und Wörterbuch
des Klassischen Maya


A Digital Catalog of Maya Hieroglyphs
Working Paper 5
August 1, 2025
DOI: http://dx.doi.org/10.20376/IDIOM-23665556.25.WP005.de
Christian Prager, Elisabeth Wagner, Guido Krempel, Tobias Mercer, and Nikolai Grube
(Rheinische Friedrich-Wilhelms-Universität, Bonn)
Living Data Infrastructure
The database underlying this document constitutes part of a continuously evolving research infrastructure. It reflects the current state of an active analytical process and is updated on a daily basis, with new entries being added and existing records revised in light of ongoing scholarly work. The corpus is thus subject to continual expansion and refinement. The information presented here represents provisional, yet methodologically controlled, snapshots of the current state of knowledge. In the coming months, the database will be extended to include advanced functionalities—most notably refined filtering, search, and query capabilities—intended to support deeper analytical engagement and to enhance both the scholarly usability and accessibility of the data.
Introduction
The systematic classification and cataloguing of Maya hieroglyphic writing represents one of the most complex and methodologically demanding tasks in the field of Maya epigraphy. The remarkable diversity of signs, their extensive graphic variation, and the only partially deciphered semantic content continue to pose significant challenges to coherent analysis and consistent documentation. Earlier efforts - most notably J. Eric S. Thompson’s seminal catalog of Maya hieroglyphs (1962) - remain foundational reference works but are marked by considerable methodological shortcomings and systemic inconsistencies. The project "Text Database and Dictionary of Classic Mayan" (Textdatenbank und Wörterbuch des Klassischen Maya, TWKM) addresses these challenges through an integrative research approach that combines recent developments in the digital humanities with corpus-linguistic methodologies. Its objective is to establish a more precise, dynamically extensible, and methodologically consistent system for the classification of Maya hieroglyphs. Building on Thompson’s original inventory, the project undertakes a comprehensive revision: misclassifications are corrected, the sign repertoire is substantially expanded, and recent epigraphic discoveries are systematically incorporated. This article introduces the newly developed online portal for the study of Maya script, with a particular focus on the project’s methodological foundations and the principal challenges inherent to sign classification - such as graphic heterogeneity, structural inconsistencies in earlier catalogs, and the technological limitations of pre-digital approaches. At the same time, it demonstrates how digital methods can overcome these structural barriers and contribute meaningfully to the advancement of Maya epigraphy.
Since 2014, the TWKM project has been dedicated to the digital documentation of all currently known inscriptions in the Classic Mayan language (Prager et al. 2024). The project’s core objective is to facilitate the systematic analysis and lexicographic documentation of this highly complex script in its original orthographic form. Based at the North Rhine-Westphalian Academy of Sciences and Arts in Bonn and directed by Nikolai Grube, the project seeks to develop a comprehensive, digitally and print-accessible dictionary of Classic Mayan. This language, transmitted through a hieroglyphic writing system, remains only partially deciphered and is considered one of the most intricate and challenging writing systems ever developed. A central aim of the project is the digital recording of the Mayan lexicon in its authentic orthographic representation, followed by in-depth linguistic analysis based on contextually annotated lemmata. Text processing takes place in virtual research environments such as TextGrid, where the hieroglyphic inscriptions are encoded and annotated according to international XML-TEI standards. Although the sign catalog is initially based on Thompson’s numerical system, it has undergone extensive revision: erroneous classifications and duplicate entries have been removed, and several hundred previously undocumented signs have been added. Linguistic analysis, transliteration, and transcription are carried out using the project-specific tool ALMAH, which was developed to facilitate the morphological processing of the inscriptions. The resulting transcriptions constitute the foundation for both the digital and printed versions of the dictionary. By integrating contemporary digital technologies with epigraphic and linguistic expertise, the TWKM project establishes a new research infrastructure for the study of Maya hieroglyphic writing. All results will be made available in the long term via open-access platforms, ensuring accessibility for both the academic community and a broader public audience.
A Digital Catalog of Maya Hieroglyphs
Theoretical Framework
For the development of a digital text corpus and dictionary of a language preserved in a writing system that remains only partially deciphered, a sign catalog - a systematic inventory of all graphs and their variants - is essential. It forms the foundation for documenting and systematically analyzing the complex relationship between visual markings (graphemes) and linguistic units (signs), such as phonemes or morphemes. As part of the project, a digital sign catalog was designed within the research environment IDIOM, integrated into the TextGrid infrastructure (Prager et al. 2024). This highly specialized platform, tailored specifically to the systematic documentation and analysis of the complex hieroglyphic script of the Maya, enables a precise and comprehensive investigation of the script’s structural diversity. The project portal at https://classicmayan.org now makes this innovative resource available to the wider research community.
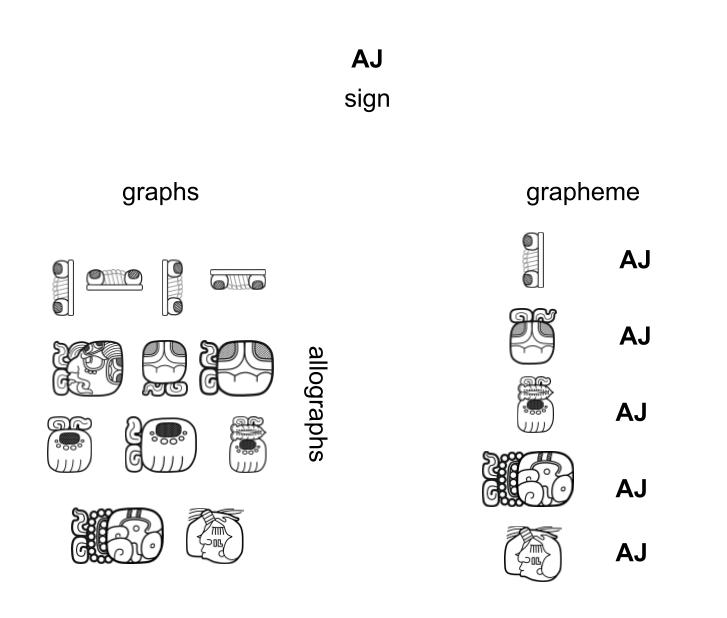 |
| Figure 1. The relation between sign (semantic), graph / allograph (visual) und grapheme (visual and semantic). Illustration: Christian Prager, 2025. |
A key methodological approach lies in the clear distinction between sign and graph (Figure 1). While signs represent abstract, semantic units that embody the linguistic or conceptual level of a writing system, graphs are the concrete visual realizations of these signs (Diehr et al. 2018). A written sign thus emerges from the combination of a linguistic-functional layer and a graphic layer, which encompasses all visual forms through which linguistic meaning is manifested. Different graphs that fulfill the same linguistic function are considered allographs of one another and collectively constitute the variants of a grapheme: the underlying abstract unit of the written sign. This methodological distinction makes it possible to analyze both the graphic diversity and the semantic function of a script independently, following a structuralist conception of the sign (de Saussure 1931) as well as a semiotic differentiation between signifier and signified (Peirce 1931: 2.228–2.231. This approach also allows for the inclusion of graphs in the catalog whose linguistic value or allographic relation to other signs has not yet been determined. In doing so, it contributes not only to a more comprehensive understanding of writing as both a cultural and linguistic system, but also to the systematic documentation of all graphic realizations - regardless of their current degree of linguistic decipherment.
Digital Framework
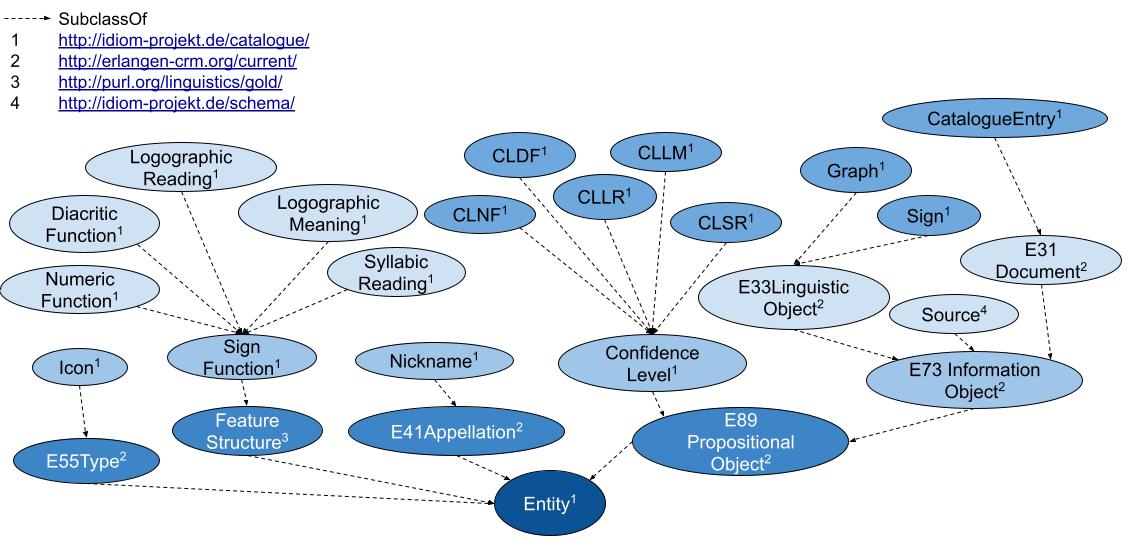
The digital catalog is based on a flexible, modular design that accounts for the distinction between graphs and signs. Its technological foundation lies in an ontology-based data model, grounded in international standards such as the CIDOC Conceptual Reference Model (CRM) (Diehr et al. 2018) (Figures 2–3). This modeling framework ensures that the semantic relationships among catalog elements are explicitly captured and represented within a flexible system architecture, thereby enabling interoperability with other research databases. Metadata schemas are employed to structure these semantic relations in a clear and coherent manner, allowing not only for dynamic extensibility but also for nuanced knowledge representation. Of particular significance is the automated, qualitative evaluation of competing decipherment hypotheses (Diehr et al. 2019). To support this, the catalog incorporates a multi-tiered assessment system that systematically evaluates proposed readings based on formal criteria derived from the scholarly literature (cf. Houston 2001:9; Zender 2017). In this framework, hypotheses are not only documented with precision but also assessed for their plausibility: Level 1 indicates high confidence in a proposed reading, while Level 8 denotes hypotheses that are poorly supported and classified as speculative. This process ensures a high degree of transparency and scholarly rigor in the treatment of a script that remains only partially deciphered. In addition, the catalog integrates the results of eleven prior classification systems for Maya hieroglyphs in the form of a concordance, including the seminal publications by Eric Thompson (1962) and Günter Zimmermann (1956). This approach makes it possible to trace the historiography of sign classification and to correct misclassifications and redundant listings of allographs. Another distinguishing feature of the catalog is the systematic treatment of graph variants - a dimension largely neglected in previous classification efforts. Drawing on the framework proposed by Prager and Gronemeyer (2018), the catalog identifies a total of 45 distinct types of variation. This enables a consistent documentation of the script’s visual diversity and enhances our understanding of the aesthetic and functional differentiation within the writing system.
 |
 |
| Figure 2. Class hierarchy of the digital catalog of Maya hieroglyphs. Conception and illustration: Franziska Diehr (cited from Diehr et al. 2018:39). | Figure 3. Domain model of the digital catalog of Maya hieroglyphs. Conception and illustration: Franziska Diehr (cited from Diehr et al. 2018:40). |
One of the major strengths of the digital sign catalog developed by the TWKM project is its dynamic expandability. Unlike static, printed catalogs, the digital environment allows for continuous updates, enabling the integration of newly discovered inscriptions and decipherment proposals as they emerge. Erroneous classifications can be revised, and new connections between graphs and signs can be added at any time. Each entity within the catalog is assigned a persistent identifier, ensuring scholarly traceability, transparency, and long-term consistency. A particularly notable feature of this digital infrastructure is its integration with the project’s text corpus and linguistic analysis tools. Every graph occurring in the digitized texts is assigned a catalog number based on Thompson’s system (1962) and linked to a unique URI. This design enables dynamic processing of texts and supports parallel analyses based on varying interpretive hypotheses, thereby allowing for flexible engagement with alternative readings and decipherment strategies. The digital sign catalog thus serves not only as a research tool for the study of Maya hieroglyphic writing but also as a methodological blueprint for epigraphic work in the digital humanities. Through its open-access design, it is made available to both the scholarly community and the general public, positioning it as a central instrument in the contemporary study of ancient writing systems.
Epigraphic Framework
Thompson’s catalog, the first systematic and comprehensive compilation of Maya hieroglyphs, laid the groundwork for modern Maya epigraphic practice. To this day, it remains a central reference tool, encompassing glyphs from both the codices and monumental inscriptions, and organizing them within a structured inventory. Inscriptions on ceramics, by contrast, received only marginal attention, reflecting the prevailing view at the time that such texts were primarily decorative in nature. Despite this limitation, Thompson’s work holds a distinguished place in the study of ancient scripts, comparable to other foundational catalogs such as Alan Gardiner’s sign list of Middle Egyptian hieroglyphs (1957), Rykle Borger’s index of Assyro-Babylonian cuneiform signs (2010), or Xǔ Shèn’s classical Chinese character dictionary Shuowen Jiezi from the first century AD (Xǔ Shèn 1981).
Thompson’s system drew partly on William Gates’s early efforts to classify the glyphs in the codices (1931), but more substantially on Günter Zimmermann’s 1956 catalog of the three Maya codices then known. Like Zimmermann, Thompson employed a numerical classification system, beginning with sign number 1 and organizing 862 graphemes across a range of 1 to 1347. Paleographic variants were distinguished using sequential lowercase letters (e.g., 1030a, 1030b), although Thompson did not explicitly address their functional significance. While inevitably shaped by the scholarly landscape of the late 1950s - and rendered incomplete by subsequent discoveries - his catalog still enables the identification of approximately 70 percent of graphemes found in Maya texts. Anticipating the need for expansion, Thompson proposed assigning newly identified glyphs to unused numbers within the existing framework. Later revisions - most notably those by Nikolai Grube (1990) and by William Ringle and Thomas C. Smith-Stark (1996) - significantly refined the catalog’s structure. Duplicate entries were eliminated, and allographs previously listed under separate numbers were consolidated into unified entries. The Text Database and Dictionary of Classic Mayan project builds on these foundational efforts. In order to preserve the continuity and scholarly integrity of Thompson’s numbering system, the project adopted it in its original form - effectively “freezing” the existing catalog - and introduced newly identified glyphs beginning at number 1500. This approach strikes a balance between honoring the legacy of earlier research and enabling systematic expansion in line with the demands of current scholarship. The present revision is based on Thompson’s so-called “Gray Cards,” a set of original documentation cards from the estate of Thomas Barthel, now held in Tübingen.[1] These materials were subjected to critical source analysis and comprehensively revised by the project team. The entire sign catalog was re-evaluated and reorganized in light of current epigraphic understanding, with particular attention to duplicate entries, misclassifications, and structural inconsistencies. As part of this process, Christian Prager produced standardized, refined drawings of all glyphs and their variants, ensuring visual consistency and analytical clarity.
A comparison of the major glyph catalogs published up to 1963, including the revisions by Grube (1990) and Ringle & Smith-Stark (1996) illustrates key differences in the classification systems and the scope of each catalog. Table 1 presents numerals, affix groups, and main sign groups, further subdivided into formal-semantic categories, along with the total number of documented signs. The revision carried out by the TWKM project revealed that only 482 of the 862 graphemes originally catalogd by Thompson remain valid, representing a reduction of nearly 50%, primarily due to the elimination of misclassifications and duplicate entries.
| Catalog | Numerals | Affixes | Main Signs |
Number of Signs | ||||
| Human portraits and body parts, face and face-oid | Animal, heads and body parts | Conventional, ornamental, abstract | Colors, cosmology, calendaric-astronomic | "purgatory" | ||||
| Gates 1931 | 57-59 [0-19][2] [0-10][3] |
600-620, 631-650, 657, 661-674, 676-690, 700-701, 704-708, 710-721, 723-728, 741-754, 756-757 |
71-83, 87-93, 95-96, 98, 101, 103-115, 119, 120-123, 125-127, 141-145, 147-148 |
201-217, 221-223, 225-228, 230-232, 241-251, 261-271, 275-277, 279-280, 291-293 |
301-307, 310-314, 317-349, 351-359, 361-412, 421-422 426-438 |
1-25, 26-44, 45-56, 66-70, 446, 451-455, 458, 466-497 |
476 | |
| Zimmermann 1956 | I-XIII | 1-91 | 100-169 | 700-763 | 1300-1377 | 316 | ||
| Evreinov et al. 1961 | [I-XIX][4] | 3-4, 6, 10, 12-15, 17, 21-27, 30-36 40-41, 43-45, 47, 50-51, 53-57, 60-67, 70-77, 100-105, 107, 110-117, 120 |
233-236, 240 242-247, 250-255, 261-267, 270 272-276, 300-307, 310-317. 523, 525-526, 530-532, 537 |
320-323, 325-327, 331-337, 340-347, 350-354, 357, 450-452, 454-457, 460-467, 470-473, 475-477, 544-546, 550, 552, 554-557, 560-561, 563-565 |
121-125, 127, 130-137, 140, 142-147, 150-151, 153-156, 170-177, 200, 202-204, 206-207, 210, 212-216, 220-227, 230, 360-363, 365-367, 370-371, 373, 375, 377, 400-401, 403-407, 410-411, 413-417, 420-427, 430, 432-437, 440-447, 500-506, 510-517, 520, 522, 536, 537, 541, 543, 570, 573-575 |
326 | ||
| Thompson 1962 | [I-XIX][5] | 1-370 | 666-673, 710-714 (hands), 700-705 (body), 1000-1087 | 734-766, 788-804, 828-829, 832, 839, 844, 845, 849 | 501-665, 674-699, 706-709, 715-733, 767-787, 805-827, 830-831, 833-838, 840-843, 846-848, 850-856 | 1300-1347 | 862 | |
| Knorozov 1963 | [I-XIX] | 1-110, 415-446 |
202-272, 314-317, 341-343, 472-516, 524-525, 534-535 |
273-297, 318-322, 344, 376-414, 517-519, 536-540 |
111-201, 298-313, 323-340, 345-375, 447-471, 520-523, 526-533 |
560 | ||
| Grube 1990 | 1, 3-4, 8, 10, 12-13, 15-17, 19-21, 23-26, 28, 30, 32, 42, 44-45, 47, 50-52, 55-57, 59-61, 63, 66-70, 73-75, 78-82, 84, 86-89, 93-95, 97-98, 100, 102-112, 114-124, 128-130, 132, 134-137, 139, 142-145, 147, 149-157, 159, 161-163, 165, 168, 171-177, 181-187, 190, 192-199, 201-204, 206-218, 221-227, 231, 233-242, 244-245, 248-251, 253, 256, 262-274, 278, 281-288, 290-292, 294-297, 299, 301, 304-306, 309-310, 314, 316, 318-319, 321, 325-327, 329, 335-338, 340-341, 348, 351, 358, 361, 363-364, 367-368, 370 1304-1305, 1320, 1330, 1335-1336, 1339, 1341 |
667-670, 672, 700, 702, 704-705, 710-711, 713-714; P1-132 |
734, 736-737, 740-742, 744-749, 751-753, 755-761, 763-766, 789-790, 792-804, 829, 832, 839, 844-845 |
501-504, 506-507, 509-514, 516, 518-530, 533, 535-545, 547-555, 559-567, 569-572, 574, 576-577, 579-580, 582-585, 587-590, 594-597, 600, 604-606, 610-611, 613, 622-623, 625-631, 633, 639-641, 643-644, 646-649, 651-653, 656-657, 659-660, 662, 674-676, 678, 680-682, 685-687, 692, 694, 696-697, 699, 708-709, 717, 721, 723-727, 729-733, 768, 770, 776-777, 784-785, 805-806, 808-810, 812, 816-817, 819, 822, 824, 833-837, 842-843, 847, 855-856, A1-A49 |
1304-1305, 1320, 1330, 1335-1336, 1339, 1341 | 658 | ||
| Ringle & Smith-Stark 1996 | 1-2, 4-5, 7-8, 10, 12-13, 15-17, 19-21, 23-25, 28, 31-32, 34, 36, 42, 44-45, 50-52, 54-61, 64, 66-70, 74, 76, 78-79, 82-84, 86-89, 93-96, 98-100, 102-103, 105-110, 112-117, 119-125, 127-130, 132, 134-137, 141-156, 158-160, 162, 164-170, 172-176, 178-179, 181-182, 184-188, 190, 193-194, 197-201, 203-204, 206-208, 210, 212, 214, 216-223, 225-228, 230-234, 236-241, 243, 245, 249, 251, 253, 255-256, 263, 265-269, 271-274, 276, 278, 281-284, 287-288, 291, 294-299, 301, 303-304, 306-309, 312-316, 318-319, 321-323, 325-331, 333-343, 348, 351, 355-356, 358, 361-364, 366-370, 401-427 |
667-673, 700-705, 710-714, 1000, 1003-1019, 1021-1023, 1026-1057, 1059-1068, 1070-1071,1073-1078, 1080-1087, 1092, 1101-1161 |
734, 736-752, 754-766, 788-799, 801-804, 828-829, 832, 839, 844-845, 849 |
501-530, 533, 536-546, 548-556, 559-570, 572-574, 576-588, 590, 592-598, 600, 604-611, 613-616, 618-619, 622-623, 625-637, 639-642, 644-654, 656-660, 662-664, 674-676, 678-681, 683-690, 692-697, 699, 706-709, 715-718, 720-722, 724-733, 767-771, 774, 776-777, 779-780, 782-784, 787, 805-806, 808-813, 816-819, 823-824, 826-827, 830-831, 833-838, 840-843, 847, 850-851, 853-856, 901-957 |
781 | |||
| TWKM (2025) | 1, 4-5, 11-12, 15-17, 19-21, 23-25, 28-29, 31-32, 42, 44-45, 53, 55, 57-61, 64, 66-69, 73-74, 77-79, 82, 84, 86-89, 93, 95, 97-99, 102-104, 106, 108-110, 112, 114-117, 120-124, 126, 128, 130, 135-137, 139, 145, 149-153, 155, 157-159, 164, 168, 170, 172-178, 181-188, 190, 192-195, 197-200, 203-204, 206-208, 210-212, 214, 216, 218, 220-227, 229, 231, 233-234, 236-241, 243, 249-251, 257, 265-269, 271-274, 278, 281-282, 284-285, 287, 290-291, 294-297, 299, 301, 304-305, 307, 309, 316, 325-327, 329, 335-337, 339-340, 346, 348, 351, 355, 358, 361, 364, 367, 369-370 |
667-673, 700-705, 710-714, 1000, 1003-1009, 1011, 1013-1014, 1022, 1024-1028, |
734, 737-742, 744, 746-752, 754-761, 763-766, 789, 791, 793-799, 801-804, 828-829, 832, 839, 844 |
501-514, 516, 519-521, 523-530, 533, 535-545, 547-552, 554, 559-561, 563-566, 568-570, 572-574, 576-580, 582-586, 588, 590, 592, 594-598, 600, 604, 606-607, 609-611, 613-614, 617, 622-628, 630, 632, 643-648, 650, 653, 656-657, 659, 662, 665, 674-675, 678-681, 684-686, 692, 696-697, 699, 708-709, 716-718, 721-725, 727-733, 767-768, 770, 779-780, 785, 805-810, 812, 819, 824, 827, 830-831, 834-835, 837, 840, 843, 855-856 |
1304, 1320, 1341 | 482 (of 1048) | ||
| Table 1. Comparison of major glyph catalogs published up to 1963, including the revisions by Grube (1990) and Ringle & Smith-Stark (1996). | ||||||||
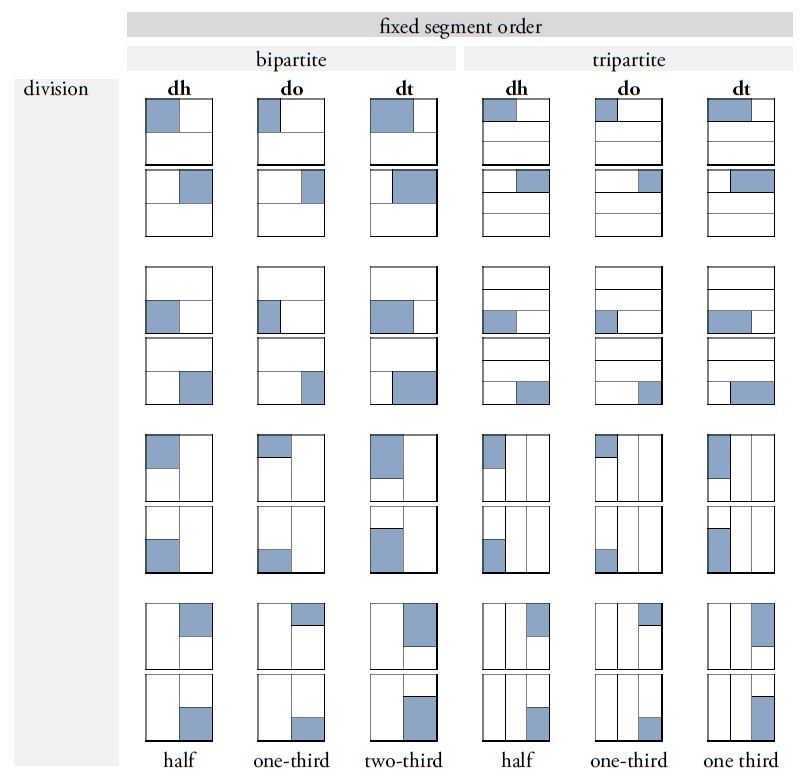
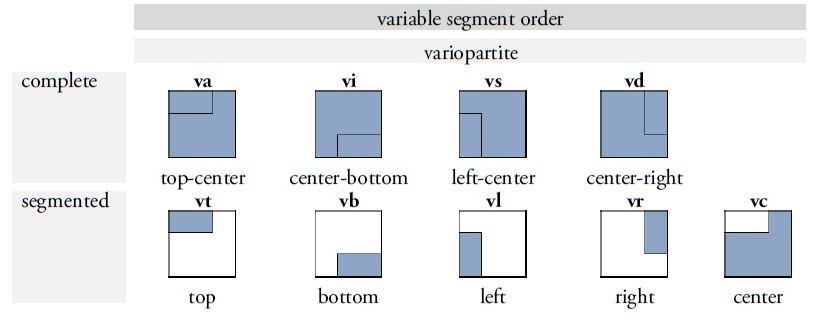
An important advancement in the revision of Thompson’s catalog lies in the introduction of an expanded classification system that significantly facilitates the differentiation and naming of graph variants. Thompson’s original method - labeling variants with arbitrary lowercase letters - has been replaced, following the model proposed by Prager and Gronemeyer (2018), with a two-letter coding system that allows for more precise distinctions among variant forms (Figure 4). This new system is based on the observation that many Maya signs can be segmented - either horizontally or vertically - into two or more graphical units, or appear in representational forms depicting animals, humans, or deities as heads or full figures. These segmentations and transformations not only enable a clearer visual differentiation of variants but also support a systematic organization based on the underlying principles of graphical variation. The position and structure of individual segments are indicated using standardized codes such as "bt" or "bv". The letter b stands for bipartite graphs (those composed of two distinct components), while v (vertical) indicates that the segmentation occurs along the vertical axis. The code "bt", for example, refers to a bipartite graph variant in which only the upper segment ("t" for top) is rendered. Another aspect of the revised system is the inclusion of so-called pars pro toto representations, in which a part of a graph stands in for the entire grapheme. These variants are marked with the code "ex". This paleographic convention enables more compact spatial arrangement within glyph blocks while preserving the linguistic value of the signs, and at the same time contributes to the script’s aesthetic richness. The expanded system also accounts for graphical transformations such as the duplication of elements - marked with "m" (for multiple) - and animation, in which graphs are rendered in anthropomorphic or zoomorphic form. If a typically geometric or abstract graph is represented as a head, it is coded as "h" (head). Further specification is provided by an additional letter: "hh" (head human) indicates a human head, while "hc" (head creature) denotes animal or hybrid forms. Full-figure representations are marked with "f" (full), with "fh" (full human) for anthropomorphic figures and "fc" (full creature) for zoomorphic or composite forms.
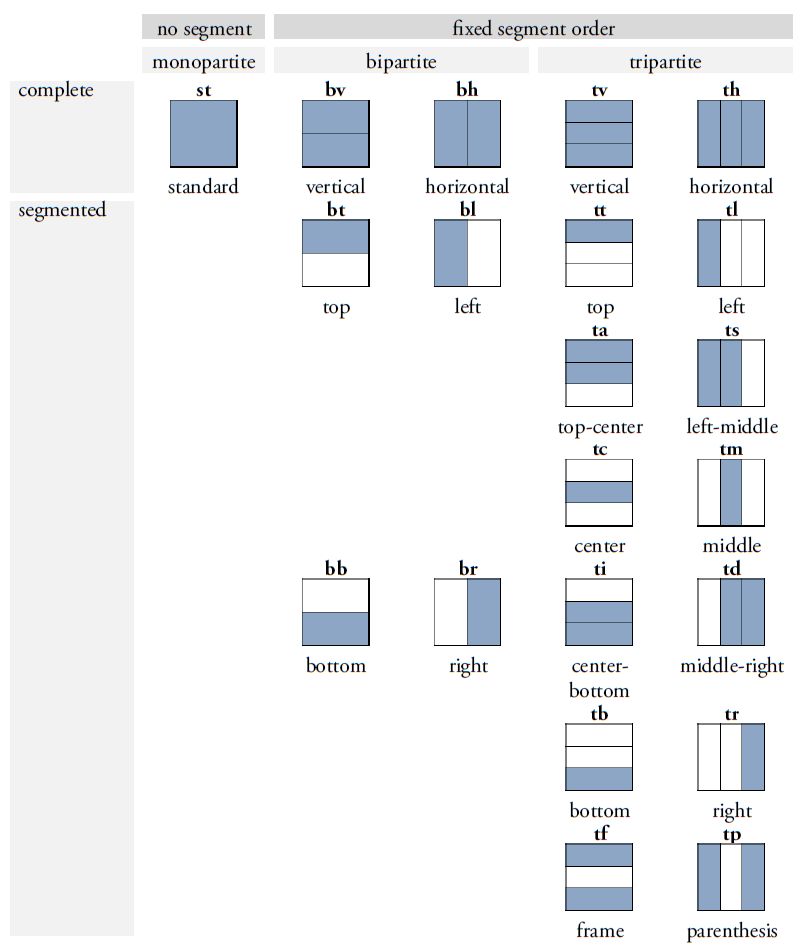 |
 |
|
|
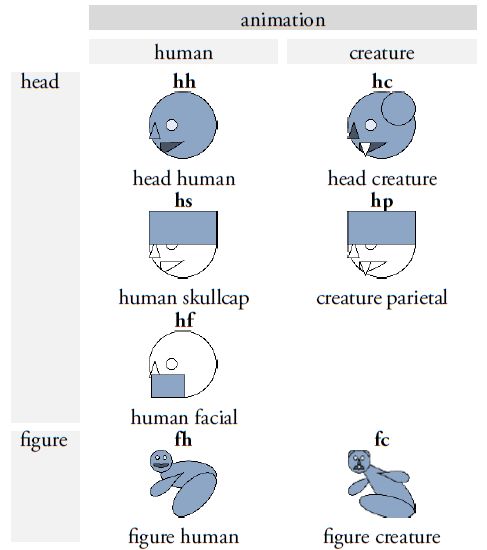 |
| Figure 4. Overview of the most common segmentation and transformation types in Maya script. The binary letter codes refer to specific patterns of variation and are appended to the respective sign number to enable precise identification of individual graph variants according to their structural segmentation and transformation schema. Original illustrations adapted from Prager and Gronemeyer (2018:figs. 11, 12, 14, 17, and 20). Illustrations: Sven Gronemeyer. | |
The graphic diversity and playful design of Maya signs reflect underlying conceptions of the animacy of linguistic expression and its material inscription, as well as the scribes’ deliberate efforts to achieve an aesthetically refined calligraphy without compromising the legibility of the written language. Thompson’s numerical system provides an excellent foundation for extending his catalog through variant coding - an idea he had already envisioned during the compilation of his catalog (1962:5). He conceived of his sign list as a dynamic tool, one that should be continuously expanded and refined. The current revision, with its reclassification of signs, realizes this vision by preserving the integrity of Thompson’s numbering system, resolving longstanding inconsistencies, and introducing innovative methods of classification. By systematically integrating paleographic variants, the revised catalog not only documents the aesthetic range of the glyphs but also captures their functional distinctions within the writing system. These advances address the limitations of the original catalog and open up new avenues for analyzing the visual and structural diversity of Maya script. The revised version of Thompson’s catalog thus unites historical foundations with the demands of contemporary research, establishing a new digital instrument for the documentation and analysis of Classic Maya writing.
Classification and Principles of Organization
Owing to its systematic and aesthetically thoughtful structure, Thompson’s catalog remains a widely cited reference in the scholarly study of Maya script. The classification system he applied to monumental inscriptions was based on earlier catalogs by William Gates (1931) and Günter Zimmermann (1956), which focused on the three Maya codices then known. In addition, Hermann Beyer’s analyses of hieroglyphic signs in their textual context contributed significantly to refining the distinction - introduced by these earlier works but now considered problematic - between so-called main signs and affixes (Beyer 1930; 1934a; 1934b; 1936). Thompson primarily arranged signs according to visual and iconographic criteria, building upon and refining the categories established by Gates, Zimmermann, and Beyer. Of particular note is his differentiation between affixes, main signs, and portrait glyphs, which he systematized through distinct number ranges. Affixes - originally termed “minimal signs” by Beyer and more precisely defined by Zimmermann as narrow signs with a height-to-width ratio of 2:1 or 3:1 - typically occur in combination with larger main signs within glyph blocks. In Thompson’s catalog, they are listed under numbers 1 to 370, with detailed illustrations of their allographs showing typical positions and paleographic functions within the hieroglyphic system. This distinction between affixes and main signs reflects the dominant understanding of Maya writing at the time, which interpreted the script as purely logographic. In this model, main signs were viewed as lexical roots, while affixes were seen as prefixes, suffixes, or adjectival modifiers. Thompson deliberately reserved space for future additions: the affix section ends at number 370, allowing for an expansion up to number 500 (Thompson 1962:5). Numbering for main signs begins at 501 and extends to 856. These signs tend to have more balanced, often square or rectangular proportions and exhibit wide iconographic variety - including depictions of humans, animals, hybrid beings, cultural artifacts, environmental motifs, and symbolic elements from Maya cosmology. However, the interplay of these elements often makes it difficult to assign a glyph unambiguously to a single category. Moreover, many graphemes defy straightforward iconographic identification and remain taxonomically challenging.
The limitations of a purely iconographic classification system - particularly in comparison with the Egyptian hieroglyphic tradition, which was successfully systematized by Alan Gardiner - have been increasingly evident in Maya epigraphy. Projects such as those by Rendón y Spescha (1965) and by Martha Macri, Matthew Looper, Gabrielle Vail, and Yuriy Polyukhovich (Macri and Looper 2003; Macri and Vail 2009; Looper et al. 2022) sought to emulate such an approach. However, in the most recent version of their inventory (2022), the limitations of this method became particularly apparent. Macri, Looper, and Vail revised their earlier classifications and introduced new, in part conflicting, sign codes. While this underscores their effort toward improvement, it also reveals inconsistencies and raises doubts about the long-term coherence and sustainability of their system. Implicitly, this also signals the need for alternative classification methods. Thompson himself acknowledged inconsistencies in his own system, particularly regarding the strict separation of affixes and main signs. He noted that approximately 60 affixes occasionally functioned as main signs - a fact he marked in his catalog by appending the abbreviation “M.S.” (Main Sign) to the sign number (Thompson 1962:14). Main signs functioning as affixes were annotated with “af” (Thompson 1962:34). Thompson also left deliberate gaps in the numbering system from 857 to 999 to accommodate future additions to the main sign set. Portrait glyphs were categorized beginning at number 1000. This group includes signs depicting individualized human or hybrid mythological figures, though the boundaries between human and supernatural forms are often fluid. Signs that could not be clearly classified were placed in a provisional group numbered 1300 to 1347, which Thompson referred to as the “purgatory group.” This section was revised by Grube (1990), who reclassified or removed most of the entries, with the exception of numbers 1304 and 1327.
The iconographic complexity and still largely undeciphered meanings of many glyphs and their variants continue to present considerable challenges to systematic classification. Compared to scripts such as Egyptian hieroglyphs - rendered into a coherent system through Gardiner’s catalog - the systematization of Maya script remains considerably more complex. Thompson’s catalog, developed in response to the practical needs of documentation and research, reflects this complexity. Toward the end of his work, Thompson increasingly moved away from strictly iconographic groupings and began integrating newly discovered signs chronologically, assigning them sequential numbers regardless of their morphological characteristics. This dynamic approach underscores the flexibility of his system and highlights the need for adaptable methodologies in the study of Maya writing. Despite its limitations, Thompson’s catalog remains an indispensable tool in Maya epigraphy. Its systematic and comprehensive scope, as well as its enduring status as a scholarly standard, ensure its continued relevance. This is reflected not only in its extensive citation but also in its broader impact compared to both earlier and later catalogs, many of which were limited in scope or methodology. The structure of our digital catalog seeks to bridge early foundational efforts with contemporary, digitally supported methods of research. Experience over the past decades has shown that numerical coding of signs should be implemented independently of iconographic classification - an approach particularly well suited to digital environments. Within the framework of this project, we have therefore developed a dynamic and adaptive catalog that enables flexible sorting, filtering, and modification of signs according to linguistic or iconographic features (Figure 5). In this system, numerical codes serve solely for unambiguous reference to signs and graphs, without predetermining or being shaped by their iconographic properties (Diehr et al. 2018).
|
|
 b b |
 c c |
| Figure 5. Selection of filtering and display options in the digital catalog: (a) displays an (alpha)numerical ordering of graphemes with catalog numbers 501 to 510; (b) arranges the same group according to their overall frequency within the text corpus; (c) shows the 28 most frequently occurring graphs in the Pusilha text corpus. Drawings by Christian Prager. | ||
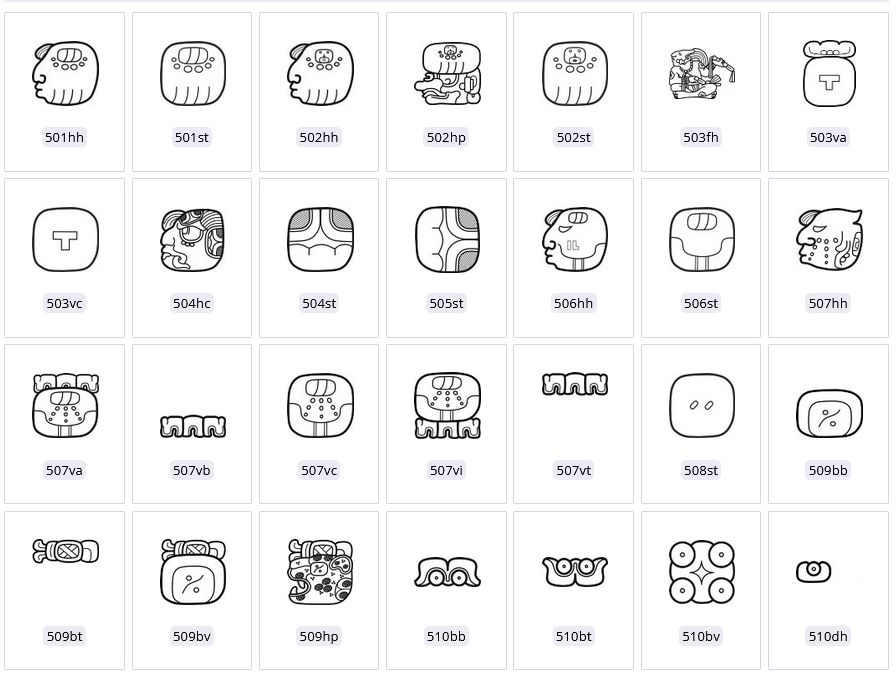 a
aSigns not included in Thompson’s original catalog have been added to the inventory of Maya script signs beginning at catalog number 1500, regardless of their morphological characteristics. Within the virtual research environment TextGrid, these new signs are documented using controlled vocabularies that allow for precise and systematic description of their graphic features. The vocabularies “graph composition” and “iconography” combine formal descriptors with iconographic content categories, enabling signs to be classified and analyzed both by external features - such as narrow or broad proportions - and by semantic motifs, including animals, humans, or artifacts. This flexible and dynamic methodology offers users not only efficient tools for identifying and sorting signs, but also the means for in-depth analysis that takes into account both formal and semantic dimensions. In doing so, it provides a significant contribution to the systematization and study of Maya script in the digital age, while maintaining continuity with earlier catalog traditions. Digital concordances that incorporate scans of original drawings allow users to directly compare previous classification systems with the current digital sign catalog. This feature makes it possible to contextualize the sign typologies and methodological approaches of the past hundred years within the framework of contemporary research. As a result, the project fosters continuous scholarly reflection and the ongoing refinement of Maya epigraphy, promoting transparency in the research process and strengthening the bridge between traditional and digitally informed approaches.
Iconicity and Formal Analysis of Maya Hieroglyphs
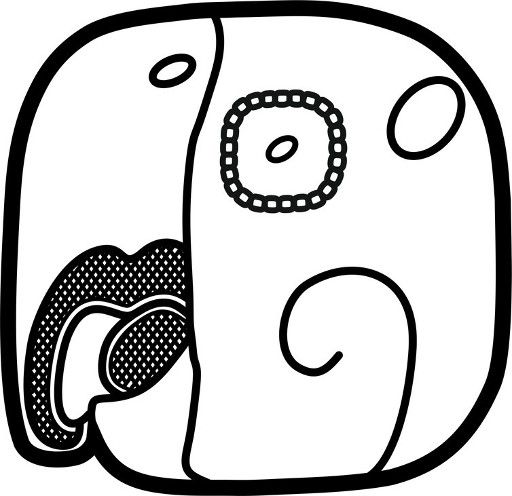
Hieroglyphic writing systems are characterized by a high degree of graphic diversity, intricately interwoven with cultural motifs and symbols that form the basis for linguistic expression (cf. Stone and Zender 2011). A sign in such systems is not merely a graphic element, but a semiotic unit that conveys meaning. Following the theories of Peirce and Saussure, each sign combines a material form, signifier (signifiant), that is, the grap, with a conceptual content, the signified (signifié), or linguistic meaning (see Figure 1). The meaning of a sign often arises from the linguistic representation of the depicted object. In this context, the iconic character - the visual resemblance between a sign and its referent - plays a key role, although it is not always unambiguous (Figure 6). Many signs in the Maya script, moreover, carry symbolic or abstract meanings that have been shaped by cultural and historical developments. In particular, the iconic origins of numerous Maya signs remain obscure, complicating both their interpretation and their ontological classification. Nevertheless, these signs function as carriers of linguistic, cultural, and aesthetic information - dimensions that can be explored through the analysis of form, function, meaning, and use.
 |
 |
 |
 |
 |
 |
| Icon: parrot (head) | Icon: deer (head) | Icon: hand with fish | Icon: iguana (head) | Icon: stepped platform | Icon: ? |
| MO' "parrot" | CHIJ "deer" → chi (syllable) | TZAK "to grasp, conjure" | SIH "to present" |
? |
? |
| Iconic image-sound relationship |
Semantic image-sound relationship | Ambiguous image-sound relationship[6] |
Unresolved image-sound relationship[7] |
Indeterminate image-sound relationship[8] | |
| Figure 6. Typology of image-sound relationships in Maya writing. Concept and illustration: Christian Prager, 2025. | |||||
Iconological analysis, which focuses on the formal features and pictorial content of signs, constitutes an indispensable tool in epigraphic research. It enables the identification and classification of signs while also offering valuable insights into their cultural and semantic contexts. This is particularly relevant in writing systems such as Maya and Egyptian hieroglyphs, where writing and imagery are deeply interwoven. In the case of Maya script, investigating the graphic origins of individual signs remains a foundational but still nascent area of study - see, for instance, the iconographic analysis of 100 signs by Andrea Stone and Marc Zender (2011). Such research forms the basis for deciphering both the function and meaning of glyphs within their linguistic and cultural frameworks. Semiotic analysis complements this iconological approach by systematically examining the complex relationships between form, function, meaning, and use. This differentiation is essential for a comprehensive understanding of the structure and dynamics of hieroglyphic writing systems.
Formal-Semantic Approaches of Classification
A first systematic attempt to classify the elements of Maya writing was undertaken by William Gates in 1931 (Figure 7). His catalog, based on the glyphs preserved in the Maya codices, was informed by an earlier, unpublished inventory compiled by Charles C. Willoughby in the early 20th century, now held at the Peabody Museum. Gates placed strong emphasis on iconographic determination, organizing glyphs according to their visual characteristics (Table 1). He divided the signs into twelve image-semantic categories - such as day signs, month signs, calendrical elements, directions, numerals, portraits, and animals - in an effort to bring structure to the rich visual diversity of the script. Though ambitious in scope, Gates’s classification reveals significant methodological shortcomings. His system conflated iconographic and semantic features with pragmatic aspects of sign usage, without establishing clear distinctions between these analytical levels. As a result, his approach hindered a coherent semiotic or linguistic interpretation of the glyphs, since neither their functional roles nor semantic values were treated in a systematic manner. Further complicating matters was a numbering scheme that proved inconsistent and difficult to follow, drawing criticism even from contemporaries. From today’s perspective, the need for a rigorous differentiation between form, function, meaning, and contextual use is essential for understanding the complex semiotic architecture of Maya writing. Gates’s contribution, while foundational in its time, now holds primarily historiographic significance. Nevertheless, his iconologically driven approach exerted a lasting influence: the practice of grouping signs by visual resemblance and perceived pictorial categories has informed subsequent cataloguing efforts (Rendón and Spescha 1965; Macri and Looper 2003; Macri and Vail 2009; Looper et al. 2022), albeit with varying methodological refinement. In the context of our current catalog project, these early efforts have been critically re-evaluated. We have sought to resolve their underlying inconsistencies by decoupling iconographic interpretation from the act of classification itself. By analytically separating form, function, and semantic value - and by integrating insights from semiotics, epigraphy, and historical linguistics - we aim to produce a classification system capable of reflecting the structural complexity of Maya script more faithfully and with greater methodological precision.
 |
 |
|
Figure 7. Page 11 from Gates’ original study accompanying his 1931 catalog of Maya script. William Gates notes on glyphs, approximately, before 1931, MSS 279 Series 3 Sub-Series 2, Box 13, Folder 5. William Gates Papers, MSS 279. L. Tom Perry Special Collections, Brigham Young University. https://archives.lib.byu.edu/repositories/14/archival_objects/53513 (accessed July 28, 2025). |
Figure 8. Original index card containing Zimmermann’s notes on the palaeography and occurrence of the syllable wa (T130) in the Dresden Maya Codex, prepared in advance of his 1956 publication. Image citation from: Günter Zimmermann, Schreiber der Dresdner Mayahandschrift, unpublished manuscript from the possession of the Department of Anthropology of the Americas, University of Bonn. |
In his 1956 publication on the hieroglyphs of the Maya codices, Günter Zimmermann (Figure 8) adopted a primarily formal-analytic approach. He defined Formenkunde or formal analysis as the systematic study and classification of Maya hieroglyphs based solely on their external structure and graphic composition, without anticipating their meaning (Zimmermann 1956:10). This approach centers on documenting the visual form of the signs with precision and neutrality, aiming for objectivity in the absence of full decipherment. Zimmermann’s system involves categorizing glyphs into main signs and affixes based on their size, position, and functional relationship. Affixes are further subdivided into prefixes, superfixes, postfixes, and suffixes, depending on their spatial placement in relation to the main sign. His classification relies on a structured notation system and numerical coding, intended to capture the formal properties of each sign independently of its semantic value. The result is a methodology that focuses on the graphic diversity and structural arrangement of glyphs across different texts and manuscripts. Semantic interpretation is deliberately withheld, in favor of a descriptive framework that prioritizes observable variation and visual placement. Like William Gates before him (1931), Zimmermann distinguished between two broad morphological categories: full, block-like main signs and narrower affixal forms, typically arranged around the central glyph. At the same time, he acknowledged that the line between these categories is often blurred and questioned whether such a binary distinction would have aligned with ancient Maya conceptual models (Zimmermann 1956:12). Zimmermann also proposed a subdivision of main signs into human, animal, and ornamental types, based on visual similarity - such as heads or body parts. Allographs were marked using lowercase letters, a convention later adopted by Thompson. His method thus bridged formal analysis and iconographic interpretation, though he admitted that signs were often assigned to categories using schematic visual criteria. As a result, semantically related signs were sometimes placed in different groups, based on superficial form alone. While this approach facilitated the cataloguing and retrieval of signs, it did not necessarily reflect their underlying meaning, origin, or function. From today’s perspective, this limitation is understandable, given the state of research in the mid-20th century. Still, certain signs - particularly those formally labeled as abstract or ornamental - could plausibly belong to other categories, such as animal or anthropomorphic signs. Glyphs with facial features or textural elements, for instance, may have been misclassified under purely formal criteria. These cases highlight the challenges of relying on visual form alone when classifying hieroglyphic signs. Complicating matters further is the fact that many iconographic elements remain ambiguous or difficult to identify. The visual referents of numerous signs are still uncertain, which opens the door to competing interpretations and classifications. Nonetheless, Zimmermann’s pragmatic three-part division brought much-needed order to a vast and complex corpus - and it remains a significant achievement. At the same time, it underscores the need for more precise classification criteria that integrate form, function, and meaning. Zimmermann’s vision of a comprehensive and systematic documentation of Maya glyphs - ambitious for its time - can now be fully realized through digital methods. Dynamically generated sign tables, which allow filtering and sorting by formal and semantic attributes, offer a far more adaptable way to organize glyphic data. Specialized catalogs can also be developed to focus on yet undeciphered signs, making a meaningful contribution to the ongoing decipherment of the script.
|
a |
b |
| Figure 9. Facsimiles of Thompson’s original grey cards from the estate of Thomas Barthel (University of Tübingen), which formed the basis of his 1962 catalog of Maya hieroglyphs. Each card contains either a drawing or a photograph of the relevant inscription, along with references to occurrences in the corpus and, where available, calendrical data—though the latter were not included in the published catalog. a) Card no. 9 with occurrence data for sign T501. Thompson’s catalog refers explicitly to individual card numbers, allowing direct comparison with his original notes. b) Card no. 435, cited on page 61 of the catalog, which addresses glyphic contexts for the sign T236 YAXUN. Only the critical evaluation of these original cards has made it possible to revise Thompson’s catalog comprehensively in the context of the present project. Reproduced with kind permission of Gabriele Alex, University of Tübingen (2025). | |


Zimmermann’s catalog and methodological framework ultimately laid the foundation for J. Eric S. Thompson’s 1962 sign inventory, which encompasses a total of 862 entries (Figure 9). These consist of 370 affixes, 356 main signs—including depictions of humans, animals, and their body parts—88 portrait glyphs, and 48 signs of uncertain classification. A close analysis of Thompson’s system reveals that the initial ordering of signs closely followed the structural logic of earlier catalogs by Zimmermann and Gates. Starting with sign number 501, Thompson applied a more systematic approach to the main signs, giving precedence to calendrical glyphs. These were followed by groupings based on formal visual features such as enclosing outlines, line motifs, crossed bands, dots, spots, and hatching—elements drawn from Zimmermann’s category of ornamental-abstract signs. Special attention was given to square or rectangular graphemes with well-defined contours. Within this structure, human and animal body parts such as hands and feet are listed between numbers 666 and 714, while animals and their components appear under numbers 731 to 766. However, further animal glyphs reemerge from number 788 onward, highlighting the inconsistencies in categorical organization. The signs between numbers 788 and 856 are formally and semantically heterogeneous, reflecting the ad hoc insertion of newly identified glyphs rather than a coherent classificatory logic. These inconsistencies point to the limitations of Thompson’s primarily form-based and semantic approach, particularly in the latter parts of the catalog.
Major revisions and expansions of Thompson’s inventory were introduced in subsequent studies, most notably by Nikolai Grube (1990) and later by William Ringle and Thomas Smith-Stark (1996). Grube introduced methodological refinements to address the structural shortcomings of Thompson’s framework. Central to his approach was the precise definition of a glyph as the smallest discrete unit—non-overlapping and self-contained. Complex glyphs composed of multiple components were treated as distinct entities only when their combinations generated new graphic or semantic properties. While this criterion is theoretically sound, rare or ambiguous combinations continue to pose classification challenges. Another crucial refinement involved the orientation of asymmetrical signs, whose semantic value could shift with rotation—an empirically attested phenomenon, though not always contextually clear. Grube also eliminated the traditional distinction between main signs and affixes, arguing that this dichotomy, while visually motivated, lacked functional consistency. Removing it allowed for the consolidation of redundant entries and improved the clarity and usability of the catalog. In addition, Grube introduced a separate, systematically structured category for portrait glyphs, marked by a prefixed “P.” His catalog of portrait glyphs included 132 entries, thus expanding Thompson’s original corpus by over 50 signs. Numerous glyphs previously treated by Thompson as distinct were recognized by Grube as allographic variants and consolidated into single entries, while others were removed due to insufficient documentation. Grube also incorporated approximately 50 newly identified abstract signs discovered after the publication of Thompson’s catalog, assigning them an “A” prefix to distinguish them from legacy entries. These additions marked a significant advance but also raised questions about how to maintain coherence and continuity with Thompson’s numbering system. The challenge lay in adapting the catalog into a dynamic, methodologically robust research tool without compromising its historical usability or referential integrity. These principles were adopted and further developed in the context of the present digital catalog. The digital approach taken by Ringle and Smith-Stark, published roughly six years after Grube’s study, complemented his revisions by making them accessible through computer-based systems—distributed via CD-ROMs for wider scholarly use. Their overhaul of Thompson’s catalog likewise rejected the rigid division between main signs and affixes, opting instead for a more flexible classification system based on graphical and functional attributes. Glyphs were defined primarily through formal criteria, with modifications such as scaling also taken into account. Portrait glyphs and head variants received new designations, with head glyphs marked by “H,” while newly added glyphs were incorporated via an extended numbering scheme, echoing Grube’s model—though without explicit reference to it. Even Thompson’s so-called “purgatory group” was addressed and reclassified. Ringle and Smith-Stark’s revision, though methodologically distinct, aligned with Grube’s enhancements while preserving compatibility with Thompson’s legacy structure (Figure 10). In the context of our current digital catalog, we have undertaken a further revision of Thompson’s inventory, building on the foundational work of Grube and Ringle & Smith-Stark. However, unlike the latter, we have chosen not to reassign Thompson’s unused catalog numbers to new glyphs. Instead, newly identified signs have been systematically integrated into a distinct numerical range beginning at 1500, thereby maintaining the historical continuity of Thompson’s original schema while allowing for flexible future expansion.
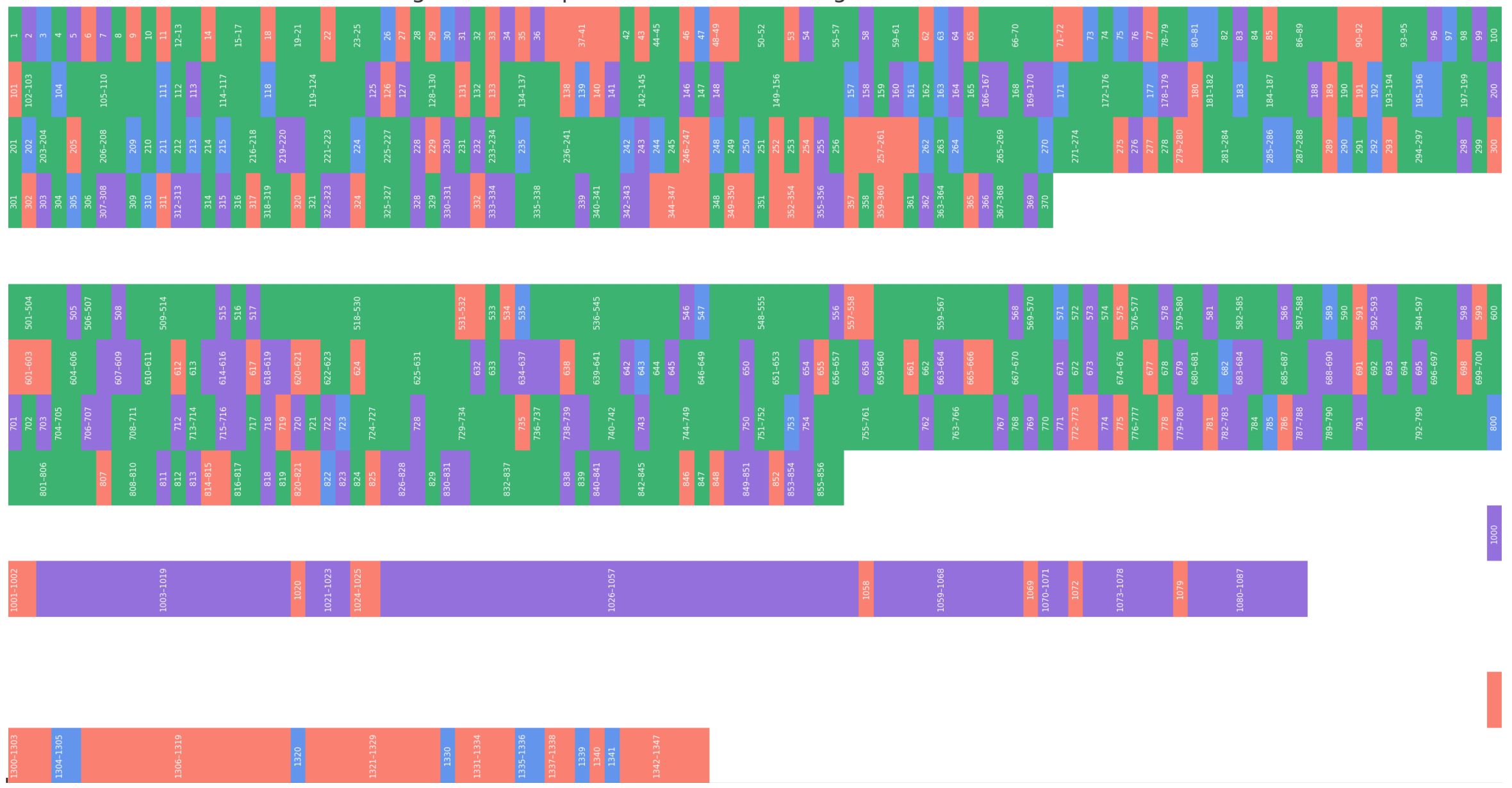 |
| Figure 10. Visualization of the revisions made by Grube and Ringle & Smith-Stark to Thompson’s 1962 catalog of Maya glyphs. Glyphs highlighted in red represent signs from Thompson’s catalog whose classification or nomenclature was rejected by Grube (1990) and Ringle & Smith-Stark (1996). Green indicates glyphs that were adopted unchanged by both revisions; blue marks those retained exclusively by Grube; and violet highlights those preserved only by Ringle & Smith-Stark. Concept and graphic design: Christian Prager (2025). |
Between 1961 and 1963, immediately before and after the publication of J. Eric S. Thompson’s catalog of Maya glyphs, two additional catalogs focusing on the hieroglyphs of the Maya codices were produced (Figure 11a-b). The first was compiled under the direction of mathematician Eduard Evreinov (Evreinov et al. 1961), and the second was authored by Yuri Knorozov (1963). Evreinov’s catalog was directly based on the work of Knorozov, and both are characterized by a closely related classificatory framework. This makes them particularly valuable for comparative analysis. Evreinov’s publication marked a significant milestone in Maya epigraphy, as it was the first to systematically apply digital technologies to the study of Maya writing. For the first time, computational tools were used to investigate the structural composition of hieroglyphic texts. Glyphs from two Maya codices were transcribed into numerical codes, transferred onto punch cards, and analyzed with early electronic computing machines. These lexicometric investigations focused on the frequency, distribution, and co-occurrence patterns of individual signs, glyph clusters, words, and recurring sequences. The resulting data were then cross-referenced with linguistic and statistical information derived from Yukatek Maya texts as well as colonial-era dictionaries from the sixteenth and seventeenth centuries in order to support hypotheses concerning glyph decipherment. Despite these innovative efforts, the project ultimately failed to produce sustainable results, due to fundamental misjudgments regarding the structure and function of the Maya script. The computational analyses were not capable of adequately modeling the complex linguistic and semiotic relationships that define the script. As a result, the approach was largely dismissed shortly after publication (Schlenther 1964).
Both of these early catalogs adopted a morphologically oriented classification system. Signs were categorized into narrow and broad forms, and further subdivided into affixes and main glyphs. Each glyph was assigned a unique numerical identifier starting from number one, ensuring clear reference and traceability. The internal organization of the catalogs followed a principle of increasing visual complexity, based on the number and configuration of sub-graphemic and intra-glyphic elements. Although these components do not carry meaning on their own, they play a decisive role in shaping the visual and compositional character of the signs. The classificatory logic employed in these catalogs reveals striking parallels with systems used in other writing traditions, particularly in cuneiform and Chinese script. In cuneiform, as outlined by Borger (2010), simple base signs composed of only a few wedge-shaped strokes serve as building blocks for more elaborate configurations. Similarly, Chinese characters are constructed from radicals, which not only define the graphic structure but also contribute semantic information. The ordering of characters in Chinese dictionaries is typically based on stroke count and radical position (see Shen Xu 1981). This comparative perspective underscores the methodological relevance of visual structure in the classification of complex script systems, including that of the Maya.
|
a |
b |
c |
| Figure 11. Comparative overview of morphologically ordered glyphs from the Maya codices: a) Excerpt from Knorozov’s catalog showing narrow signs and affixes (glyphs 1–110), grouped systematically according to axes of rotation and sub-graphemic structures; b) Additional glyphs from Knorozov’s classification, including abstract and more complex forms (from glyph 111 onward), organized by overall shape and visual complexity (Images 11a and 11b reproduced from Knorozov 1963:307, 309); c) Idealized glyphs from Tokovinine’s sign list (Tokovinine 2017), rendered in a stylized, font-like format that highlights structural features and represents a methodological continuation of Knorozov’s approach (Image excerpt from Tokovinine 2017:11, courtesy Alexandre Tokovinine). | ||
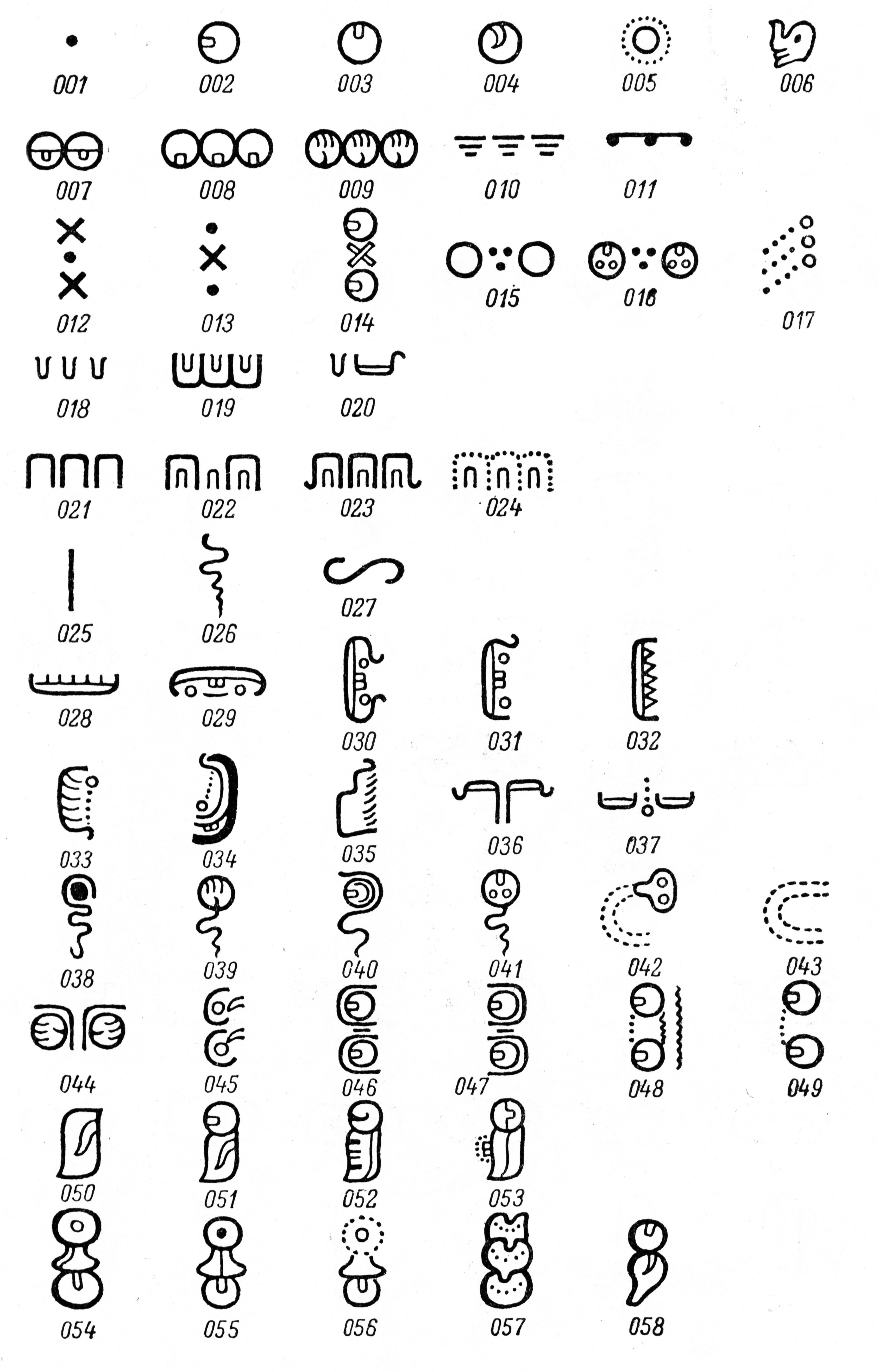

In contrast to the Chinese and cuneiform writing systems, semantic information plays only a secondary role in the catalogs compiled by Knorozov and Evreinov. Instead, classification is based primarily on visual similarity. Glyphs are grouped into subcategories whose members share external and internal visual characteristics—so-called sub-graphemic structures. Knorozov’s catalog follows a systematic classification that incorporates both morphological and functional criteria. Narrow signs and affixes (glyphs 1–110) are grouped according to their axis of rotation, distinguishing between vertical and horizontal variants. From glyph 111 onward, broader signs are organized by external form, including enclosed outlines and ornamental features. Human faces appear beginning with glyph 202, hands are listed from glyph 258, and animal-like heads from glyph 273. Glyphs with dotted outlines begin at 298, while those with open contours appear from 310 onward. Unclassifiable signs are grouped from glyph 318, arranged by general shape and visual outline. Knorozov’s catalog includes a total of 414 glyphs from the codices and is extended by graphemes found only in monumental inscriptions, increasing the inventory to 540 signs. The same classification principles applied to the codices were also used in organizing the monumental inscriptions.
These formal and semantic "family resemblances" provide a structural framework for organizing the script, independently of the linguistic value of the signs—which at the time of catalog compilation remained largely undeciphered. This visually oriented system was later revived and refined by Alexandre Tokovinine (2017), whose sign list builds directly on Knorozov’s methodology (see Figure 11c). Like Knorozov, Tokovinine illustrated his catalog with prototypical drawings that emphasize diagnostic features of each glyph. These idealized representations possess a font-like quality, highlighting essential structural and internal elements that are paleographically attested and intentionally incorporated into the sign’s visual design. While each glyph in Thompson’s catalog is based on a single representative example drawn from thousands of documented variants, Knorozov and Tokovinine developed idealized graphemes that synthesize key features into a stylized, typologically diagnostic form. Tokovinine’s classification system further distinguishes between rotatable and non-rotatable glyphs, core and peripheral variants, and simple versus compound signs. Drawing on principles first articulated by Hermann Beyer nearly a century earlier, Tokovinine expands this foundation by emphasizing visual similarity, structural complexity, and spatial position within a glyph block. Building on this tradition, our project also adopts and adapts this methodology to develop a refined framework for the digital analysis of Maya glyphs. In this context, Christian Prager created idealized, prototypical graphemes modeled on the approaches of Knorozov and Tokovinine. These form the core of our digital catalog and are designed to serve not only as epigraphic tools but also as the basis for future typographic representations of the Maya script.
Iconographic and Morphological Approaches to Classification
A systematic classification of Maya glyphs grounded in their iconographic characteristics was first developed in 1965 by Juan José Rendón and Amalia Spescha as part of a digitization initiative focused on the Maya codices (Figure 12). Their approach represented a marked departure from earlier systems proposed by scholars such as Gates, Zimmermann, Evreinov, and Thompson. Crucially, Rendón and Spescha introduced an alphanumeric coding scheme in which a letter denoted a glyph’s affiliation with a particular iconographic category, while a sequential number identified its position within that group. This structure allowed for greater analytical precision and methodological flexibility. The classification was based on visual resemblance and thematic association, organizing glyphs according to recurring iconographic motifs. Signs were grouped into categories that reflected both formal and semantic dimensions—for example, closed and filled shapes, crossed or grouped forms and hand motifs, elements resembling ropes, loops or knots, as well as wings, woven textures, arcs, feathers, hooks, flowers, small animals, and various anthropomorphic and zoomorphic heads. Portrait-like faces and numerical signs were also identified as discrete categories. Rather than imposing a rigid distinction between so-called main signs and affixes, Rendón and Spescha recognized that such a differentiation lacked consistent functional grounding. Consequently, their system eliminated this division altogether, emphasizing instead the fluid interplay of graphical form and semantic potential. By integrating both morphological detail and iconographic context, this approach provided a more nuanced framework for understanding the structure of the Maya script—one that moved beyond the taxonomic limitations of earlier catalogs and anticipated more integrative models of script classification.
|
a |
b |
| Figure 12. Classification of Maya glyphs according to iconographic groupings in the catalog by Rendón and Spescha (1965). The signs are organized based on visual and semantic resemblance and are assigned fixed alphanumeric codes for their respective category. a) Signs from category C (depicting ropes, loops, and knots); b) Signs from category I (abstract and anthropomorphic heads). This classification system deliberately abandons the traditional distinction between main signs and affixes, instead grouping glyphs by shared iconographic traits. Although this method represents a significant innovation in the structural analysis of the script, its heavy reliance on visual analogy posed challenges for the unequivocal assignment of individual signs. Image citation from Rendón and Spescha (1965:212, 224). | |
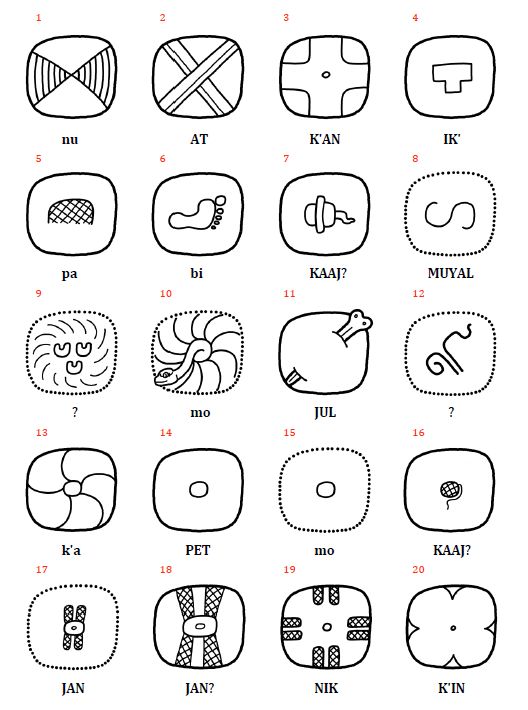
Although the classification system introduced by Rendón and Spescha provided a relatively intuitive structure for navigating their glyph catalog, it also introduced several methodological challenges. One of the principal concerns relates to its heavy reliance on iconographic analogies. Organizing glyphs primarily based on visual resemblance creates considerable potential for subjective interpretation. In cases where the iconographic identity of a sign was ambiguous or remained unresolved, the outer shape of the glyph often served as the sole criterion for classification. To enable computational processing, each glyph was assigned a standardized alphanumeric code composed of a letter followed by a two-digit number. This system, which closely resembles Alan Gardiner’s classification of Egyptian hieroglyphs, was subsequently adapted by scholars such as Martha Macri, Gabrielle Vail, Mathew Looper, and Yuriy Polyukhovich in their own efforts to systematize the Maya script (Figure 13). Their catalogs, published in 2003, 2009, and 2022, expanded upon the earlier approach while encountering similar difficulties. Notably, ambiguity in iconographic interpretation led to inconsistencies in coding, such that identical or closely related signs were sometimes cataloged under multiple, divergent entries. Despite offering a certain degree of flexibility, particularly through the inclusion of placeholder signs and mechanisms for cataloging newly discovered glyphs, the Rendón and Spescha system left several fundamental issues unresolved. These included the lack of a clearly defined classificatory hierarchy, the imprecise treatment of semantic relationships, and the overall difficulty of maintaining consistency across an evolving glyph inventory. The attempt to combine numeric sequencing with iconographic principles often resulted in a degree of classificatory vagueness that persisted in later adaptations of the system.
The most extensive and systematic attempt to catalog Maya hieroglyphs based on iconographic and visual criteria was carried out by Martha Macri. Her project began more than three decades ago and culminated in the release of an online database in 2022. Together with Gabrielle Vail, Mathew Looper, and Yuriy Polyukhovich, Macri developed a digital catalog that not only aimed to document all known graphemes but also to provide a digital framework for future epigraphic research. Between 2003 and 2022, the group published three sign catalogs accompanied by extensive bibliographic resources. Like the earlier work of Rendón and Spescha, their approach rejected a purely numerical ordering of signs. Instead, they employed an alphanumeric system that grouped signs into six semantic categories and eight formal categories, thereby integrating visual and conceptual features into a unified classification. The authors recognized the historical importance of Thompson’s 1962 catalog but also addressed its many shortcomings. In particular, they criticized the redundancy and confusion caused by grouping unrelated signs under a single number, as well as the lack of a coherent classificatory logic. The order of signs in Thompson’s system was often arbitrary and did not reflect meaningful relationships between visually or semantically related glyphs. Furthermore, because Thompson’s catalog was published in print, it lacked the ability to incorporate new findings or respond to changes in the field of Maya epigraphy. In contrast, Macri’s digital project was designed to be extensible and adaptable, allowing it to accommodate ongoing discoveries and scholarly advancements within a flexible, digital infrastructure.
|
a |
b |
c |
| Figure 13. Comparative selection of glyphs from various editions of the New Catalog of Maya Hieroglyphs (2003, 2009, 2022), illustrating the classification system applied to Maya script glyphs. The alphanumeric coding framework, conceptually modeled on Gardiner’s (1957) classification of Egyptian hieroglyphs, organizes signs into major thematic categories such as animals (A), birds (B), body parts (H), hands (M), human figures (P), and supernatural beings (S). Within each category, additional letters and numbers are used to differentiate graphic variants. The plates shown from the 2003 (a), 2009 (b), and 2022 (c) editions exemplify the difficulties involved in the consistent identification and classification of highly variable sign forms. These challenges are reflected in the differing codes and reclassifications assigned to specific graphemes in the 2022 catalog. | ||



A defining feature of the New Catalog of Maya Hieroglyphs, developed by Martha Macri and her collaborators, is its alphanumeric classification system, which draws on Gardiner’s Sign List for Egyptian hieroglyphs (1957) and had already been introduced by Rendón and Spescha in 1965. This model divides Maya script signs into fourteen primary categories, each designated by a letter or numeral. These include, for instance, (A) animals, (B) birds, (H) human body parts, (M) hands, (P) persons, and (S) supernatural beings. Within each main group, signs are further differentiated by a second number that identifies specific types, such as a particular animal or hand gesture. A third digit or additional letter indicates graphic variants, allowing the catalog to register allographic distinctions. The goal of this system is to integrate graphic and functional analysis by grouping signs according to their phonemic or logographic value while also accounting for stylistic differences across time and region. Its structure emphasizes flexibility, making it possible to incorporate new glyphs without disrupting the underlying logic. Despite these methodological ambitions, the practical implementation of the Macri catalog has drawn considerable criticism. Marc Zender (2006) points out that while the alphanumeric system represents a step forward in comparison to earlier models, it suffers from significant inconsistencies. The heterogeneous iconography of many glyphs often warrants their inclusion in multiple semantic groups, yet the catalog fails to convey clear criteria for classification. For example, human faces incorporating solar elements could logically belong to both the “persons” and the “celestial objects” categories. This issue is compounded by the fragmentation of semantically related signs—such as the various “parrot glyphs”—across unrelated sections of the 2003 and 2009 editions. These inconsistencies reveal that semantic and contextual relationships among signs have not been systematically addressed.
An additional structural limitation is the graphic variability of Maya glyphs, which complicates consistent iconographic identification. This problem is exacerbated by the incomplete and sometimes inconsistent categorization of signs within the system. The 2022 revision sought to address these shortcomings, but introduced significant changes to both the coding logic and the underlying taxonomy. These revisions, in turn, created notable discrepancies when compared to the earlier 2003 and 2009 editions, thereby complicating both scholarly comparison and practical usage. One of the most pressing issues is the absence of a concordance across versions, which severely hinders the catalog’s utility in digital environments that depend on stable, transparent identifiers. Taken together, the concerns raised by Zender remain highly relevant. Despite its stated ambition to provide a systematic and improved foundation for the study of Maya writing, the New Catalog of Maya Hieroglyphs continues to fall short due to persistent methodological flaws and unresolved conceptual issues. Its inconsistent classification logic, lack of cross-referencing between versions, speculative interpretations, and taxonomic instability all limit its reliability as a scholarly resource. As a result, Thompson’s 1962 catalog, notwithstanding its acknowledged limitations, remains the most stable and widely used reference in Maya epigraphy. It is for this reason that the present project builds on Thompson’s work, revising and extending his system to meet the needs of current research.
Chapter Summary
The classification of Maya hieroglyphic writing presents a complex array of challenges that are methodological, semantic, and technological in nature. Characterized by an extraordinary diversity of signs and graphic variants—many of which remain only partially deciphered—the Maya script demands a high degree of precision and adaptability in its analysis. While earlier cataloging efforts laid foundational groundwork, they exhibit notable conceptual shortcomings, particularly in the inconsistent application of classificatory principles and the conflation of formal, semantic, and iconographic dimensions. One of the most persistent limitations lies in the traditional dichotomy between so-called "main signs" and "affixes," a distinction that has proven inadequate given that many affixes can function independently or even assume core syntactic roles. Moreover, the rigidity of printed catalogs prevents them from accommodating new discoveries, rectifying misclassifications, or integrating newly identified variants. As a result, key aspects of the script’s visual diversity—its aesthetic range and functional variation—remain underdocumented or altogether obscured. Earlier cataloging models further suffer from a lack of digital infrastructure. The absence of standardized, machine-readable formats hindered interoperability with other epigraphic and linguistic databases, thus limiting the broader integration of these resources within the digital humanities. Iconographic classifications often relied on subjective visual analogies, leading to inconsistencies and interpretive ambiguities. Without a clear conceptual distinction between form, function, and meaning, the internal logic of the script remains difficult to reconstruct. Equally problematic is the lack of concordance among existing catalogs: divergent numbering systems, inconsistent terminologies, and heterogeneous methodological frameworks have complicated comparative analyses and impeded collaborative research.
The Text Database and Dictionary of Classic Mayan (TWKM) addresses these issues through a methodologically rigorous and technologically advanced approach. Central to this initiative is a digital sign catalog that establishes a principled distinction between the graphic form and the linguistic or semantic value of each sign. Its dynamic, modular structure allows for the correction of legacy errors, the integration of new sign data, and the systematic classification of graphic variants across nine distinct categories. This enables a nuanced analysis of the visual and functional dimensions of the Maya script. In addition, TWKM constructs a comprehensive concordance that aligns the systematics of earlier catalogs—most notably Thompson’s 1962 standard—while extending them through the incorporation of recent discoveries. The project deliberately omits exhaustive bibliographic annotations, relying instead on the New Catalog of Maya Hieroglyphs for that purpose. Instead, it cites only those key publications in which decipherments now accepted by the scholarly community were first proposed. By integrating digital technologies with linguistic and semiotic methodologies, and by disseminating its results in an open-access framework, TWKM establishes a new standard in Maya epigraphy. It offers not only a scalable and analytically robust platform for the study of Classic Maya writing but also a critical foundation for rethinking the epistemological and practical tools of hieroglyphic scholarship.
Structure, Functionality, and Use of the Digital Sign Catalog
The present digital sign catalog addresses the longstanding challenges and limitations of earlier classification systems and serves as a central instrument for the systematic documentation, analysis, and presentation of the Maya hieroglyphic script. Drawing on the results of previous scholarship, the catalog integrates existing systems through concordances that preserve and embed historical classifications within a contemporary methodological framework. Rather than replacing earlier approaches, it creates continuity while introducing a fundamentally new conceptual architecture.
At the core of this catalog lies a semiotic distinction between the graph—the concrete visual representation—and the sign—the abstract, semantic (i.e., linguistic) unit. This distinction, implemented within the metadata architecture of the TextGrid virtual research environment (cf. Diehr et al. 2018), allows for a comprehensive representation of both the graphical diversity and the functional spectrum of Maya signs.
A defining feature of the catalog is its deliberate departure from the conventional one-to-one correspondence between visual form and sign code, a convention found in earlier models such as those of Macri, Vail, Looper, and Polyukhovich (2003–2022) or Zimmermann (1956). These traditional catalogs often embedded visual or iconographic information directly within the sign’s code. For instance, in Macri’s system, glyphs identified as animal representations were assigned the code “A” (totaling 369 entries), while Zimmermann grouped similar forms beginning with the number 700 (63 entries). Such rigid and monolithic classification schemes have now been replaced by a more flexible and differentiated methodology.
In contrast, the new digital catalog decouples the graph’s classification from the sign’s semantic identity and coding. The analysis is conducted directly at the graph level, using a system of controlled vocabularies for form-based and iconographic tagging. This allows each graph to be annotated with formal and visual attributes, even when its semantic meaning remains unidentified. Graphs can thus be classified solely on the basis of form—such as sub-graphemic structures or internal compositional features—without prematurely assigning them to a fixed semantic group. Once iconographic interpretations become available, they can be dynamically integrated into the existing classification. This approach enables the identification of clusters of similarity across both formal and semantic dimensions. Rather than drawing strict categorical boundaries, it follows the model of family resemblance as articulated by Ludwig Wittgenstein (1953). According to this concept, elements are related not by a single defining feature but by a constellation of overlapping similarities—much like members of a family who share resemblances without being identical. The flexible establishment of such relational networks offers new avenues for typological and iconographic analysis.
A key innovation of this system lies in its support for multiple parallel classifications of a single graph across several iconographic and formal categories. For example, consider the as-yet undeciphered sign numbered 1546 (Figure 14). Its standard graphical realization (1546st) depicts a bat head that incorporates a solar eye motif and is further distinguished by a “dark-glossy” surface texture. Whereas traditional catalogs would have placed this graph in a single iconographic category, the digital catalog allows simultaneous tagging under “animal,” “bat,” “eye,” “celestial body,” and “dark-glossy.” This multidimensional tagging captures the visual and semantic richness of the sign far more accurately than previous systems.
Notably, the sign code itself remains fixed and independent of the visual appearance of its graph. This separation allows for greater analytical flexibility and avoids the epistemological pitfalls of visual essentialism. By facilitating nuanced distinctions and transitions between related forms and meanings, this dynamic approach enables a more refined understanding of the graphic and semantic complexity of the Maya script.
Ultimately, the digital sign catalog offers more than a technical solution to historical limitations. It represents a paradigm shift in the cataloging and interpretation of hieroglyphic writing. By bridging form and meaning, tradition and innovation, the project contributes not only to the advancement of epigraphic and paleographic research but also opens new cultural-historical perspectives on the communicative and symbolic variability of Maya writing.
|
|
| Figure 14. A cluster of selected parameters for the iconographic description of Grapheme T1546 (Concept: Elisabeth Wagner; Design: Christian Prager, 2014-) |
Signs and Graphs in the Portal
The portal A Digital Catalog of Maya Hieroglyphs offers a powerful digital infrastructure for the systematic retrieval, filtering, and export of detailed information concerning the signs and graphemes of the ancient Maya script. When accessed via classicmayan.org, the platform initially displays the complete and up-to-date inventory of Maya graphemes, accessible through the default view titled “Graph List”. This view is complemented by additional modules, including the “Syllabic Grid” and the “Catalog Concordance,” both of which are designed to facilitate more specialized forms of scholarly engagement and will be addressed in detail below (Figure 15). The default arrangement presents graphemes in ascending numerical order, beginning with the lowest catalog number. However, users may reverse this order using the sorting controls embedded within the main interface. Beyond numerical sorting, the platform supports an array of more sophisticated options that allow for customized navigation through the corpus. These include sorting by phonetic interpretation, iconographic classification, chronological usage—presented either in the original Maya calendrical format or as converted Western dates—and frequency of attestation across the known epigraphic record. Such functionalities enable scholars to generate dynamic, user-defined grapheme inventories tailored to the specific needs of epigraphic, linguistic, or iconographic research. Each grapheme is represented as a tile within a grid layout, combining visual and textual metadata in a standardized format. These tiles include an idealized representation of the attested graphic variants, an unambiguous alphanumeric identifier, and, where available, the phonetic reading that has been assigned through scholarly decipherment. In cases where a sign remains undeciphered, the corresponding interpretation field remains blank. This integrated design allows for both an at-a-glance overview of the script’s complexity and a deeper analytical engagement with individual signs, thereby providing an indispensable tool for researchers working at the intersection of epigraphy, linguistics, iconography, and digital philology.
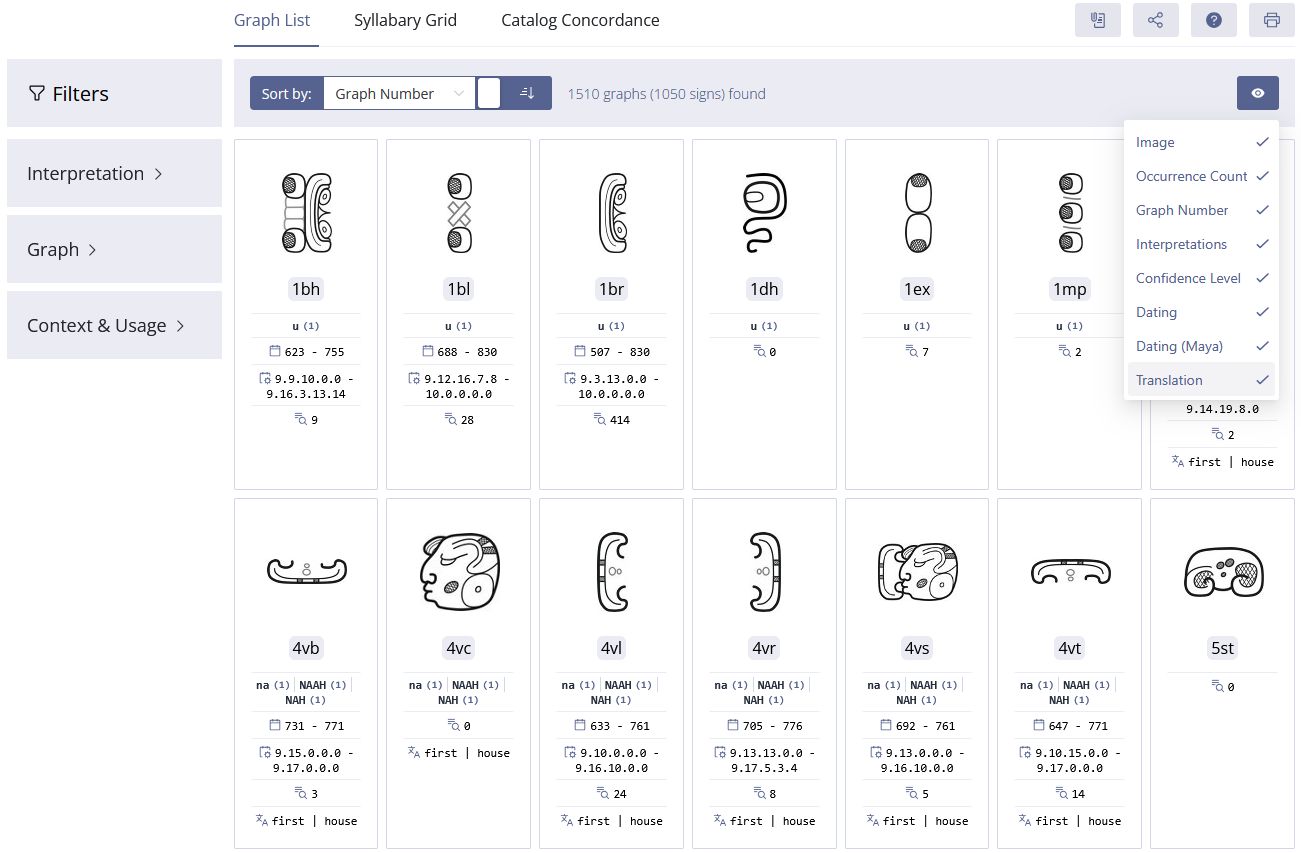 |
| Figure 15. The illustration presents the user interface of the Digital Catalog of Maya Hieroglyphs, displayed in the “Graph List” view. The default layout lists all currently documented Maya graphemes in ascending numerical order. Each tile features an idealized drawing of the grapheme, a unique alphanumeric identifier, phonetic decipherments (interpretations), associated dates, and attestation frequency. Additional metadata can be revealed or hidden via the toggle menu (eye icon). The platform offers a wide range of filtering and sorting functionalities, including options based on iconographic, linguistic, and chronological criteria. Design and implementation: Christian Prager, 2025. |
The portal distinguishes between syllabic signs—rendered, following epigraphic convention, in lowercase bold type—and logograms, which appear in uppercase bold type. It also identifies numeral glyphs and diacritical elements (Stuart 1988) (see Writing and Notation Conventions). Decipherments with the highest degree of certainty (Level 1) are displayed in black, while less secure readings (Level 2 and above) are rendered in red, with their level of certainty indicated in parentheses following the interpretation. This visual differentiation provides users with an immediate understanding of the reliability of each proposed decipherment. Additional metadata can be accessed via a toggle panel, activated through the eye icon located at the right edge of the sorting bar. Defined in Diehr et al. (2019), this panel displays detailed information such as the number of attestations (occurrence count), the level of decipherment certainty (ranging from 1 for high confidence to 8 for minimal plausibility), and the chronological span of each sign’s use, including both earliest and latest attestations. Users can select whether these dates appear in Classic Maya notation or in Western calendrical format. For logograms, the interface also provides the option to display a basic English translation of the semantic root, supporting a deeper understanding of the glyph's meaning. Behind the scenes, a robust technological infrastructure powered by the virtual research environment TextGrid ensures that the catalog remains up to date. A fully automated data pipeline updates the portal’s backend daily, integrating new classifications, decipherments, corrections, or deletions in real time. This dynamic framework allows the sign list to accurately reflect the evolving state of Maya epigraphic research and serves as a continuously reliable resource for scholarly inquiry.
Graph Variants in the Main Interface
The sequence of letters appended to the numerical sign codes in this classification system refers to specific variants of a given graph (Figure 16). These variants are systematically encoded based on morphological features and segmentation principles, as defined by Prager and Gronemeyer (2018) . In our framework, signs are primarily cataloged using a numerical code derived from Thompson’s original classification, while their visual representations are further specified through a standardized two-letter suffix, attached directly to the numeric identifier. Figure 4 provides an overview of the currently documented types of variation. This system enables consistent morphological identification and classification of distinct allographs within a single grapheme set. The letter suffixes encode structural features and variant types. For example, the suffix "st" denotes the standard form of a graph, typically presented in its complete and non-segmentable state. In contrast, "bt" (bottom) and "tt" (top) refer to vertical segments of a graph when it appears in a divided or stacked configuration. More complex variations are also systematically recorded. For instance, "fh" indicates a full-figure human representation—typically an anthropomorphic elaboration of a base graph—while "hc" stands for head creature, used to denote zoomorphic or animate head variants derived from otherwise abstract or ornamental forms. This suffix-based convention allows for the nuanced documentation of graphemic features across a broad range of visual and functional variations. Importantly, this system is not only machine-readable but also essential for integrating graph variants into a scalable digital catalog architecture. It supports consistent and transparent analysis of variant forms, enabling researchers to compare graphical realizations systematically and to trace their position and role within larger glyphic blocks. The addition of the alphanumeric suffix to the core sign code represents a methodological refinement and standardization of earlier efforts by Thompson, Zimmermann, and subsequent scholars to register variation in Maya glyphography. This system offers a robust foundation for the precise documentation of graphemic, morphological, and functional variation, and contributes significantly to the further development of digital sign catalogs. It ultimately enhances our ability to interpret and model the structural complexity of the Maya writing system with a high degree of analytical precision.
 |
 |
| Figure 16. This figure illustrates the systematic classification and encoding of variant forms of individual Maya graphemes in the Digital Catalog of Maya Hieroglyphs. It demonstrates the documentation of allographs through alphanumeric identifiers composed of a primary numerical code (e.g., 630 and 68) followed by a two-letter suffix, like "ta", indicating specific morphological and graphical variants. These suffixes (e.g., “bh,” “bl,” “fh”) capture formal attributes such as segmentation, positional arrangement within glyph blocks, or stylistic transformations such as anthropomorphic heads or full-figure representations. The illustration underscores the diversity of variant formation within a single grapheme type and highlights the methodological significance of this differentiated notation for both epigraphic analysis and digital processing. Users can search and filter directly for these variants within the digital catalog. | |
Transcription and Notation Conventions
The transliteration of Classic Maya inscriptions in the Digital Catalog of Maya Hieroglyphs adheres to a phonetically nuanced orthographic system that systematically represents the consonant and vowel phonemes relevant to Classic Maya. The phonemic inventory includes five vowels (a, e, i, o, u), fifteen basic consonants (b, ch, h, j, k, l, m, n, p, s, t, tz, w, x, y), and five glottalized consonants (ch’, k’, p’, t’, tz’) (see England and Elliott 1990). The voiced glottalized plosive /b’/, occasionally posited in the literature (cf. Wichmann 2004), is not included in this system, as there is currently no conclusive evidence for a phonemic contrast between /b/ and /b’/ in the Classic language (Martin and Grube 2008:12). Typographically, the transcription conventions follow established epigraphic standards (Stuart 1988), which differentiate three primary functional types of signs (Figure 17). Logograms are rendered in uppercase letters during transliteration (e.g., HUL for “to arrive”), while phonetic interpretations are represented in italicized lowercase (e.g., hul “to arrive”). Syllabic signs appear in standard lowercase script (e.g., la). Diacritics, such as reduplication of syllables (e.g., 2ka-wa for [ka]-ka-wa), are superscripted. These typographic conventions facilitate the functional parsing of signs and enhance the legibility of philological transcriptions. In addition, the digital catalog employs a color-coding system to visually signal the degree of philological certainty. Transliterations displayed in black indicate widely accepted readings with high interpretive reliability, whereas red denotes hypothetical or contested interpretations. This approach transparently communicates the epistemic status of individual sign readings and reflects the inherently provisional and evolving nature of Maya epigraphic decipherment.
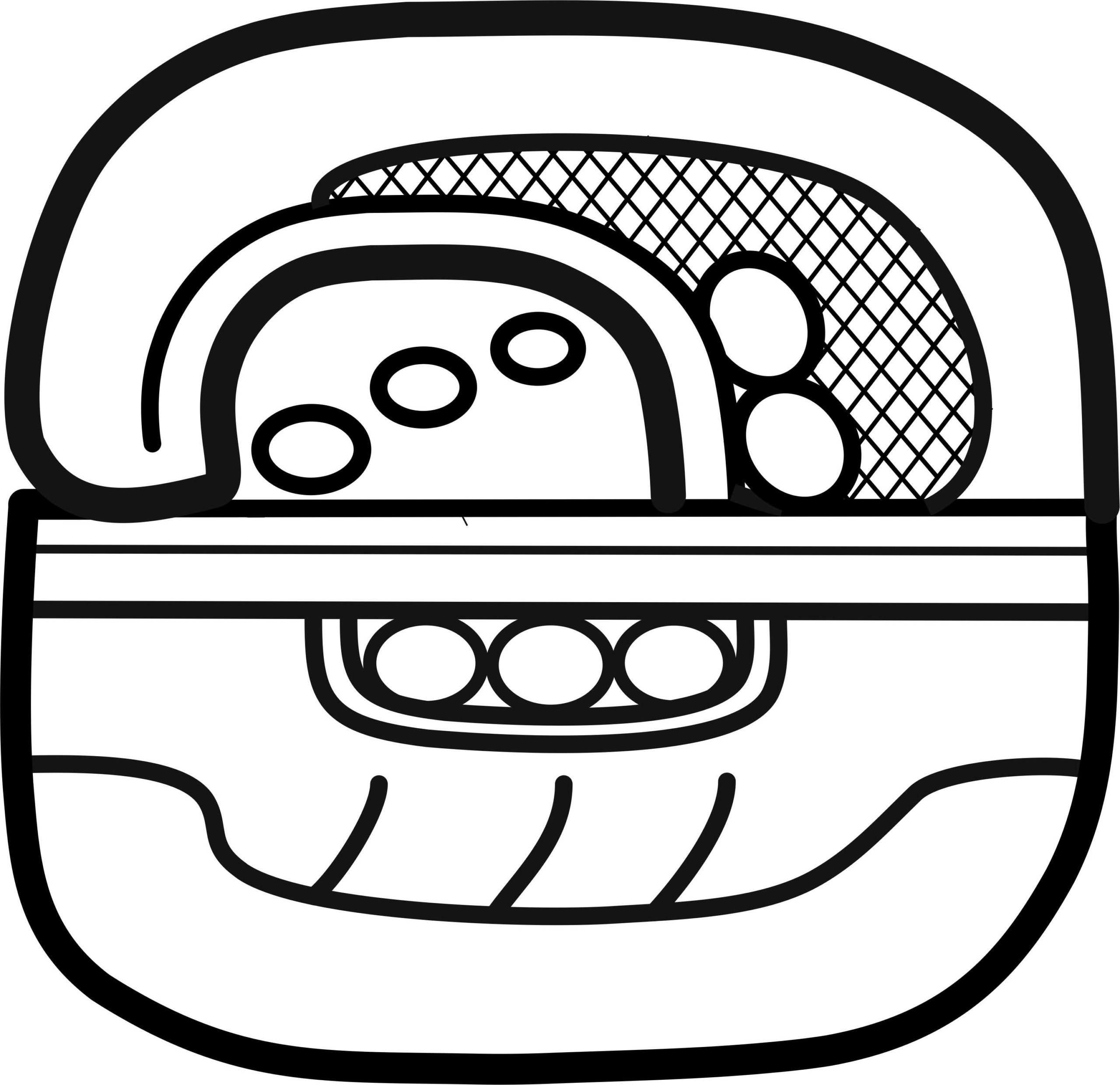 |
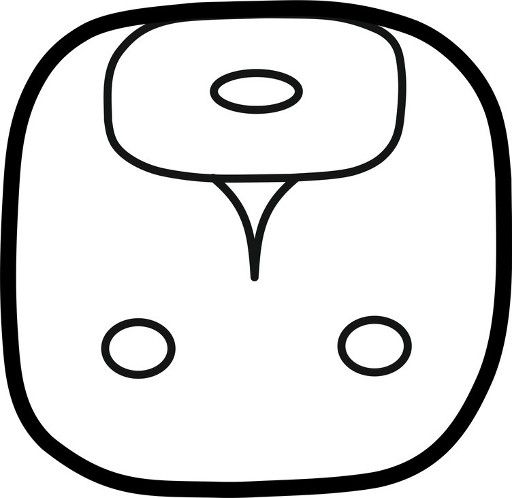 |
 |
| logogram | phonogram | logogram |
| HUL | la | ANTZ |
| hul | antz | |
| "to arrive" | "mother" | |
| Figure 17. Exemplary illustration of typographic differentiation among various sign types in the transcription of Classic Maya inscriptions. Logograms such as HUL (“to arrive”) and ANTZ (“mother”) are rendered in uppercase letters, while their linguistic interpretations appear in italicized lowercase (hul, antz). Uncertain transliterations, such as ANTZ, are marked in red to indicate their hypothetical status. The phonogram la is shown exclusively in lowercase. This convention underscores the functional distinctions among logographic and phonetic signs within the digital catalog and is further complemented by semantic glosses in quotation marks. The figure visualizes key principles of epigraphic notation and demonstrates the systematic visual encoding of graphemes, transcription, and meaning. Concept and design: Christian Prager, 2025. | ||
Classic Maya writing is based on a logosyllabic system whose structure relies primarily on syllabic signs that encode phonetic features either directly or indirectly. Orthographic regularities such as vowel harmony and disharmony play a crucial role in the script's internal logic and phonological representation (Houston et al. 1998; Lacadena García-Gallo and Wichmann 2004). Vowel-harmonic spellings - for example, ch’o-ko for ch’ok “young” or tzu-lu for tzul “dog” - feature matching vowels in successive syllabic signs and typically reflect simple, short vowels. By contrast, vowel-disharmonic spellings such as u-si-ja for usiij “vulture” suggest phonetically complex syllabic nuclei. These may include long vowels (VV), glottalized vowels (Vʼ), or vowels followed by an inserted consonant (Vh). One particularly salient phonological feature is the vowel–/h/–consonant (VhC) structure. In Classic Maya writing, this weak phoneme /h/ is often unrepresented, resulting in spellings that obscure its phonetic presence. Because the script lacked a robust method for indicating consonant clusters, the /h/ segment was regularly omitted in the orthography. A widely cited example is ba-la-ma, which appears graphically as vowel-harmonic but is reconstructed phonetically as bahlam “jaguar.” In such cases, the visual harmony of the syllabic sequence masks the underlying phonological complexity, specifically the presence of an unmarked /h/ in the syllable nucleus. Diachronic evidence for this phonological structure can be found in modern Mayan languages, particularly in Yucatecan, where reflexes of *VhC sequences in Classic Mayan are preserved as high tone. Similar reflexes are attested in Ch’ol, Choltí, and Ch’orti’, which have maintained certain phonological traces of Proto-Mayan *VhC clusters in a number of contexts.
In epigraphic practice, it has therefore become standard to explicitly mark this historically reconstructible but graphically unrepresented /h/ in both transliteration and transcription. Reconstructions such as BAHLAM “jaguar,” TIHL “tapir,” or K’IHNICH “sun god” follow this convention, acknowledging the phonological structure despite its absence in the original inscriptions. The importance of this reconstruction is particularly evident in minimal pairs such as ik’ “wind” and ihk’ “black" (Figure 18). The corresponding graphemes, T503 IK’ “wind” and T95 IK’ “black,” are never used interchangeably in extant inscriptions. This distribution strongly supports a phonemic distinction that, although not reflected in syllabic spellings, is corroborated by semantic opposition, contextual usage, and comparative linguistic data.
 |
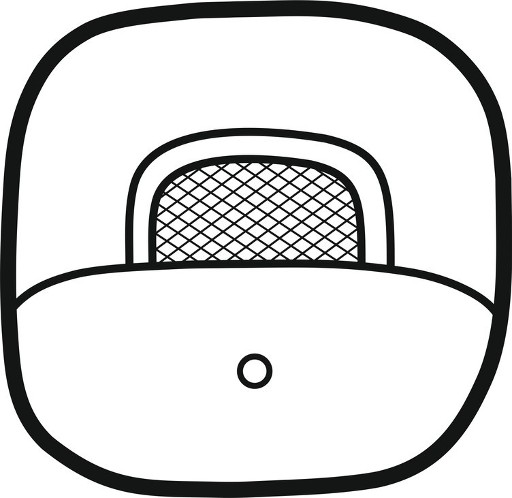 |
| logogram | logogram |
| IK' | IK' |
| ik' | ihk' |
| "wind" | "black" |
| Figure 18. Graphic contrast between the homophonous logograms T503 for IK’ “wind” and T95 for IK’ “black.” While the phonetic realization is identical, the semantic distinction is conveyed through transcription. Concept and design: Christian Prager, 2025. | |
The interpretation of vowel disharmonic spellings remains a topic of ongoing scholarly debate. Houston, Stuart, and Robertson (1998) maintain that such graphemic sequences typically function as orthographic indicators of phonetic complexity, such as vowel length or glottalization, even when the disharmonic vowel itself was not pronounced but instead served as a visual cue within the writing system. Since consensus has yet to be reached regarding how long and glottalized vowels were consistently represented in the script, the transcription conventions adopted in this catalog follow a deliberately conservative approach. Phonetically complex vowels are represented by vowel doubling, as in aa, ee, ii, oo, or uu. Glottalized vowels, by contrast, are omitted from the transcription unless their representation in the glyphic corpus is unequivocal. Glottalization is considered securely attested only when it appears in harmonic syllabic spellings involving vowel doubling. Examples include pa-a for paʼ meaning "cleft," le-e for leʼ meaning "trap," and mo-o for moʼ meaning "parrot." The use of doubled vowels in these cases reflects a pragmatic orthographic strategy that is also consistent with colonial Yukatekan orthographies. These transcriptional conventions reflect a methodological commitment to honoring the structural features of the Maya writing system while avoiding speculative phonological assumptions not firmly supported by the epigraphic record. The guiding principle is a balanced approach that maintains both philological rigor and linguistic caution, thereby providing a reliable and transparent framework for the analysis and documentation of hieroglyphic texts in the digital sign catalog.
Advanced Search and Filtering
Searching and Filtering Signs
 |
| Figure 19. Filter and search functions for the sign and interpretation section. |
The sidebar of the Digital Catalog of Maya Hieroglyphs offers a suite of advanced search and filtering tools, organized into three distinct modules that enable users to sort, retrieve, and visualize hieroglyphic data with precision (see Figure 19). These tools support targeted access to the visual forms (graphs), abstract sign units, and associated linguistic or iconographic metadata within the catalog. The “Interpretation” section allows users to query signs based on their phonetic value via the Reading Value input field. Results matching the exact or approximate linguistic reading are dynamically rendered in the main display area. A secondary toggle, deciphered, provides three options—any (all signs), yes (only deciphered signs), and no (undeciphered signs)—thus enabling focused research on confirmed or uncertain readings and offering an immediate overview of the decipherment status of each graph. The “Sign Class” filter permits the classification of entries by their functional category, including logograms, phonograms, numerals, and diacritics. These selections can be combined to refine the dataset further and allow for a typological overview of the writing system. Crucially, the sidebar also includes a “Confidence Level” slider, which allows users to filter signs by the plausibility of their phonetic interpretation, on a scale from 1 (highest plausibility) to 8 (lowest). This ranking is based on a multi-layered evaluation method combining historical source criticism, linguistic analysis, and epigraphic substitution patterns (see Houston 2001; Zender 2017; Diehr et al. 2019). A foundational reference point is the 1566 manuscript of Diego de Landa, which provides early phonetic interpretations of over three dozen signs. Further support for decipherment hypotheses stems from systematic logographic and allographic substitutions across inscriptions, phonotactic constraints of the Classic Maya language, and cross-linguistic comparisons with Ch’olan and Yukatekan languages. These variables are evaluated for internal syntactic coherence, cross-textual validation, and iconographic plausibility. The plausibility of a decipherment hypothesis is assessed according to a Bayesian framework (Howson and Urbach 2006), wherein prior assumptions are continuously updated based on emerging evidence and contextual consistency. This iterative model enables the transparent comparison and ranking of competing hypotheses. The result is a robust plausibility rating, ranging from level 1 to level 8, that allows scholars to track the interpretive reliability of each proposed reading. Another key component is the “Translation” filter, which allows users to search for the English gloss of individual logograms or to retrieve a comprehensive list of signs with available semantic interpretations. To display translations within the interface, users must activate the translation toggle via the visibility panel (accessed via the eye icon). Once enabled, translations appear beneath the corresponding graphical representation of each logogram, reflecting the current state of scholarly consensus. For researchers wishing to preserve their search queries, the catalog offers a permalink function, which encodes all active filters within the URL. This ensures that the same query can be reproduced or shared for later use. Additionally, users may export filtered results as a PDF file in HTML format for offline consultation. It is important to note, however, that previously saved search links must be manually cleared to avoid unintended results during future sessions.
Within the translation filter and search section, users may conduct targeted queries for the English meanings of individual logograms or retrieve a comprehensive list of all entries for which translations are currently available. To display these translations within the user interface, the translation option must be activated via the toggle menu, accessible through the eye icon. Once enabled, the corresponding English gloss appears directly beneath the graphical representation of each logogram, reflecting the most up-to-date scholarly consensus on its semantic interpretation. For a more refined search, the has translation toggle allows users to filter exclusively for logograms with existing translations. The filtered results are then rendered in the main display area of the portal. Moreover, the system offers the option to preserve complex search configurations through a permanent link (permalink), which encodes the current filter state within the URL. Upon revisiting the link, the saved settings are automatically restored, ensuring seamless continuity in research workflows. Alternatively, filtered datasets can be exported as HTML-based PDF documents for offline reference or citation. Important: To avoid carrying over previously saved filters into new sessions, users must actively delete the stored permalink (see Figure 20). Failure to do so may result in incomplete or unintended search outputs due to residual filter parameters from earlier queries.
 |
| Figure 20. The user is notified when accessing a saved permalink in the digital drawing catalog. The message indicates that the URL contains previously defined filter settings and view options, and it offers the option to reload this configuration. If this option is not deliberately reset, the database query may produce incomplete or unexpected results. |
Searching and Filtering Graphs
 |
| Figure 21. Search and filter functions for graphs. |
A substantial portion of Maya graphemes derive from concrete visual representations and retain recognizable pictorial characteristics. Iconographic analysis is therefore an indispensable tool in the decipherment and interpretation of the script. Because numerous signs reference tangible objects, living beings, or actions, the investigation of their iconic origins often provides insight into their original linguistic meaning (see Figure 6). Moreover, iconographic study enables researchers to trace stylistic developments and visual conventions that have evolved throughout the history of Maya writing. Beyond the identification of individual signs, this approach is particularly valuable for illuminating the interplay between script and the broader visual culture of Maya art. Hieroglyphs are frequently embedded into pictorial compositions as integral components of figures, garments, or ritual objects, thereby functioning simultaneously as linguistic and visual signs. This underscores the dual role of writing among the ancient Maya—not only as a means of recording language but also as a medium for expressing power, mythology, and identity.
The iconological perspective embedded in our sign portal encourages an understanding of Maya texts not merely as linguistic artifacts, but as elements of a broader semiotic system. In this context, a comprehensive descriptive framework has been developed to support the granular iconographic classification of graphemes, building on the results of 150 years of Maya research. Using controlled vocabularies, graphemes are annotated through a tagging system that captures both formal and iconographic properties. These expert-generated annotations allow for the clustering of visually and semantically related forms (see Figure 14). As a result, the sign and graph catalog can be explored, filtered, and sorted according to a wide array of descriptive criteria.
To support this level of analysis, the portal includes a dedicated section under the category "Graph" with a set of specialized filters and query tools (Figure 21). The input field labeled graph number enables users to search for a specific graph by its numerical ID. Searches may be conducted as exact matches or using truncated input. Additionally, a range-based search function allows users to define a numerical interval—for example, all graphs numbered between 50 and 100. The first input field sets the lower boundary, while the second defines the upper limit; all graphemes within that range are displayed. This tool facilitates targeted navigation through the catalog and supports the identification of related or structurally contiguous forms.
An intuitive slider, located above the input fields, permits dynamic adjustment of the search range without the need for manual input. By dragging the sliders left or right, users can modify the parameters quickly and efficiently. This interactive function offers a user-friendly means of locating specific graphemes or groups of graphemes with shared structural features.
In the field labeled variants, users can filter the catalog based on standardized two-letter codes representing segmentation modes. These include, for example, horizontally or vertically segmented graphemes, pars-pro-toto forms, and iconographic transformations such as anthropomorphic, zoomorphic, or full-figure representations. This flexible querying system makes it possible to retrieve and analyze graphemes that share key morphological or visual characteristics, supporting both comparative and typological research.
 |
| Figure 22. Expert mode for iconographic filtering in the Digital Catalog of Maya Hieroglyphs. The hierarchically structured interface enables targeted searches based on the formal and thematic characteristics of individual graphemes. Expandable menus allow users to select specific subcategories - such as animal depictions, body parts, or anthropomorphic transformations facilitating nuanced analysis of iconographic variation. |
A central component of the digital sign catalog is iconographic search functionality, accessed through the iconography input field. This feature enables precise and methodologically grounded querying by combining a hierarchically structured taxonomy with a flexible free-text interface. Users can navigate a controlled vocabulary of iconographic and formal attributes either by typing directly—prompting an alphabetically sorted dropdown—or by utilizing the expert mode, which allows for semantically refined queries based on the internal structure and content of the classification scheme (see Figure 22). The use of logical operators such as "AND" and "OR" further refines searches: "AND" will return only those graphemes that contain all selected features, while "OR" broadens the query to include graphemes matching at least one selected criterion. This taxonomic and semiotic architecture supports the generation of thematically organized graph lists that function independently of the phonetic or linguistic interpretation of the signs. This is particularly valuable for the analysis of graphemes grouped by iconographic or morphological attributes—such as animals, artifacts, or landscape elements—as well as for isolating semiotic markers that encode material properties or conceptual qualifiers (cf. Stone and Zender 2011). For example, visual markers like te’ (wood), tuun (stone), or baak (bone) not only denote physical substances but also visualize abstract categorization schemes within the script. These iconographic features act as visual metadata, enabling systematic exploration of the known corpus according to form, iconography, and referential content. As a result, the organizational logic of the catalog is intentionally decoupled from any fixed order based on phonetic value or visual theme. Instead, its search and filtering functionalities allow researchers to dynamically reorganize and interrogate the data according to their specific analytical frameworks.
Search and Filter of Graphemes in Context
Signs and their graphemes represent the smallest semantically distinctive units within a writing system. They materialize on physical supports that, beyond serving as mere carriers of writing, play a critical role in epigraphic interpretation of cultural and historical contexts. In the case of the Maya script, materials such as stone, ceramic, or bark paper- as well as media-specific techniques like painting or carving - significantly shaped the visual expression, function, and reception of hieroglyphic writing. The archaeological contextualization and epigraphic analysis of these material supports provides essential insight into the spatial and temporal distribution of script. Maya inscriptions, for instance, often contain exact calendrical data, enabling precise chronological attribution and offering clues about the origin, use, and circulation of writing practices. Moreover, such contextual data allow for both synchronic and diachronic tracking of graphemic development. Linking inscriptions to specific sites or historical agents deepens our understanding of past societies by embedding writing within broader social, political, and cultural frameworks. A systematic documentation of these parameters helps answer key questions regarding materiality, calligraphy, and the usage of signs - for instance, identifying which media were preferred, who commissioned or produced the inscriptions, and where they were distributed. These contextual attributes are fully integrated into the catalog’s data model, searchable and visualizable, thus enabling the recognition of patterns in material selection, script usage among social groups, and connections between regional writing traditions.
|
|
| Figure 23. View of the “Context & Usage” filter category within the digital sign catalog, designed to support the targeted analysis of the distribution, materiality, and contextual embedding of Maya graphemes. The user-friendly interface allows for detailed filtering based on inscription media, findspots, artifact types, chronological data, and social associations, for example, by selecting specific sites, inscriptions, time periods, or signs linked to individuals. The visualization tools facilitate the investigation of historical, cultural, and social dimensions of writing practices within the Classic Maya world. |
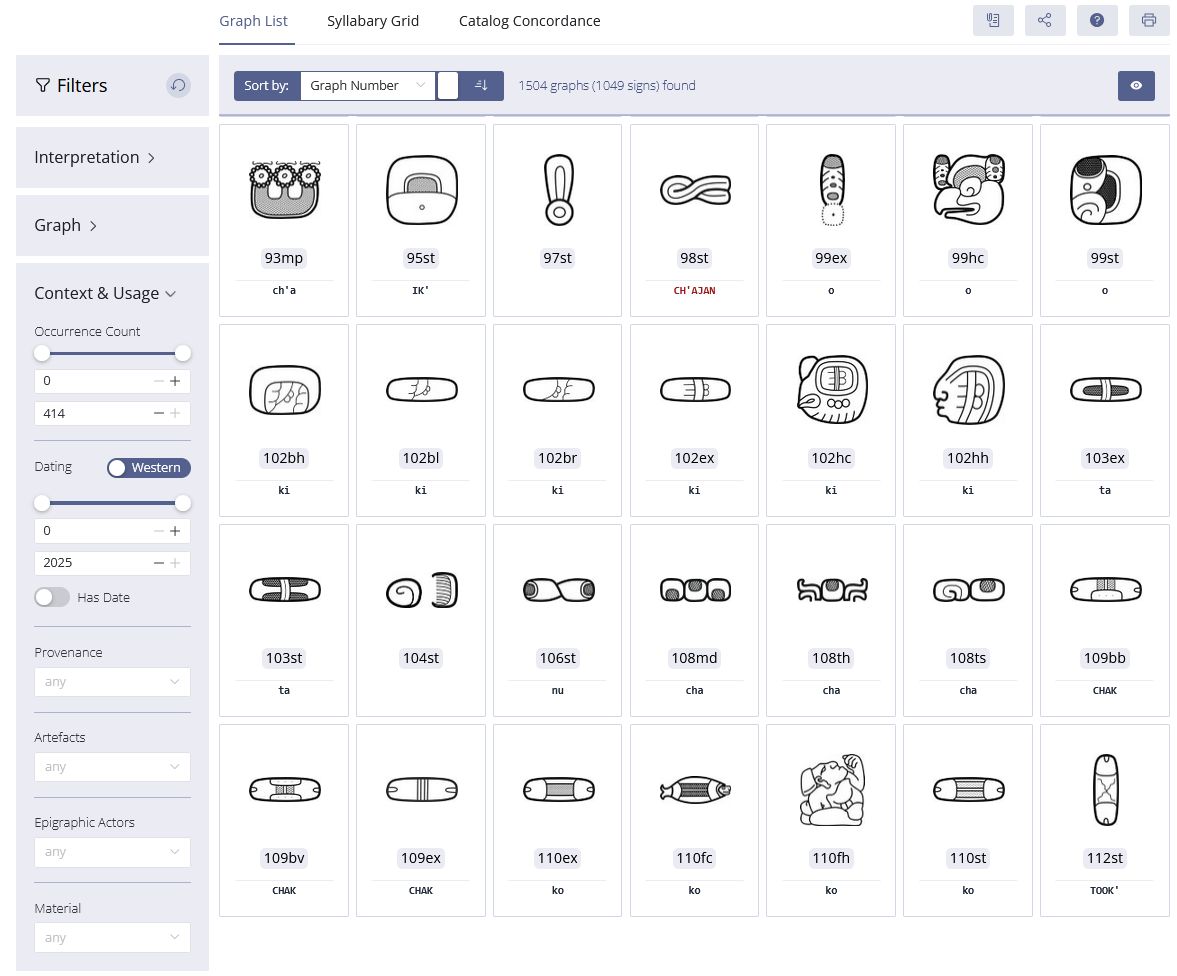
The sign catalog provides advanced analytical tools under the category Context & Usage to explore the material and spatial distribution of Maya hieroglyphic signs (Figure 23). The Occurrence Count function enables users to filter graphemes based on their frequency within the TEI-encoded documents of the project, hosted in the TextGrid digital research environment, which provides inscriptional data in machine-readable format. These analyses offer a systematic overview of the distribution of graphemes across the corpus and allow for the identification of quantitative patterns as well as correlations between writing media, historical periods, and scribal traditions. Temporal distributions of graphemes can be refined through the Dating function, which draws on the documentation of inscription-bearing artifacts within TextGrid. Users may choose between the original Maya calendrical notation and its corresponding Western (Gregorian) equivalent. The chronological range can be adjusted manually by entering specific years or interactively using a range slider. When the Has Date filter is enabled, only inscriptional objects with absolute chronological data are included. Additional filter options allow users to narrow their selection of graphemes based on artifacts, archaeological sites, historical individuals, or materials, thereby facilitating the contextual analysis of inscriptions within specific geographic, social, or material frameworks. The Provenance filter provides a dropdown menu for selecting individual discovery sites, while the Artifact input field supports targeted queries by inscription. This allows for flexible tailoring of sign lists according to excavation contexts or object-specific research. A chronological restriction can be applied via the time filter, while the Persons filter adds a social dimension by retrieving all signs associated with individuals from the ruling elite. If the material nature of the writing medium is of particular interest, users can apply the Material filter to specify different inscriptional substrates—such as stone, ceramics, or bark paper—automatically updating the results in the main display. Through this documentation and analysis of inscriptional media and their associated graphemes, the digital sign catalog not only enables detailed inquiry into the material, social, and historical dimensions of Maya writing but also provides a robust foundation for further epigraphic and cultural-historical research. By combining advanced digital filtering tools, precise chronological metadata, and richly contextualized inscriptional records, the catalog opens new perspectives on the development of writing practices and their social embedding. It renders the complex interrelations between script, medium, and context analytically accessible and methodologically transparent.
Master Record of Signs and Graphs
|
a |
b |
c |
| Figure 24. Example of a master record for Sign 77, featuring registers for graph variants (a), interpretations (b), and bibliographic documentation (c). The master record consolidates linguistic, graphical, and historical information for a given sign, offering detailed data on decipherment, frequency, materiality, and relevant scholarship. It serves as a central analytical tool for the systematic study of Maya hieroglyphic writing. | ||
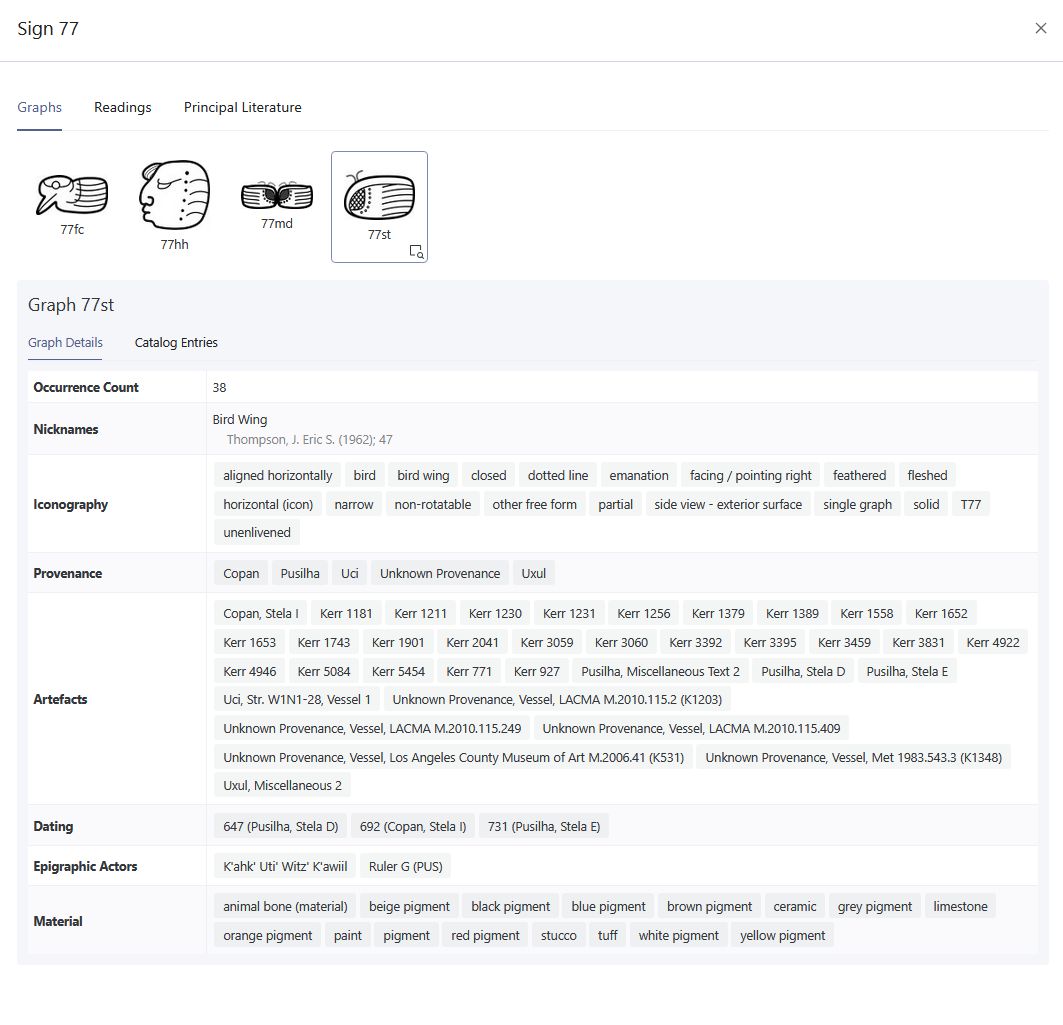
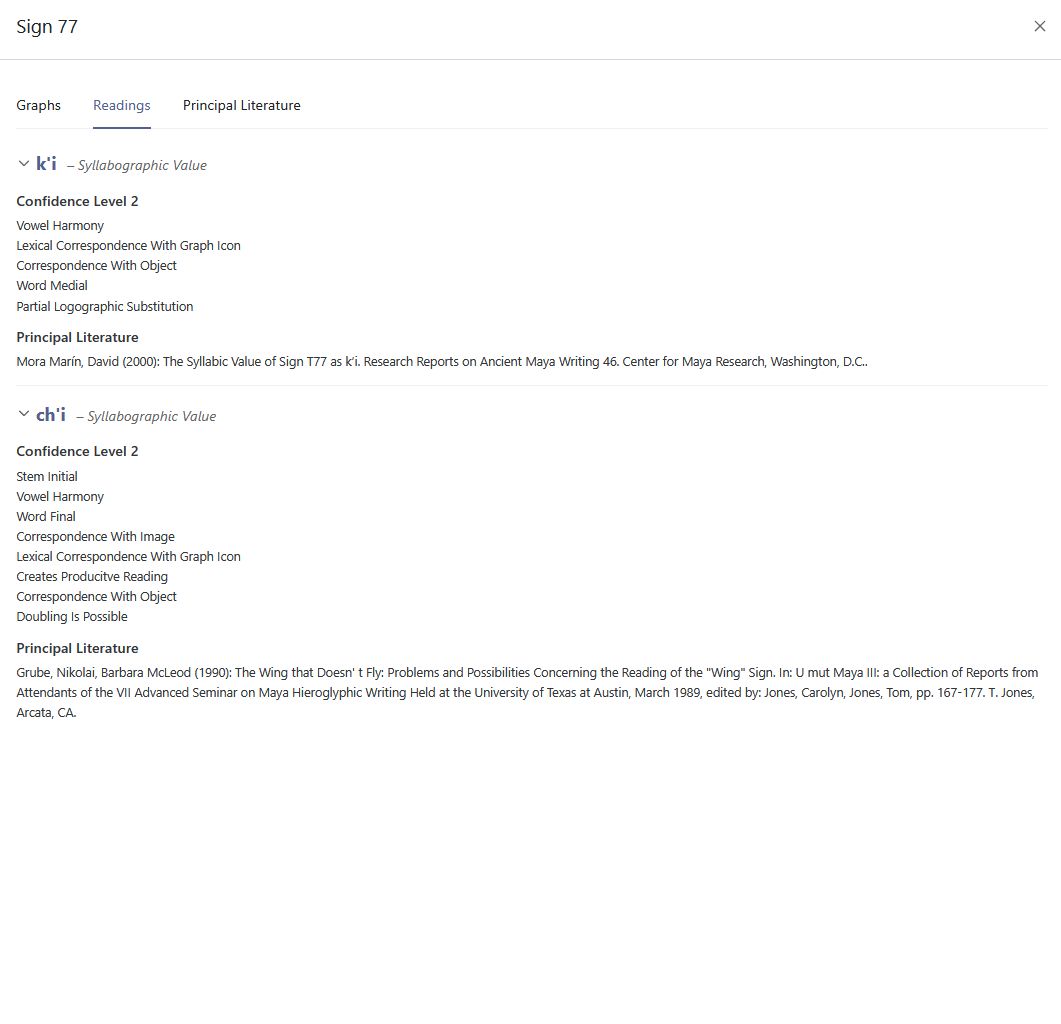
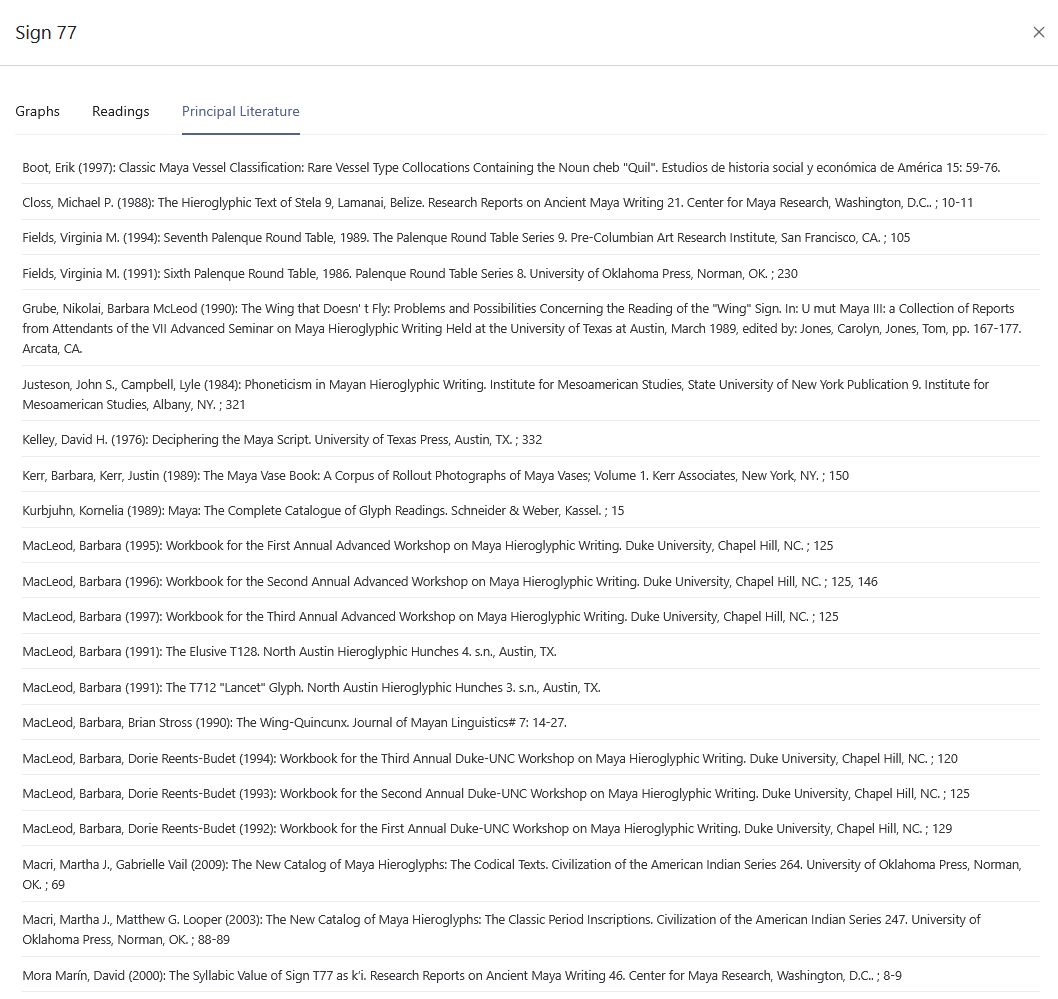
The master record for a Maya sign represents the central instrument for the systematic exploration of Maya writing and serves as the entry point to the entire text database (to be added in a future development) (Figure 24). It consolidates all pertinent information about a sign and its graphical variants and functions as an interface between graphical, epigraphic, and bibliographic analysis. Through the grid view in the main UI, this record is immediately accessible, merging visual representations with linguistic interpretations while simultaneously documenting the historical trajectory of scholarly research. All sign and graph data are captured in standardized formats such as RDF and TEI within the TextGrid virtual research environment and are imported daily via a machine-readable interface. This ensures durable, interoperable, and citable foundations for scholarly work. Structurally, the master record follows a clear two‑tier hierarchy: the sign level defines the abstract entity, while the graph level documents its concrete attested graphical variants. The phonological decipherment—whether as syllabogram, logogram, numeral, or diacritic sign—is elaborated in the Interpretation tab. If available, the Translation tab provides an English rendering of the semantic meaning for logograms. A core element within the Interpretation tab is the Confidence Level, an eight‑step scale that assesses the plausibility of a reading—level 1 denotes a well‑established reading, while level 8 indicates a speculative interpretation (following Diehr et al. 2019). This classification enables a transparent evaluation of reading credibility and forms a robust basis for further analysis, especially in dictionary compilation. In addition to phonological and logographic interpretation, the master record may include detailed notes on orthographic variants and phonological augmentations in the commentary fields. Bibliographic documentation plays a fundamental role: the record lists not only key primary sources under Principal Literature but also traces the historical evolution of decipherment. Distinctions are made between scholars who first proposed a currently accepted reading and those who refined or confirmed it in subsequent work. Investigation into the history of readings often drew upon unpublished materials—letters, grey literature, workshop reports—particularly from the 1980s and 1990s, during which many readings now regarded as authoritative were first proposed.
Crucially, in the Interpretation section, or Reading Value, only contemporary, validated decipherments are included. Earlier readings that have since been discredited or superseded—especially those from ca. 1950 to 1980—are deliberately excluded. Instead, the bibliography refers to comprehensive documentation of those historical readings, notably in the catalogs by Macri, Looper, Vail, and Polyukhovich (2003, 2009) as well as compilations by Justeson and Kurbjuhn, which form a major part of the bibliographic backbone. Thus, the catalog remains both precise and up to date, while the evolution of decipherment can be traced through the cited literature. Linda Quist (1997) is also included, whose indices to workshop volumes published in Texas (such as Texas Notes and Copan Notes) remain an invaluable resource for researchers.
The Graphs section visualizes all attested variants of a sign in a tiled layout, each tile containing an illustration and a unique code. When available, users can toggle between the Graph Details and Catalog Entries views. Clicking a variant opens a detailed record showing occurrences, frequency distribution, iconographic attributes, alternative names, and provenance. Additionally logged are the dating of each graph and all artifacts on which it appears. Associations with historical individuals, especially kings and queens linked to a given artifact, are documented under Persons, and the material—stone, ceramic, or other media—is specified.
The frequency counts displayed for each graph are based on quantitative analysis of all occurrences in the TEI documents. Iconographic descriptions are enriched with interactive tags, facilitating targeted identification and comparison of graphs with identical annotations across the catalog.
A further indispensable component is the Concordance, linking the current catalog to hieroglyph catalogs dating back to 1931. Accessible via the navigation bar under Catalog Concordance or within the master record view under Catalog Entries, this extensive directory—currently exceeding 12,000 entries—provides transparent correspondence between legacy sign codes and the present classification, enabling direct comparison with original illustrations from historical catalogs (Figure 25). By establishing a coherent reference basis, the concordance greatly facilitates palaeographic comparison of variants and fosters scholarly exchange between epigraphic traditions. It allows retrospective analysis of existing classifications while laying the groundwork for new methodological approaches in epigraphic research.
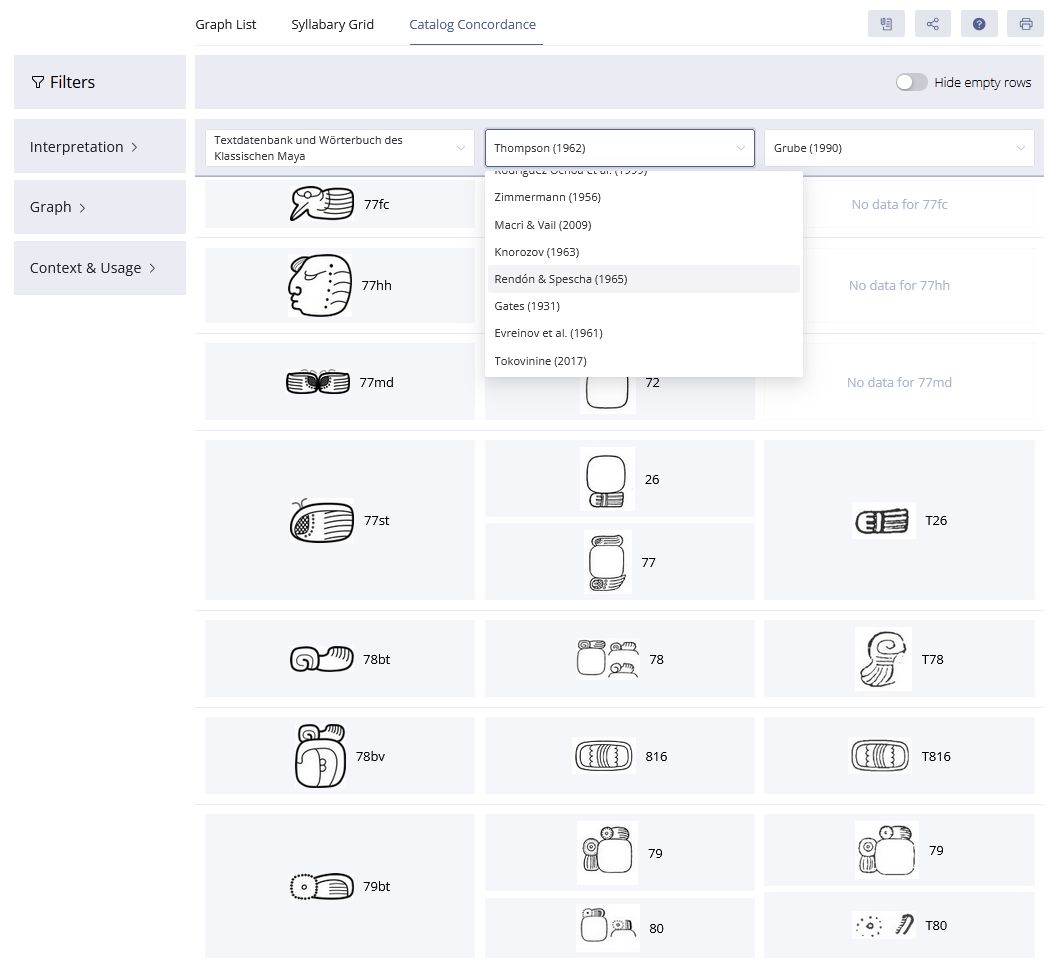 a |
 b b |
| Figure 25. The concordance links the digital sign catalog to previously published catalogs dating back to 1931. It is accessible both via the navigation bar under Catalog Concordance and within the master record view under Catalog Entries. a) Display of a sign alongside its associated historical catalog entries; b) Overview of the same sign’s variants across multiple catalogs, including filtering options for interpretation, graphical appearance, and usage. This systematic comparison facilitates the precise identification of historical developmental stages and establishes a coherent reference framework for comparative classification approaches. In the full view, up to three catalogs can be activated and compared simultaneously. | |
Summary
The digital sign catalog represents an innovative tool for the systematic documentation, analysis, and presentation of the Maya hieroglyphic script. Building on a methodologically refined approach to earlier catalogs, it addresses their limitations through the use of concordances, a precise semiotic distinction between signs and graphs, and a flexible, data-driven structure. A core feature of the system is the clear separation between graphs, which denote concrete visual forms, and signs, which represent meaning-bearing units within the writing system. This differentiation allows for a more accurate recording of the script’s graphic diversity and iconographic complexity. Instead of relying on rigid classification systems, the catalog employs a dynamic tagging method based on controlled vocabularies. This approach enables a flexible, category-independent analysis of signs, making it possible to reveal structural connections and visual affinities that extend beyond conventional models. The digital platform A Digital Catalog of Maya Hieroglyphs (DCMH) facilitates targeted search, filtering, and analysis of hieroglyphic signs and their variants. Its user interface supports intuitive navigation, with the default Grid View displaying numerically ordered tiles of individual signs. These entries are annotated with iconographic descriptors, linguistic readings, and confidence levels ranging from 1 (well-established) to 8 (highly speculative), ensuring transparency and reproducibility. Users may query the catalog based on iconographic elements, phonetic interpretations, or the material characteristics of inscribed artifacts. Another defining feature of the system is its capacity for ongoing integration of new decipherments and systematic revision of prior readings. The continuously updated database incorporates the latest scholarly insights in real time, positioning the catalog not merely as a repository of current knowledge but as an active contributor to the evolving field of Maya epigraphy. Bringing together semiotic, iconographic, and linguistic methodologies, the platform offers a transparent, interdisciplinary resource for both academic research and broader scholarly engagement. Its interoperability with digital analysis tools, combined with open-access availability, ensures that the catalog will serve as a foundational reference within the field of digital epigraphy for years to come.
Scientific Team
The Digital Catalog of Maya Hieroglyphs team is composed of Nikolai Grube, director of the overall project and contributor to the catalog with a focus on epigraphy and metadata; Christian Prager, responsible for project coordination, conceptual design, epigraphy, text annotations, metadata, and visual documentation; Elisabeth Wagner, overseeing controlled vocabularies, iconographic classification, and epigraphy; Guido Krempel, contributing to epigraphy and text annotations; and Antje Grothe, managing metadata and bibliography. The technical infrastructure is developed, programmed, implemented, and maintained by Börge Kiss (Cologne Center of eHumanities), Tobias Mercer, and Moritz Schepp; while Stefan Funk and Ubbo Veentjer from the State University of Göttingen ensured the successful operation of the database on the servers in Göttingen.
In earlier phases of the project, several colleagues contributed significantly to the metadata design, implementation, programming, and ongoing development of the database including data enrichmenet. These include in alphabetical order: Maximilian Behnert-Brodhun (2014–2022, IT infrastructure), Marie Botzet (2019–2024, epigraphy), Katja Diederichs (2014–2022, conceptual design and metadata), Franziska Diehr (2014–2018, conceptual design and metadata structure), Sven Gronemeyer (2014–2020, conceptual design, epigraphy, textual annotations, linguistics, metadata), Maxim Ionov (2022–2024, IT infrastructure), Jana Karsch (2014–2017, epigraphy), Lisa Mannhardt (2015–2020, epigraphy), Niklas Jan Schürmann (2025, epigraphy), and Uwe Sikora (2018, metadata structure).
The project gratefully acknowledges Peter Mathews for generously providing data from his comprehensive Maya Dates project. The monument datings it contains have been incorporated into the sign catalogue and serve, among other things, as an important foundation for the chronological classification of the monuments. Christian Prager expresses his gratitude to Joanne Baron, Simon Martin, Mallory Matsumoto, and Sébastian Matteo for their critical input and valuable contributions to the refinement and enrichment of the text and glyph corpus, and to Alexandre Tokovinine for generously providing his Beginner's Visual Catalog of Maya Hieroglyphs (2017) for use and distribution of his drawings on this platform.
References
Beyer, Hermann
1930 The Infix in Maya Hieroglyphs: Infixes Touching the Frame. Proceedings of the International Congress of Americanists 23:193–199.
1934a The Position of the Affixes in Maya Writing I. Maya Research 1(1):20–29; 101–108.
1934b The Position of the Affixes in Maya Writing II. Maya Research 1(2):101–108.
1936 The Position of the Affixes in Maya Writing III. Maya Research 3(1):102–104.
Borger, Rykle
2010 Mesopotamisches Zeichenlexikon. 2nd revised an updated edition. Alter Orient und Altes Testament 305. Ugarit-Verlag, Münster.
Diehr, Franziska, Maximilian Brodhun, Sven Gronemeyer, Katja Diederichs, Christian M. Prager, Elisabeth Wagner, and Nikolai Grube
2018 Ein digitaler Zeichenkatalog als Organisationssystem für die noch nicht entzifferte Schrift der Klassischen Maya. In Knowledge Organization for Digital Humanities: Proceedings of the 15th Conference on Knowledge Organization WissOrg’17 of the German Chapter of the International Society for Knowledge Organization (ISKO) [30th November - 1st December 2017, Freie Universität Berlin], Christian Wartena, Michael Franke-Maier, and Ernesto de Luca, editors, pp. 37–43. Freie Universität Berlin, Berlin. http://edocs.fu-berlin.de/docs/servlets/MCRFileNodeServlet/FUDOCS_derivate_000000009518/ProcWissOrg2017.pdf.
Diehr, Franziska, Sven Gronemeyer, Christian M. Prager, Katja Diederichs, Nikolai Grube, and Uwe Sikora
2019 Modelling Vagueness – A Criteria-Based System for the Qualitative Assessment of Reading Proposals for the Deciphering of Classic Mayan Hieroglyphs. In Proceedings of the Workshop on Computational Methods in the Humanities 2018, pp. 33–44. CEUR Workshop Proceedings 2314. Université de Lausanne, Lausanne. https://dblp.org/db/conf/comhum/comhum2018.html.
England, Nora C., and Stephen R. Elliott (eds.)
1990 Lecturas sobre la lingüística maya. Centro de Investigaciones Regionales de Mesoamerica, La Antigua Guatemala.
Evreinov, Eduard V., Jurij G. Kosarev, and Valentin A. Ustinov
1961 Primenenie ėlektronnych vyčislitel’nych mašin v issledovanii pis’mennosti drevnych Majja, 1-3. Izdatel’stvo Sirbirskogo Otdelenija AN SSSR, Novosibirsk.
Gardiner, Alan H.
1957 Egyptian Grammar: Being an Introduction to the Study of Hieroglyphs. 3rd edition . Griffith Institute, Oxford.
Gates, William E.
1931 An Outline Dictionary of Maya Glyphs: With a Concordance and Analysis of Their Relationships. Maya Society Publication 1. John Hopkins Press, Baltimore, MD.
Grube, Nikolai
1990 Die Entwicklung der Mayaschrift: Grundlagen zur Erforschung des Wandels der Mayaschrift von der Protoklassik bis zur spanischen Eroberung. Acta Mesoamericana 3. Von Flemming, Berlin.
Houston, Stephen D.
2001 Introduction. In The Decipherment of Ancient Maya Writing, Stephen D. Houston, Oswaldo Chinchilla-Mazariegos, and David Stuart (eds.), pp. 3–19. University of Oklahoma Press, Norman, OK.
Houston, Stephen D., David S. Stuart, and John S. Robertson
1998 Disharmony in Maya Hieroglyphic Writing: Linguistic Change and Continuity in Classic Society. In Anatomía de Una Civilización: Aproximaciones Interdisciplinarias a La Cultura Maya, Andrés Ciudad Ruiz, Yolanda Fernández, José Miguel García Campillo, Josefa Iglesia Ponce de Leon, Alfonso Lacadena García-Gallo, and Luis Sanz Castro (eds.), pp. 275–296. Publicaciones de la Sociedad Española de Estudios Mayas 4. Sociedad Española de Estudios Mayas, Madrid.
Howson, Colin, and Peter Urbach
2006 Scientific Reasoning: The Bayesian Approach. 3rd edition. Open Court, Chicago, IL.
Knorozov, Jurij V.
1963 Pis’mennost indejcev Majja. Izdatel’stvo Akademii Nauk SSSR, Moskva.
Lacadena García-Gallo, Alfonso, and Søren Wichmann
2004 On the Representation of the Glottal Stop in Maya Writing. In The Linguistics of Maya Writing, Søren Wichmann (ed.), pp. 100–164. University of Utah Press, Salt Lake City, UT.
Landa, Diego de
1566 Relación de las cosas de Yucatán / Fray Di[eg]o de Landa: / MDLXVI. Manuscript. Madrid. Biblioteca de la Real Academia de Historia. https://bibliotecadigital.rah.es/es/consulta/registro.do?control=RAH20180001215.
Looper, Matthew, Martha J. Macri, Yuriy Polyukhovich, and Gabrielle Vail
2022 MHD Reference Materials 1: Preliminary Revised Glyph Catalog. Electronic Document. Glyph Dwellers. http://glyphdwellers.com/pdf/R71.pdf.
Macri, Martha J., and Matthew G. Looper
2003 The New Catalog of Maya Hieroglyphs: The Classic Period Inscriptions. Civilization of the American Indian Series 247. University of Oklahoma Press, Norman, OK.
Macri, Martha J., and Gabrielle Vail
2009 The New Catalog of Maya Hieroglyphs: The Codical Texts. Civilization of the American Indian Series 264. University of Oklahoma Press, Norman, OK.
Martin, Simon, and Nikolai Grube
2008 Chronicle of the Maya Kings and Queens: Deciphering the Dynasties of the Ancient Maya. 2nd edition . Thames & Hudson, London.
Peirce, Charles Sanders
1931 Collected Papers of Charles Sanders Peirce. Volume 1- 8. Charles Hartshtorne and Paul Weiss (eds.). Harvard University Press, Cambridge, MA.
Prager, Christian M., Katja Diederichs, Antje Grothe, Nikolai Grube, Guido Krempel, Mallory Matsumoto, Tobias Mercer, Cristina Vertan, and Elisabeth Wagner
2024 IDIOM: A Digital Research Environment for the Documentation and Study of Maya Hieroglyphic Texts and Language. In Writing from Invention to Decipherment, Silvia Ferrara, Barbara Montecchi, and Miguel Valerio (eds.), pp. 227–251. Oxford University Press, Oxford, New York.
Prager, Christian M., and Sven Gronemeyer
2018 Neue Ergebnisse in der Erforschung der Graphemik und Graphetik des Klassischen Maya. In Ägyptologische “Binsen”-Weisheiten III: Formen und Funktionen von Zeichenliste und Paläographie, Svenja A. Gülden, Kyra V. J. van der Moezel, and Ursula Verhoeven-van Elsbergen (eds.), pp. 135–181. Akademie der Wissenschaften und der Literatur, Abhandlungen der Geistes- und sozialwissenschaftlichen Klasse 15. Franz Steiner Verlag, Stuttgart.
Rendón, Juan J., and Amalia Spescha
1965 Nueva clasificación “plástica” de los glifos mayas. Estudios de Cultura Maya 5:189–252. http://www.journals.unam.mx/index.php/ecm/article/view/32884.
Ringle, William M., and Thomas C. Smith-Stark
1996 A Concordance to the Inscriptions of Palenque, Chiapas, Mexico. Middle American Research Institute, Publication 62. Middle American Research Institute, Tulane University, New Orleans, LA.
de Saussure, Ferdinand
1931 Cours de Linguisticque Générale. Payot, Paris.
Schlenther, Ursula
1964 Kritische Bemerkungen zur kybernetischen Entzifferung der Maya-Hieroglyphen. Ethnographisch-Archäologische Zeitschrift 5(5):111–139.
Stone, Andrea, and Marc Zender
2011 Reading Maya Art: A Hieroglyphic Guide to Ancient Maya Painting and Sculpture. Thames & Hudson, New York, NY.
Stuart, George E.
1988 A Guide to the Style and Content of the Series "Research Reports on Ancient Maya Writing". Research Reports on Ancient Maya Writing. Research Reports on Ancient Maya Writing 15. Center for Maya Research, Washington, D.C.
Thompson, J. Eric S.
1962 A Catalog of Maya Hieroglyphs. The Civilization of the American Indian Series 62. University of Oklahoma Press, Norman, OK.
Tokovinine, Alexandre
2017 Beginner’s Visual Catalog of Maya Hieroglyphs. Mesoweb, San Francisco, CA. http://www.mesoweb.com/resources/catalog/Tokovinine_Catalog.pdf.
Wichmann, Søren
2004 The Linguistics of Maya Writing. University of Utah Press, Salt Lake City, UT.
Wittgenstein, Ludwig
1953 Philosophical Investigations. Blackwell, Oxford.
Xǔ, Shèn
1981 Shuowen Jiezi Zhu [說文解字注]. Zhonghua Shuju, Beijing.
Zender, Marc
2006 Review of M. Macri and M. Looper, “The New Catalog of Maya Hieroglyphs: Volume 1: The Classic Period Inscriptions” (University of Oklahoma Press, 2003). Ethnohistory 5(2):439–441.
2017 Theory and Method in Maya Decipherment. The PARI Journal 18(2):1–48. http://www.mesoweb.com/pari/journal/archive/PARI1802.pdf.
Zimmermann, Günter
1956 Die Hieroglyphen der Maya-Handschriften. Abhandlungen aus dem Gebiet der Auslandskunde. Reihe B, Völkerkunde, Kunstgeschichte und Sprachen 62. Cram, de Gruyter, Hamburg.
Suggested Citation
Database:
Textdatenbank und Wörterbuch des Klassischen Maya (TWKM)
2014–present. A Digital Catalog of Maya Hieroglyphs [Online database]. Project directed by Nikolai Grube. Principal development, editing and coordination by Christian Prager. Edited by Elisabeth Wagner, Guido Krempel, Antje Grothe, Börge Kiss, Tobias Mercer, and Moritz Schepp. With earlier contributions by Maximilian Behnert-Brodhun, Marie Botzet, Katja Diederichs, Franziska Diehr, Sven Gronemeyer, Maxim Ionov, Jana Karsch, and Lisa Mannhardt. Funded by the North Rhine-Westphalian Academy of Sciences, Humanities and the Arts, Düsseldorf. Online: https://classicmayan.org/signcatalog. Bonn: Rheinische Friedrich-Wilhelms-Universität Bonn, Department of the Anthropology of the Americas. [Accessed: DATE].
Sign Catalog Drawings:
Drawings by Christian Prager (2014–present), licensed under CC BY 4.0. Text Database and Dictionary of Classic Mayan, University of Bonn. Available at: https://classicmayan.org
Legal Notice on the Use of the Maya Hieroglyphic Sign Catalog
Open Access and General Usage
The Digital Catalog of Maya Hieroglyphs is an open-access initiative. It is freely available for scholarly use as well as public access. However, users must observe the applicable copyright, licensing, and legal conditions governing the use of included drawings, images, and photographs.
Copyright and Licensing
Standardized drawings of all graphemes by Christian Prager (CC BY 4.0): All drawings created by Christian Prager included in the catalog are licensed under the Creative Commons Attribution 4.0 International License (CC BY 4.0). This license allows for the use, reproduction, adaptation, and distribution of the drawings, provided that proper credit is given to Christian Prager (Database and Dictionary of Classic Mayan) and that a reference to the CC BY 4.0 license is included. Images from external publications: Images in the catalog also originate from third-party publications. These images are protected by copyright and not covered by open licenses. Their inclusion in this catalog is limited to scholarly purposes under § 51 of the German UrhG (quotation for scientific purposes) and has been explicitly authorized by the respective rights holders. Redistribution, reproduction, or any use of these images outside the context of this project is strictly prohibited unless prior written permission has been obtained from the copyright holders. Additional Content and User Responsibility: The catalog may include other third-party content that is also subject to copyright or licensing restrictions (unless otherwise indicated). Users are therefore required to verify the applicable usage and licensing terms before reusing any content. If permissions are required, they must be obtained independently by the user.
Disclaimer of Liability
Catalog Content: The catalog administrators (project leads at the University of Bonn) strive to ensure the accuracy, completeness, and reliability of the information provided. However, errors or ambiguities cannot be entirely ruled out. No guarantees are made regarding the factual correctness or completeness of the content. Liability claims against the administrators for material or non-material damages arising from the use or non-use of the information provided are excluded, unless such damages result from proven intentional or grossly negligent conduct. External Links: This catalog contains links to external websites. At the time of linking, these sites were free from illegal content. The administrators have no control over the current or future content of those external sites and do not adopt them as their own. Ongoing monitoring of linked sites is unreasonable without specific indications of legal violations. The administrators therefore disclaim any liability for external content. The respective provider or operator of the linked site is solely responsible for any illegal, erroneous, or incomplete content. If unlawful content becomes known, the corresponding link will be promptly removed.
Academic Use and Third-Party Rights
Unless otherwise specified, all content in the catalog is intended primarily for academic purposes, including research, teaching, and scholarly documentation. Third-party copyrighted images are used strictly within the scope of permitted scholarly quotation under § 51 UrhG or U.S. Fair Use, and are always accompanied by appropriate citations. The project strives to respect the rights of third parties (including copyright and privacy rights) and does not publish images of identifiable individuals without explicit authorization. Notice of Rights Violations: If users become aware of potential legal violations (e.g., copyright infringement or violations of personality rights) related to the content of this catalog, we kindly request that you notify us. The administrators will promptly investigate the reported issue and, where necessary, remove or correct the content in question without delay. Use at Your Own Risk: Use of the content provided in the catalog is at the sole responsibility of the user. Beyond the limitations of liability described above, the administrators accept no responsibility for how the information is applied or interpreted. In case of uncertainty regarding the legality of reuse, users are strongly advised to seek legal counsel before proceeding.
Contact and Impressum
For questions regarding content usage or clarification of copyright matters, please contact the responsible project leads:
Prof. Dr. Nikolai Grube – Project Director
Institute for Archaeology and Cultural Anthropology
Department of the Anthropology of the Americas
University of Bonn
Dr. Christian Prager - Coordination
Institute for Archaeology and Cultural Anthropology
Department of the Anthropology of the Americas
University of Bonn
Address: Oxfordstraße 15, 53111 Bonn, Germany
Hosting: The technical infrastructure of the platform is generously supported by the Lower Saxony State and University Library Göttingen (SUB Göttingen) and the GWDG (Gesellschaft für Wissenschaftliche Datenverarbeitung Göttingen).
By using this catalog, you agree to comply with the usage conditions outlined above.
- Copies from the estate of Thomas Barthel, who had in turn incorporated materials from the estate of Eric Thompson, were generously made available by Prof. Dr. Roland Hardenberg (Goethe University Frankfurt, formerly Department of Ethnology, University of Tübingen).
- Bars-and-dots notation.
- Portrait hieroglyphs.
- Not included in the sign list but referenced in the accompanying concordance.
- Not included in the sign list but referenced in the introduction.
- It remains unclear whether the relationship between image and sound is of an iconic or semantic nature.
- Phonetic value unknown; the graphic form of the sign has been identified.
- Neither the phonetic value nor the graphic form of the sign is currently identified.