung auf zwei Ebenen: Die übergeordnete Ebene Sign beschreibt das Zeichen als abstrakte Einheit, während die Ebene Graph dessen konkret belegte graphische Varianten dokumentiert. Die sprachwissenschaftliche Entzifferung – sei es als Silbenzeichen, Wortzeichen, Numeral oder diakritisches Zeichen – wird detailliert in der Registerkarte Interpretation behandelt. Ergänzend dazu bietet die Translation, sofern vorhanden, eine englische Übersetzung zur Erschließung der semantischen Bedeutung eines Logogramms. Ein zentrales Element im Tab Interpretation bildet das Confidence Level, das die Plausibilität einer Entzifferung auf einer achtstufigen Skala bewertet. Während Stufe 1 eine gesicherte Lesung kennzeichnet, verweist Stufe 8 auf eine hypothetische Deutung (siehe Diehr et al. 2019). Diese Klassifikation ermöglicht eine transparente Einschätzung der Verlässlichkeit einer bestimmten Lesung und bildet eine fundierte Basis für weiterführende Analysen, insbesondere im Hinblick auf Wörterbucheinträge. Ergänzend zur phonologischen und logographischen Interpretation enthält das Stammblatt ggf. detaillierte Anmerkungen zu Schreibvarianten und lautlichen Komplementierungen, die in den Kommentarfeldern dokumentiert sind. Die bibliographische Dokumentation spielt eine zentrale Rolle: Sie verzeichnet nicht nur relevante Primärquellen unter principal literature, sondern auch die historische Entwicklung der Entzifferung. Dabei wird zwischen jenen Forschern unterschieden, die eine heute anerkannte Lesung erstmals vorschlugen, und jenen, die sie weiterentwickelten oder durch spätere Arbeiten bestätigten. Bei der Recherche der Entzifferungshistorie für die Zeichen wurde häufig auch auf unpublizierte Dokumente, Briefe und graue Literatur zurückgegriffen, die einen Großteil der wissenschaftlichen Kommunikation der 1980er und 1990er Jahre ausmachen, während derer viele der heute als gesichert geltenden Entzifferungen gemacht wurden.
Von entscheidender Bedeutung ist, dass der Zeichenkatalog im Bereich der sprachlichen Lesungen oder interpretation mit Reading Value ausschließlich aktuelle Entzifferungen berücksichtigt. Frühere Deutungen, die sich als überholt oder fehlerhaft erwiesen haben – insbesondere Lesungen aus den Jahren 1950 bis etwa 1980, wurden bewusst ausgeschlossen. Stattdessen verweist die Bibliographie auf umfassende Dokumentationen dieser historischen Entzifferungen, insbesondere auf die Kataloge von Macri, Looper, Vail und Polyukhovich (2003 und 2009) sowie die Kompilationen von John Justeson und Kornelia Kurbjuhn, die eine wesentliche Grundlage der Bibliographie bilden. So bleibt der Katalog einerseits ein präzises und zeitgemäßes Referenzwerk, während die historische Entwicklung der Entzifferung über die genannte, weiterführende Literatur nachvollzogen werden kann. Ergänzend in die Bibliographie eingearbeitet wurde das Werk von Linda Quist (Quist 1997), die in den 1990er Jahren hilfreiche Indizes zu den damals vor allem in Texas publizierten Workshop-Bänden, den Texas Notes, Copan Notes sowie weiteren Grundlagenmaterialien erstellte und der Forschung zugänglich machte.
Der Bereich Graphs präsentiert die verschiedenen belegten Schreibvarianten eines Zeichens in Kachelform, die jeweils eine Illustration und eine eindeutige Kodierung enthalten. Sofern Inhalte verfügbar sind, können Nutzende für jedes Graph zwischen den Ansichten Graph Details und Catalog Entries wechseln. Ein Klick auf eine Variante öffnet eine Detailansicht mit weiterführenden Informationen zu belegten Vorkommen, Häufigkeitsverteilung, ikonographischen Merkmalen, alternativen Bezeichnungen sowie Fundorten. Darüber hinaus werden die Datierung des jeweiligen Graphs und sämtliche Artefakte erfasst, auf denen es bislang nachgewiesen ist. Die Verknüpfung mit historischen Persönlichkeiten, insbesondere Königinnen und Könige, die über das zugehörige Artefakt mit dem Zeichen in Zusammenhang stehen, ist im Bereich Persons dokumentiert. Gleichzeitig wird das Trägermaterial – sei es Stein, Keramik oder ein anderes Medium – spezifiziert.
Die anzeigbare Häufigkeitsangaben eines Graphs basieren auf einer quantitativen Analyse aller Vorkommen innerhalb der TEI-Dokumente. Die ikonographische Beschreibung wird durch interaktive Tags ergänzt, die eine gezielte Identifikation und den Vergleich von Graphen mit identischen Annotationen innerhalb des Katalogs ermöglichen.
Ein zentrales Element des Projekts ist die Konkordanz, die den aktuellen Zeichenkatalog mit Hieroglyphenkatalogen seit 1931 verknüpft (Abbildung 25). Sie ist sowohl über die Navigationsleiste unter Catalog Concordance als auch innerhalb der Stammblattansicht unter Catalog Entries zugänglich. Mit derzeit über 12.000 Einträgen gewährleistet dieses Verzeichnis eine transparente Korrelation zwischen früheren Zeichenkodierungen und der vorliegenden Klassifikation und erlaubt einen direkten Vergleich mit originalen Abbildungen historischer Kataloge. Diese systematische Gegenüberstellung erleichtert die paläographische Analyse von Varianten erheblich, da ältere Kataloge häufig originale Belege als Grundlage ihrer Darstellungen nutzten und somit eine präzisere Einordnung historischer Entwicklungsstufen ermöglichen. Indem die Konkordanz eine kohärente Referenzbasis schafft, erleichtert sie den methodischen Vergleich unterschiedlicher Klassifikationsansätze und fördert zugleich den wissenschaftlichen Austausch zwischen verschiedenen epigraphischen Traditionen. Darüber hinaus ermöglicht sie eine detaillierte Nachverfolgung der Entwicklung der Katalogisierung der Maya-Schrift und verbindet historische Aufarbeitung mit innovativen digitalen Forschungsmethoden. Auf diese Weise trägt sie nicht nur zur retrospektiven Analyse bestehender Klassifikationen bei, sondern bildet auch die Grundlage für neue methodische Ansätze in der epigraphischen Forschung.
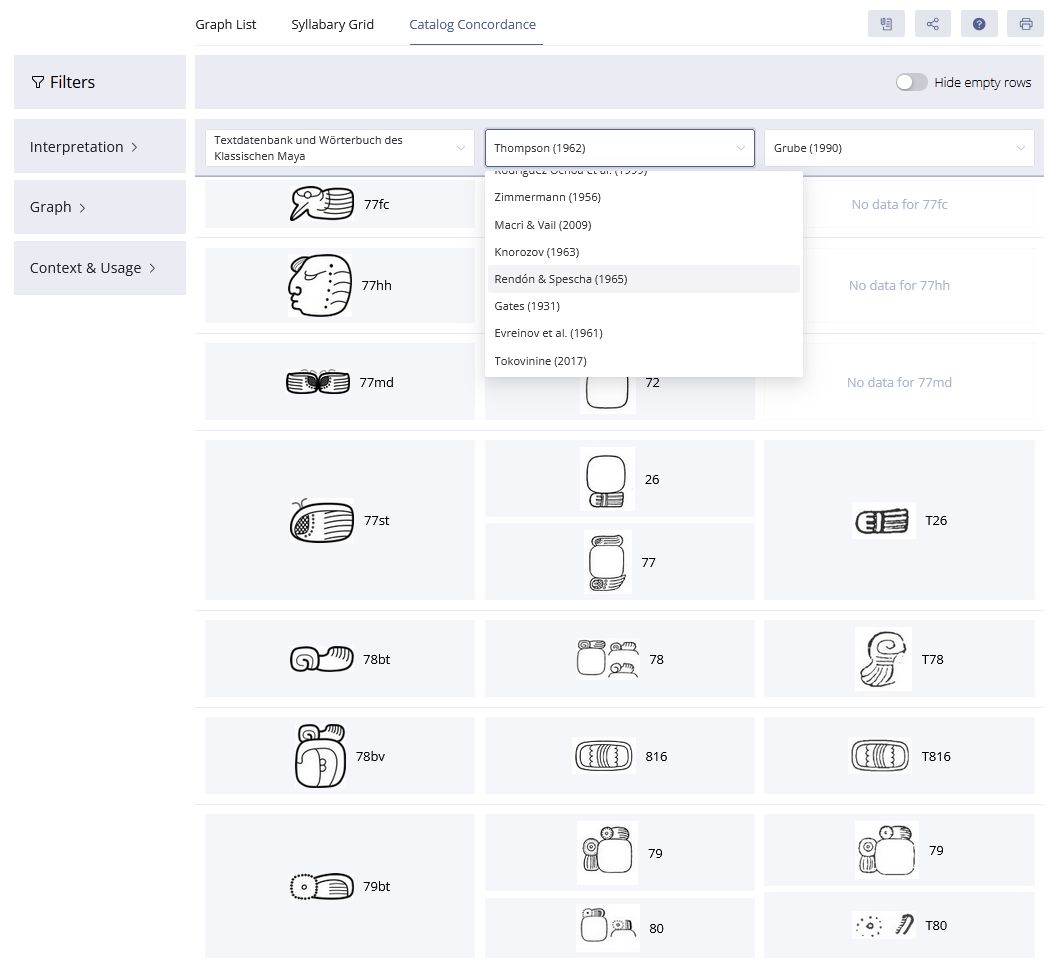 a |
 b b |
| Abbildung 25. Die Konkordanz verknüpft den digitalen Zeichenkatalog mit Hieroglyphenkatalogen seit 1931. Sie ist sowohl über die Navigationsleiste unter Catalog Concordance (b) als auch innerhalb der Stammblattansicht unter Catalog Entries (a) zugänglich. Abbildung (a) zeigt die Darstellung eines Zeichens mit zugehörigen historischen Katalogeinträgen (Catalog Entries), während (b) eine Übersicht der Varianten desselben Zeichens in verschiedenen Katalogen (Catalog Concordance) inklusive Filteroptionen zur Interpretation, zum graphischen Erscheinungsbild sowie zur Verwendung veranschaulicht. Die systematische Gegenüberstellung fördert die präzise Einordnung historischer Entwicklungsstufen und schafft eine kohärente Referenzbasis für vergleichende Klassifikationsansätze. In der Gesamtansicht können jeweils bis zu drei Kataloge gleichzeitig aktiviert und miteinander verglichen werden. | |
Zusammenfassung
Der digitale Zeichenkatalog stellt ein innovatives Instrument zur systematischen Erfassung, Analyse und Präsentation der Maya-Hieroglyphenschrift dar. Er basiert auf einer methodischen Weiterentwicklung früherer Kataloge und behebt deren Schwächen durch die Nutzung von Konkordanzen, eine präzise semiotische Unterscheidung zwischen Zeichen und Graphen sowie eine flexible, datengetriebene Struktur. Ein zentrales Merkmal ist die Trennung von Graphen, die konkrete visuelle Formen darstellen, und Zeichen, welche bedeutungstragende Schrifteinheiten repräsentieren. Diese Differenzierung ermöglicht eine präzisere Dokumentation der graphischen Vielfalt und ikonographischen Struktur der Schrift. Statt starrer Klassifikationen nutzt der Katalog eine dynamische Verschlagwortung mit kontrollierten Vokabularen. Dadurch können Zeichen unabhängig von traditionellen Kategorien flexibel analysiert und zugeordnet werden. Dies eröffnet neue Perspektiven auf Zusammenhänge und Familienähnlichkeiten, die über konventionelle Ansätze hinausgehen. Die digitale Plattform A Digital Catalog of Maya Hieroglyphs (DCMH) unterstützt gezielte Recherche, Filterung und Analyse von Schriftzeichen und ihren Varianten. Die Benutzeroberfläche bietet eine intuitive Navigation, wobei die Grid View standardmäßig numerisch sortierte Zeichenkacheln zeigt. Zeichen werden ikonographisch verschlagwortet, mit bekannten Lesungen versehen und auf einer Skala von 1 bis 8 hinsichtlich ihrer Plausibilität bewertet, um die Nachvollziehbarkeit zu sichern. Nutzende können gezielt nach ikonographischen Elementen, linguistischen Entzifferungen oder materiellen Schriftträgern suchen. Ein weiterer zentraler Aspekt ist die kontinuierliche Integration neuer Entzifferungen und die Revision bestehender Lesungen. Die fortlaufende Aktualisierung der Datenbank ermöglicht die Einbindung aktueller wissenschaftlicher Erkenntnisse in Echtzeit. Der Katalog dokumentiert somit nicht nur den aktuellen Forschungsstand, sondern trägt aktiv zur Weiterentwicklung der Maya-Schriftforschung bei. Die Plattform verbindet semiotische, ikonographische und linguistische Methoden zu einer transparenten, interdisziplinär nutzbaren Grundlage. Durch ihre Interoperabilität mit digitalen Analysetools und die Open-Access-Verfügbarkeit wird sie langfristig eine zentrale Referenz in der digitalen Epigraphik darstellen.
Konzipierung und Mitarbeitende
Das Team des Digital Catalog of Maya Hieroglyphs besteht aus Nikolai Grube, Direktor des Projekts und Mitglied des Katalogteams mit Schwerpunkt auf Epigraphik und Metadaten; Christian Prager, verantwortlich für Projektkoordination, konzeptionelle Gestaltung, Epigraphik, Textannotation, Metadaten und visuelle Dokumentation; Elisabeth Wagner, zuständig für kontrollierte Vokabulare, ikonographische Klassifikation und Epigraphik; Guido Krempel, der zu Epigraphik und Textannotation beiträgt; sowie Antje Grothe, verantwortlich für Metadaten und Bibliographie. Die technische Infrastruktur wird von Börge Kiss (Cologne Center of eHumanities, Kooperationspartner), Tobias Mercer und Moritz Schepp entwickelt, programmiert, implementiert und gewartet; Stefan Funk und Ubbo Veentjer von der Georg-August-Universität Göttingenn (Kooperationspartner) stellten den erfolgreichen Betrieb der Datenbank auf den Servern in Göttingen sicher.
In den früheren Projektphasen haben zahlreiche Kolleginnen und Kollegen wesentlich zur Gestaltung der Metadaten, zur Implementierung, Programmierung und kontinuierlichen Weiterentwicklung der Datenbank – einschließlich der Datenanreicherung – beigetragen. Hierzu zählen in alphabetischer Reihenfolge: Maximilian Behnert-Brodhun (2014–2022, IT-Infrastruktur), Marie Botzet (2019–2024, Epigraphik), Katja Diederichs (2014–2022, konzeptionelle Gestaltung und Metadaten), Franziska Diehr (2014–2018, konzeptionelle Gestaltung und Metadatenstruktur), Sven Gronemeyer (2014–2020, konzeptionelle Gestaltung, Epigraphik, Textannotation, Linguistik, Metadaten), Maxim Ionov (2022–2024, IT-Infrastruktur), Jana Karsch (2014–2017, Epigraphik), Lisa Mannhardt (2015–2020, Epigraphik), Niklas Jan Schürmann (2025, Epigraphik) und Uwe Sikora (2018, Metadatenstruktur).
Das Projekt dankt Peter Mathews für die großzügige Bereitstellung der Daten aus seinem umfassenden Maya Dates Project. Die darin enthaltenen Monumentdatierungen wurden in den Zeichenkatalog integriert und dienen unter anderem als wichtige Grundlage für die chronologische Einordnung der Monumente. Christian Prager spricht seinen Dank aus an Joanne Baron, Simon Martin, Mallory Matsumoto und Sébastian Matteo für ihre kritischen Anmerkungen und wertvollen Beiträge zur Verfeinerung und Erweiterung des Text- und Glyphenkorpus, sowie an Alexandre Tokovinine für die großzügige Bereitstellung seines Beginner’s Visual Catalog of Maya Hieroglyphs (2017) zur Nutzung und Verbreitung seiner Zeichnungen auf dieser Plattform.
Zitierte Literatur
Beyer, Hermann
1930 The Infix in Maya Hieroglyphs: Infixes Touching the Frame. Proceedings of the International Congress of Americanists 23:193–199.
1934a The Position of the Affixes in Maya Writing I. Maya Research 1(1):20–29; 101–108.
1934b The Position of the Affixes in Maya Writing II. Maya Research 1(2):101–108.
1936 The Position of the Affixes in Maya Writing III. Maya Research 3(1):102–104.
Borger, Rykle
2010 Mesopotamisches Zeichenlexikon. 2. revidierte und aktualisierte Aufl. Alter Orient und Altes Testament 305. Ugarit-Verlag, Münster.
Diehr, Franziska, Maximilian Brodhun, Sven Gronemeyer, Katja Diederichs, Christian M. Prager, Elisabeth Wagner, und Nikolai Grube
2018 Ein digitaler Zeichenkatalog als Organisationssystem für die noch nicht entzifferte Schrift der Klassischen Maya. In Knowledge Organization for Digital Humanities: Proceedings of the 15th Conference on Knowledge Organization WissOrg’17 of the German Chapter of the International Society for Knowledge Organization (ISKO) [30th November - 1st December 2017, Freie Universität Berlin], Christian Wartena, Michael Franke-Maier, und Ernesto de Luca (Hrsg.), pp. 37–43. Freie Universität Berlin, Berlin. http://edocs.fu-berlin.de/docs/servlets/MCRFileNodeServlet/FUDOCS_derivate_000000009518/ProcWissOrg2017.pdf.
Diehr, Franziska, Sven Gronemeyer, Christian M. Prager, Katja Diederichs, Nikolai Grube, und Uwe Sikora
2019 Modelling Vagueness – A Criteria-Based System for the Qualitative Assessment of Reading Proposals for the Deciphering of Classic Mayan Hieroglyphs. In Proceedings of the Workshop on Computational Methods in the Humanities 2018, pp. 33–44. CEUR Workshop Proceedings 2314. Université de Lausanne, Lausanne. https://dblp.org/db/conf/comhum/comhum2018.html.
England, Nora C., und Stephen R. Elliott (Hrsg.)
1990 Lecturas sobre la lingüística maya. Centro de Investigaciones Regionales de Mesoamerica, La Antigua Guatemala.
Evreinov, Eduard V., Jurij G. Kosarev, und Valentin A. Ustinov
1961 Primenenie ėlektronnych vyčislitel’nych mašin v issledovanii pis’mennosti drevnych Majja, 1-3. Izdatel’stvo Sirbirskogo Otdelenija AN SSSR, Novosibirsk.
Gardiner, Alan H.
1957 Egyptian Grammar: Being an Introduction to the Study of Hieroglyphs. 3rd edition. Griffith Institute, Oxford.
Gates, William E.
1931 An Outline Dictionary of Maya Glyphs: With a Concordance and Analysis of Their Relationships. Maya Society Publication 1. John Hopkins Press, Baltimore, MD.
Grube, Nikolai
1990 Die Entwicklung der Mayaschrift: Grundlagen zur Erforschung des Wandels der Mayaschrift von der Protoklassik bis zur spanischen Eroberung. Acta Mesoamericana 3. Von Flemming, Berlin.
Houston, Stephen D.
2001 Introduction. In The Decipherment of Ancient Maya Writing, Stephen D. Houston, Oswaldo Chinchilla-Mazariegos, und David Stuart (Hrsg.), pp. 3–19. University of Oklahoma Press, Norman, OK.
Houston, Stephen D., David S. Stuart, und John S. Robertson
1998 Disharmony in Maya Hieroglyphic Writing: Linguistic Change and Continuity in Classic Society. In Anatomía de Una Civilización: Aproximaciones Interdisciplinarias a La Cultura Maya, Andrés Ciudad Ruiz, Yolanda Fernández, José Miguel García Campillo, Josefa Iglesia Ponce de Leon, Alfonso Lacadena García-Gallo, und Luis Sanz Castro (Hrsg.), pp. 275–296. Publicaciones de la Sociedad Española de Estudios Mayas 4. Sociedad Española de Estudios Mayas, Madrid.
Howson, Colin, und Peter Urbach
2006 Scientific Reasoning: The Bayesian Approach. 3rd edition. Open Court, Chicago, IL.
Knorozov, Jurij V.
1963 Pis’mennost indejcev Majja. Izdatel’stvo Akademii Nauk SSSR, Moskva.
Lacadena García-Gallo, Alfonso, und Søren Wichmann
2004 On the Representation of the Glottal Stop in Maya Writing. In The Linguistics of Maya Writing, Søren Wichmann (Hrsg.), pp. 100–164. University of Utah Press, Salt Lake City, UT.
Landa, Diego de
1566 Relación de las cosas de Yucatán / Fray Di[eg]o de Landa: / MDLXVI. Manuscript. Madrid. Biblioteca de la Real Academia de Historia. https://bibliotecadigital.rah.es/es/consulta/registro.do?control=RAH20180001215.
Looper, Matthew, Martha J. Macri, Yuriy Polyukhovich, und Gabrielle Vail
2022 MHD Reference Materials 1: Preliminary Revised Glyph Catalog. Electronic Document. Glyph Dwellers. http://glyphdwellers.com/pdf/R71.pdf.
Macri, Martha J., und Matthew G. Looper
2003 The New Catalog of Maya Hieroglyphs: The Classic Period Inscriptions. Civilization of the American Indian Series 247. University of Oklahoma Press, Norman, OK.
Macri, Martha J., und Gabrielle Vail
2009 The New Catalog of Maya Hieroglyphs: The Codical Texts. Civilization of the American Indian Series 264. University of Oklahoma Press, Norman, OK.
Martin, Simon, und Nikolai Grube
2008 Chronicle of the Maya Kings and Queens: Deciphering the Dynasties of the Ancient Maya. 2nd edition. Thames & Hudson, London.
Peirce, Charles Sanders
1931 Collected Papers of Charles Sanders Peirce. Volume 1- 8. Charles Hartshtorne und Paul Weiss (Hrsg.). Harvard University Press, Cambridge, MA.
Prager, Christian M., Katja Diederichs, Antje Grothe, Nikolai Grube, Guido Krempel, Mallory Matsumoto, Tobias Mercer, Cristina Vertan, und Elisabeth Wagner
2024 IDIOM: A Digital Research Environment for the Documentation and Study of Maya Hieroglyphic Texts and Language. In Writing from Invention to Decipherment, Silvia Ferrara, Barbara Montecchi, and Miguel Valerio (Hrsg.), pp. 227–251. Oxford University Press, Oxford, New York.
Prager, Christian M., und Sven Gronemeyer
2018 Neue Ergebnisse in der Erforschung der Graphemik und Graphetik des Klassischen Maya. In Ägyptologische “Binsen”-Weisheiten III: Formen und Funktionen von Zeichenliste und Paläographie, Svenja A. Gülden, Kyra V. J. van der Moezel, und Ursula Verhoeven-van Elsbergen (Hrsg.), pp. 135–181. Akademie der Wissenschaften und der Literatur, Abhandlungen der Geistes- und sozialwissenschaftlichen Klasse 15. Franz Steiner Verlag, Stuttgart.
Rendón, Juan J., und Amalia Spescha
1965 Nueva clasificación “plástica” de los glifos mayas. Estudios de Cultura Maya 5:189–252. http://www.journals.unam.mx/index.php/ecm/article/view/32884.
Ringle, William M., und Thomas C. Smith-Stark
1996 A Concordance to the Inscriptions of Palenque, Chiapas, Mexico. Middle American Research Institute, Publication 62. Middle American Research Institute, Tulane University, New Orleans, LA.
de Saussure, Ferdinand
1931 Cours de Linguisticque Générale. Payot, Paris.
Schlenther, Ursula
1964 Kritische Bemerkungen zur kybernetischen Entzifferung der Maya-Hieroglyphen (mit 10 Abbildungen und 3 Tabellen). Ethnographisch-Archäologische Zeitschrift 5(5):111–139.
Stone, Andrea, und Marc Zender
2011 Reading Maya Art: A Hieroglyphic Guide to Ancient Maya Painting and Sculpture. Thames & Hudson, New York, NY.
Stuart, George E.
1988 A Guide to the Style and Content of the Series "Research Reports on Ancient Maya Writing". Research Reports on Ancient Maya Writing 15. Center for Maya Research, Washington, D.C.
Thompson, J. Eric S.
1962 A Catalog of Maya Hieroglyphs. The Civilization of the American Indian Series 62. University of Oklahoma Press, Norman, OK.
Tokovinine, Alexandre
2017 Beginner’s Visual Catalog of Maya Hieroglyphs. Mesoweb, San Francisco, CA. http://www.mesoweb.com/resources/catalog/Tokovinine_Catalog.pdf.
Wichmann, Søren
2004 The Linguistics of Maya Writing. University of Utah Press, Salt Lake City, UT.
Wittgenstein, Ludwig
1953 Philosophical Investigations. Blackwell, Oxford.
Xǔ, Shèn
1981 Shuowen Jiezi Zhu [說文解字注]. Zhonghua Shuju, Beijing.
Zender, Marc
2006 Review of M. Macri and M. Looper, “The New Catalog of Maya Hieroglyphs: Volume 1: The Classic Period Inscriptions” (University of Oklahoma Press, 2003). Ethnohistory 5(2):439–441.
2017 Theory and Method in Maya Decipherment. The PARI Journal 18(2):1–48. http://www.mesoweb.com/pari/journal/archive/PARI1802.pdf.
Zimmermann, Günter
1956 Die Hieroglyphen der Maya-Handschriften. Abhandlungen aus dem Gebiet der Auslandskunde, Reihe B, Völkerkunde, Kunstgeschichte und Sprachen 62. Cram, de Gruyter, Hamburg.
Zitiervorschlag
Database:
Textdatenbank und Wörterbuch des Klassischen Maya (TWKM)
2014–present. A Digital Catalog of Maya Hieroglyphs [Online database]. Project directed by Nikolai Grube. Principal development, editing and coordination by Christian Prager. Edited by Elisabeth Wagner, Guido Krempel, Antje Grothe, Börge Kiss, Tobias Mercer, and Moritz Schepp. With earlier contributions by Maximilian Behnert-Brodhun, Marie Botzet, Katja Diederichs, Franziska Diehr, Sven Gronemeyer, Maxim Ionov, Jana Karsch, and Lisa Mannhardt. Funded by the North Rhine-Westphalian Academy of Sciences, Humanities and the Arts, Düsseldorf. Online: https://classicmayan.org/signcatalog. Bonn: Rheinische Friedrich-Wilhelms-Universität Bonn, Department of the Anthropology of the Americas. [Accessed: DATE].
Sign Catalog Drawings:
Drawings by Christian Prager (2014–present), licensed under CC BY 4.0. Text Database and Dictionary of Classic Mayan, University of Bonn. Available at: https://classicmayan.org
Rechtliche Hinweise zur Nutzung des Zeichenkatalogs
Der digitale Zeichenkatalog der Maya-Schrift ist ein Open-Access-Projekt. Er steht der wissenschaftlichen Gemeinschaft sowie der interessierten Öffentlichkeit zur freien Nutzung zur Verfügung. Bitte beachten Sie jedoch die unterschiedlichen urheberrechtlichen, lizenzrechtlichen und sonstigen rechtlichen Bestimmungen, die für die enthaltenen Zeichnungen, Fotos und Abbildungen gelten.
Urheberrecht und Lizenzen
Zeichnungen von Christian Prager (CC BY 4.0): Alle von Christian Prager erstellten Zeichnungen im Zeichenkatalog sind unter der Creative Commons Namensnennung 4.0 International Lizenz (CC BY 4.0) veröffentlicht. Diese Lizenz erlaubt es, die betreffenden Zeichnungen frei zu nutzen, zu vervielfältigen, zu bearbeiten und zu verbreiten, sofern der Urheber Christian Prager korrekt genannt wird und ein Hinweis auf die CC-BY-4.0-Lizenz erfolgt.
Abbildungen aus externen Werken: Einige Abbildungen stammen aus externen Publikationen (u. a. Werken von J. Eric S. Thompson, Martha Macri, Gabrielle Vail, Günter Zimmermann). Diese Abbildungen sind urheberrechtlich geschützt und nicht frei lizenziert. Ihre Verwendung innerhalb dieses Zeichenkatalogs erfolgt ausschließlich im Rahmen wissenschaftlicher Auseinandersetzung gemäß § 51 UrhG (wissenschaftliches Zitatrecht) und mit ausdrücklicher Zustimmung der jeweiligen Rechteinhaber. Jede Weitergabe, Vervielfältigung oder anderweitige Nutzung dieser Abbildungen außerhalb des Kontexts dieses Projekts ist nicht gestattet, es sei denn, die vorherige ausdrückliche Genehmigung der jeweiligen Rechteinhaber wird eingeholt.
Weitere Inhalte und Nutzerpflichten: Der Zeichenkatalog kann weitere Bilder oder Inhalte Dritter enthalten, die ebenfalls rechtlich geschützt sind (sofern nicht anders gekennzeichnet). Nutzende sind daher verpflichtet, vor jeder Weiterverwendung von Inhalten aus dem Katalog selbst die jeweiligen Lizenz- und Nutzungsbedingungen zu prüfen. Gegebenenfalls erforderliche Genehmigungen Dritter sind von den Nutzenden eigenständig einzuholen.
Haftungsausschluss
Inhalte des Zeichenkatalogs: Die Betreiber des Zeichenkatalogs (Projektverantwortliche der Universität Bonn) bemühen sich um die Aktualität, Richtigkeit, Vollständigkeit und Qualität der bereitgestellten Informationen. Dennoch können Fehler oder Unklarheiten nicht ausgeschlossen werden. Es wird keine Gewähr für die inhaltliche Richtigkeit oder Vollständigkeit der Informationen übernommen. Haftungsansprüche gegen die Betreiber, welche sich auf Schäden materieller oder immaterieller Art beziehen, die durch die Nutzung oder Nichtnutzung der bereitgestellten Inhalte entstehen, sind ausgeschlossen, sofern seitens der Betreiber kein vorsätzliches oder grob fahrlässiges Verschulden vorliegt.
Externe Links: Dieser Katalog enthält Verweise (Links) zu externen Webseiten. Zum Zeitpunkt der Linksetzung waren die entsprechenden externen Seiten frei von illegalen Inhalten. Die Betreiber haben keinen Einfluss auf die aktuelle und zukünftige Gestaltung der verlinkten Seiten. Sie identifizieren sich nicht mit den fremden Inhalten und machen sich diese nicht zu Eigen. Eine ständige inhaltliche Kontrolle der verlinkten externen Seiten ist ohne konkrete Anhaltspunkte einer Rechtsverletzung nicht zumutbar. Daher übernehmen die Betreiber keine Haftung für die Inhalte externer Links. Für illegale, fehlerhafte oder unvollständige Inhalte auf verlinkten Seiten haftet ausschließlich der jeweilige Anbieter bzw. Betreiber dieser externen Seite. Wenn jedoch bekannt wird, dass eine verlinkte Seite rechtswidrige Inhalte enthält, wird der Link auf dieser Plattform umgehend entfernt.
Wissenschaftlicher Zweck und Rechte Dritter
Alle Inhalte des Zeichenkatalogs dienen – sofern nicht anders lizenziert – vorrangig wissenschaftlichen Zwecken (Forschung, Lehre, wissenschaftliche Dokumentation). Urheberrechtlich geschützte Abbildungen Dritter werden nur im notwendigen Umfang als wissenschaftliche Zitate im Sinne von § 51 UrhG verwendet und stets mit Quellenangaben versehen. Die Betreiber achten darauf, Rechte Dritter (Urheberrechte, Persönlichkeitsrechte usw.) nicht zu verletzen. Insbesondere werden keine Abbildungen von identifizierbaren Personen ohne entsprechende Berechtigung veröffentlicht.
Hinweis bei Rechtsverletzungen: Sollten Nutzende auf eine mögliche Rechtsverletzung aufmerksam werden (etwa einen Urheberrechtsverstoß oder die Verletzung von Persönlichkeitsrechten durch einen Inhalt des Katalogs), bitten wir um eine entsprechende Benachrichtigung. Die Betreiber werden den gemeldeten Sachverhalt unverzüglich prüfen und – falls erforderlich – die betreffenden Inhalte sofort entfernen oder korrigieren.
Eigenverantwortliche Nutzung: Die Nutzung der im Zeichenkatalog bereitgestellten Inhalte erfolgt auf eigene Verantwortung der Nutzenden. Die Betreiber übernehmen – neben den oben beschriebenen Einschränkungen – keine Haftung für die Art und Weise, wie Nutzende die bereitgestellten Informationen verwenden. Bei Unsicherheiten bezüglich der Rechtslage oder zulässigen Nutzung wird empfohlen, vor einer Weiterverwendung rechtlichen Rat einzuholen.
Kontakt und Impressum
Bei Fragen zur Nutzung der Inhalte oder zur Klärung urheberrechtlicher Angelegenheiten können Sie sich an die verantwortlichen Projektleiter wenden.
Inhaltlich Verantwortlich:
Prof. Dr. Nikolai Grube - Projektleitung
Institut für Archäologie und Kulturanthropologie,
Abteilung für Altamerikanistik, Universität Bonn
Anschrift:
Oxfordstraße 15, 53111 Bonn, Deutschland
Hosting: Die technische Bereitstellung der Plattform erfolgt mit freundlicher Unterstützung der Niedersächsischen Staats- und Universitätsbibliothek Göttingen (SUB Göttingen) bzw. der GWDG (Gesellschaft für Wissenschaftliche Datenverarbeitung Göttingen).
Mit der Nutzung des Zeichenkatalogs erklären Sie sich mit den oben genannten Nutzungsbedingungen einverstanden.
- Kopien aus dem Nachlass Thomas Barthels, der seinerseits Materialien aus dem Nachlass Eric Thompsons übernommen hatte, wurden dankenswerterweise von Prof. Dr. Roland Hardenberg (Goethe-Universität Frankfurt; zuvor Abteilung für Ethnologie, Universität Tübingen) zur Verfügung gestellt. Die hier gezeigte Reproduktion erfolgt mit freundlicher Genehmigung von Prof. Dr. Gabriele Alex (Abteilung für Ethnologie, Universität Tübingen).
- Punkt-Strich-Schreibung
- Portraitzeichen
- In der Zeichenübersicht nicht abgebildet.
- In der Einleitung erwähnt, im Katalog nicht abgebildet.
- Unklar ob ikonische oder semantische Bild-Laut-Beziehung.
- Unbekannter Lautwert, Zeichenikon geklärt.
- Weder Lautwert von Graphikon sind entziffert.